 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Reflection-Augmented Autoencoder Network for Recommender Systems
Jan 10, 2022



As the deep learning techniques have expanded to real-world recommendation tasks, many deep neural network based Collaborative Filtering (CF) models have been developed to project user-item interactions into latent feature space, based on various neural architectures, such as multi-layer perceptron, auto-encoder and graph neural networks. However, the majority of existing collaborative filtering systems are not well designed to handle missing data. Particularly, in order to inject the negative signals in the training phase, these solutions largely rely on negative sampling from unobserved user-item interactions and simply treating them as negative instances, which brings the recommendation performance degradation. To address the issues, we develop a Collaborative Reflection-Augmented Autoencoder Network (CRANet), that is capable of exploring transferable knowledge from observed and unobserved user-item interactions. The network architecture of CRANet is formed of an integrative structure with a reflective receptor network and an information fusion autoencoder module, which endows our recommendation framework with the ability of encoding implicit user's pairwise preference on both interacted and non-interacted items. Additionally, a parametric regularization-based tied-weight scheme is designed to perform robust joint training of the two-stage CRANet model. We finally experimentally validate CRANet on four diverse benchmark datasets corresponding to two recommendation tasks, to show that debiasing the negative signals of user-item interactions improves the performance as compared to various state-of-the-art recommendation techniques. Our source code is available at https://github.com/akaxlh/CRANet.
Layer-Wise Adaptive Updating for Few-Shot Image Classification
Jul 16, 2020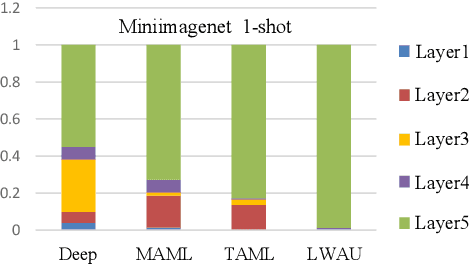
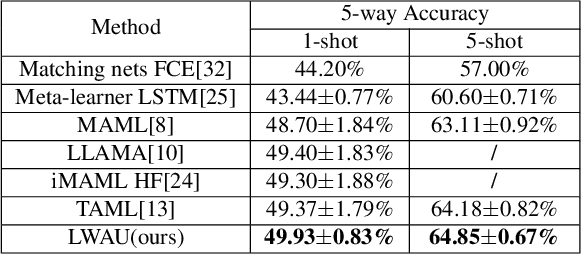

Few-shot image classification (FSIC), which requires a model to recognize new categories via learning from few images of these categories, has attracted lots of attention. Recently, meta-learning based methods have been shown as a promising direction for FSIC. Commonly, they train a meta-learner (meta-learning model) to learn easy fine-tuning weight, and when solving an FSIC task, the meta-learner efficiently fine-tunes itself to a task-specific model by updating itself on few images of the task. In this paper, we propose a novel meta-learning based layer-wise adaptive updating (LWAU) method for FSIC. LWAU is inspired by an interesting finding that compared with common deep models, the meta-learner pays much more attention to update its top layer when learning from few images. According to this finding, we assume that the meta-learner may greatly prefer updating its top layer to updating its bottom layers for better FSIC performance. Therefore, in LWAU, the meta-learner is trained to learn not only the easy fine-tuning model but also its favorite layer-wise adaptive updating rule to improve its learning efficiency. Extensive experiments show that with the layer-wise adaptive updating rule, the proposed LWAU: 1) outperforms existing few-shot classification methods with a clear margin; 2) learns from few images more efficiently by at least 5 times than existing meta-learners when solving FSIC.
Rethink and Redesign Meta learning
Dec 24, 2018
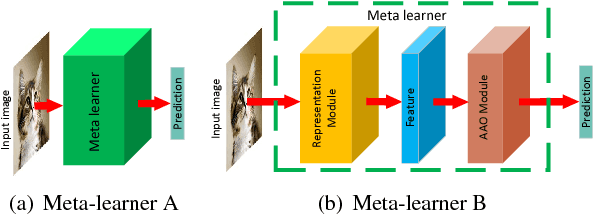
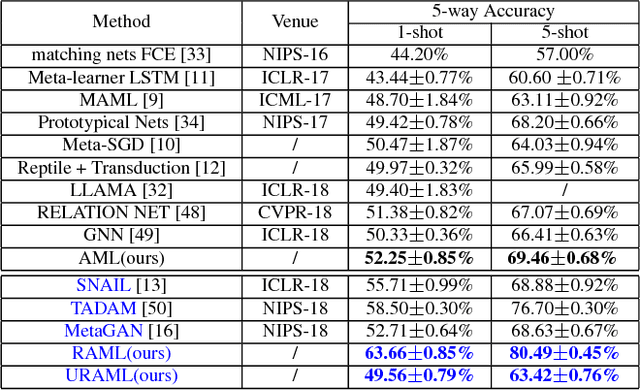
Recently, meta-learning has shown as a promising way to improve the ability to learn from few-data for many computer vision tasks. However, existing meta-learning approaches still fall behind human greatly, and like many deep learning algorithms, they also suffer from overfitting. We named this problem as Task-Over-Fitting (TOF) problem that the meta-learner over-fits to the training tasks, not to the training data. We human beings can learn from few-data, mainly due to that we are so smart to leverage past knowledge to understand the images of new categories rapidly. Furthermore, be benefiting from our flexible attention mechanism, we can accurately extract and select key features from images and further solve few-shot learning tasks with excellent performance. In this paper, we rethink the meta-learning algorithm and find that existing meta-learning approaches miss considering attention mechanism and past knowledge. To this end, we present a novel paradigm of meta-learning approach with three developments to introduce attention mechanism and past knowledge step by step. In this way, we can narrow the problem space and improve the performance of meta-learning, and the TOF problem can also be significantly reduced. Extensive experiments demonstrate the effectiveness of our designation and methods with state-of-the-art performance not only on several few-shot learning benchmarks but also on the Cross-Entropy across Tasks (CET) metric.