 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Face Anti-Spoofing Based on Central Difference Networks
Paper and Code
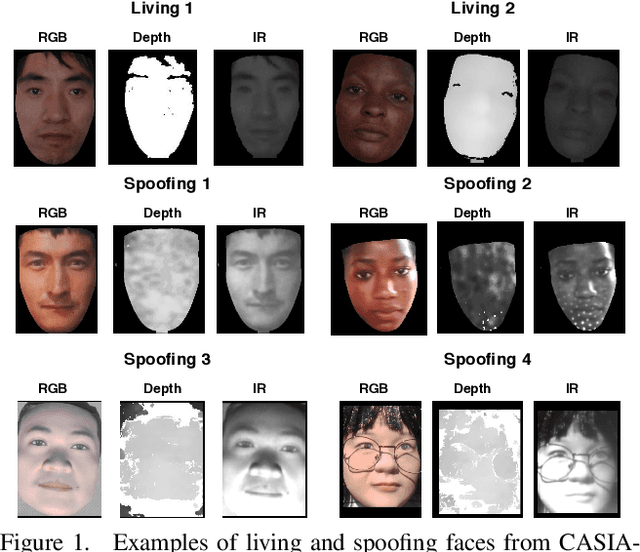
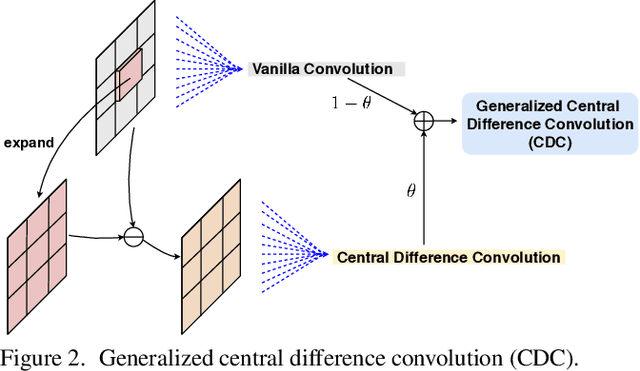
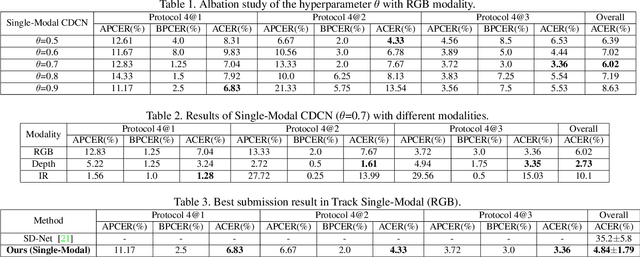
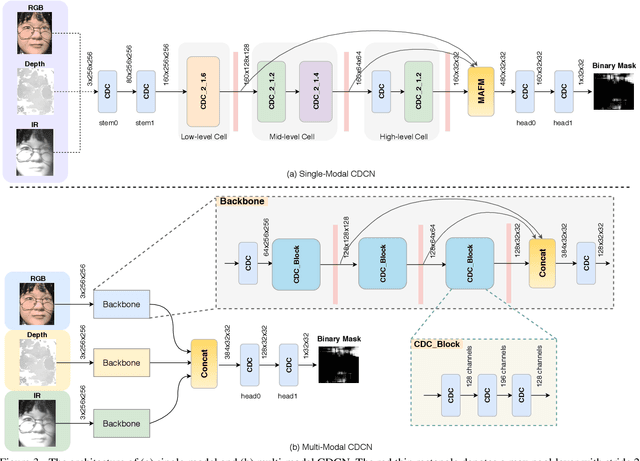
Face anti-spoofing (FAS) plays a vital role in securing face recognition systems from presentation attacks. Existing multi-modal FAS methods rely on stacked vanilla convolutions, which is weak in describing detailed intrinsic information from modalities and easily being ineffective when the domain shifts (e.g., cross attack and cross ethnicity). In this paper, we extend the central difference convolutional networks (CDCN) \cite{yu2020searching} to a multi-modal version, intending to capture intrinsic spoofing patterns among three modalities (RGB, depth and infrared). Meanwhile, we also give an elaborate study about single-modal based CDCN. Our approach won the first place in "Track Multi-Modal" as well as the second place in "Track Single-Modal (RGB)" of ChaLearn Face Anti-spoofing Attack Detection Challenge@CVPR2020 \cite{liu2020cross}. Our final submission obtains 1.02$\pm$0.59\% and 4.84$\pm$1.79\% ACER in "Track Multi-Modal" and "Track Single-Modal (RGB)", respectively. The codes are available at{https://github.com/ZitongYu/CDCN}.