 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Complementary Dynamic Convolution for Image Recognition
Nov 11, 2022As a powerful engine, vanilla convolution has promoted huge breakthroughs in various computer tasks. However, it often suffers from sample and content agnostic problems, which limits the representation capacities of the convolutional neural networks (CNNs). In this paper, we for the first time model the scene features as a combination of the local spatial-adaptive parts owned by the individual and the global shift-invariant parts shared to all individuals, and then propose a novel two-branch dual complementary dynamic convolution (DCDC) operator to flexibly deal with these two types of features. The DCDC operator overcomes the limitations of vanilla convolution and most existing dynamic convolutions who capture only spatial-adaptive features, and thus markedly boosts the representation capacities of CNNs. Experiments show that the DCDC operator based ResNets (DCDC-ResNets) significantly outperform vanilla ResNets and most state-of-the-art dynamic convolutional networks on image classification, as well as downstream tasks including object detection, instance and panoptic segmentation tasks, while with lower FLOPs and parameters.
Meta-Teacher For Face Anti-Spoofing
Nov 12, 2021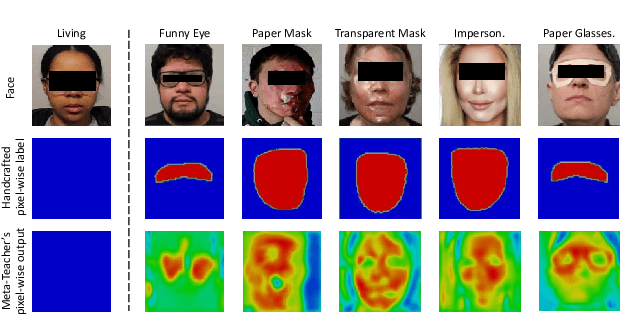
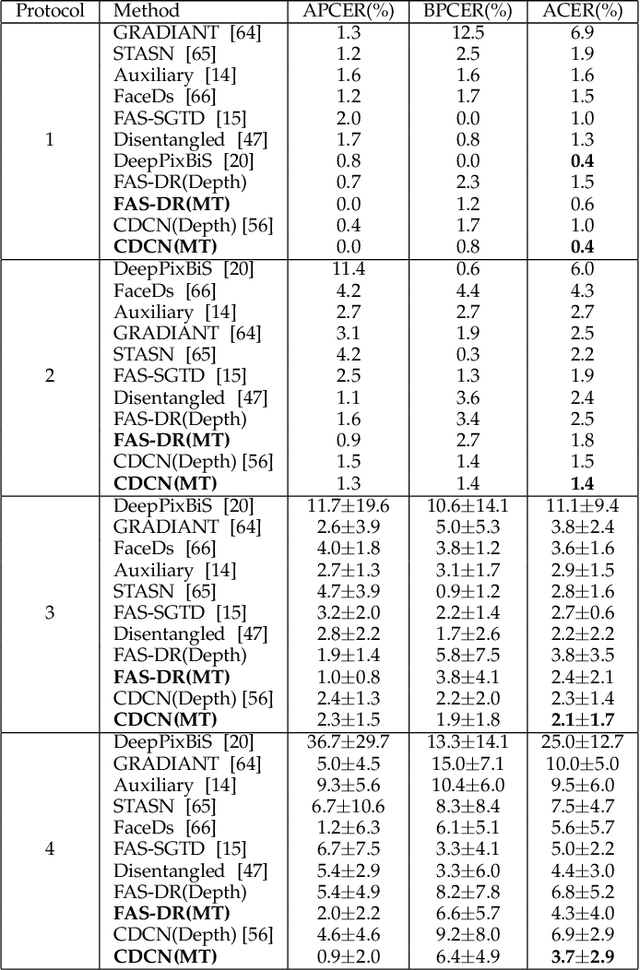
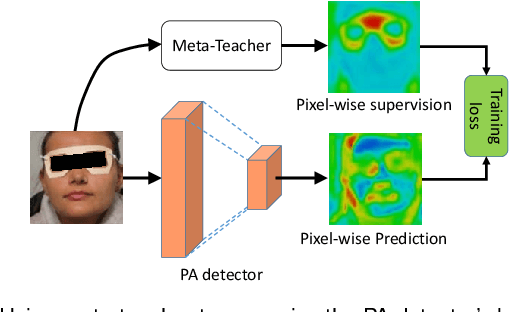
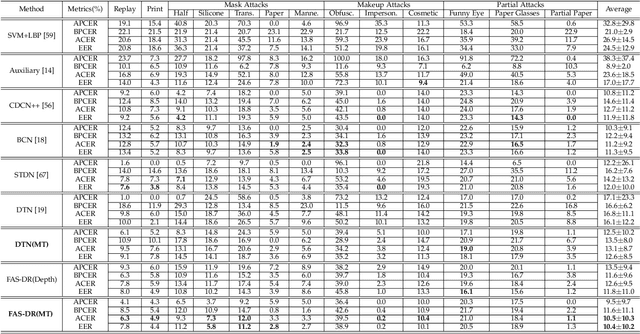
Face anti-spoofing (FAS) secures face recognition from presentation attacks (PAs). Existing FAS methods usually supervise PA detectors with handcrafted binary or pixel-wise labels. However, handcrafted labels may are not the most adequate way to supervise PA detectors learning sufficient and intrinsic spoofing cues. Instead of using the handcrafted labels, we propose a novel Meta-Teacher FAS (MT-FAS) method to train a meta-teacher for supervising PA detectors more effectively. The meta-teacher is trained in a bi-level optimization manner to learn the ability to supervise the PA detectors learning rich spoofing cues. The bi-level optimization contains two key components: 1) a lower-level training in which the meta-teacher supervises the detector's learning process on the training set; and 2) a higher-level training in which the meta-teacher's teaching performance is optimized by minimizing the detector's validation loss. Our meta-teacher differs significantly from existing teacher-student models because the meta-teacher is explicitly trained for better teaching the detector (student), whereas existing teachers are trained for outstanding accuracy neglecting teaching ability. Extensive experiments on five FAS benchmarks show that with the proposed MT-FAS, the trained meta-teacher 1) provides better-suited supervision than both handcrafted labels and existing teacher-student models; and 2) significantly improves the performances of PA detectors.