 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Spoof Disentanglement Generation for Face Anti-spoofing with Depth Uncertainty Learning
Dec 01, 2021

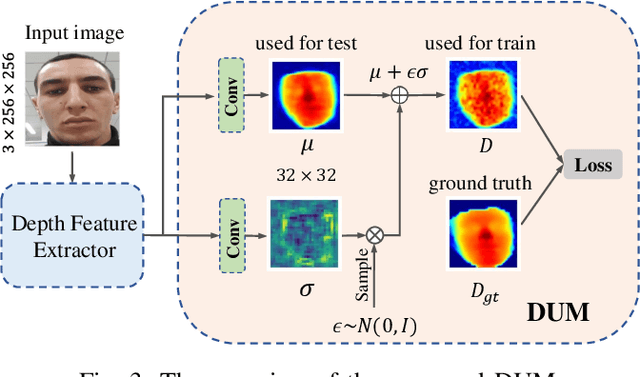

Face anti-spoofing (FAS) plays a vital role in preventing face recognition systems from presentation attacks. Existing face anti-spoofing datasets lack diversity due to the insufficient identity and insignificant variance, which limits the generalization ability of FAS model. In this paper, we propose Dual Spoof Disentanglement Generation (DSDG) framework to tackle this challenge by "anti-spoofing via generation". Depending on the interpretable factorized latent disentanglement in Variational Autoencoder (VAE), DSDG learns a joint distribution of the identity representation and the spoofing pattern representation in the latent space. Then, large-scale paired live and spoofing images can be generated from random noise to boost the diversity of the training set. However, some generated face images are partially distorted due to the inherent defect of VAE. Such noisy samples are hard to predict precise depth values, thus may obstruct the widely-used depth supervised optimization. To tackle this issue, we further introduce a lightweight Depth Uncertainty Module (DUM), which alleviates the adverse effects of noisy samples by depth uncertainty learning. DUM is developed without extra-dependency, thus can be flexibly integrated with any depth supervised network for face anti-spoofing. We evaluate the effectiveness of the proposed method on five popular benchmarks and achieve state-of-the-art results under both intra- and inter- test settings. The codes are available at https://github.com/JDAI-CV/FaceX-Zoo/tree/main/addition_module/DSDG.