 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttGAN: Facial Attribute Editing by Only Changing What You Want
Paper and Code

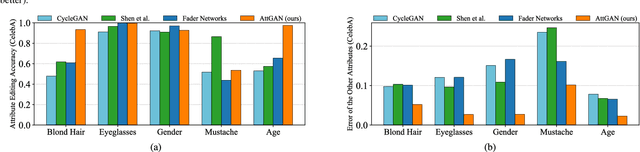
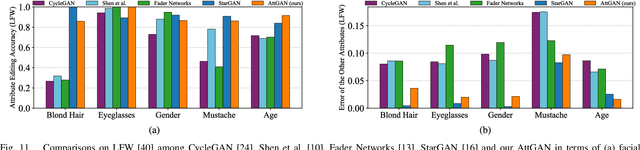

Facial attribute editing aims to manipulate single or multiple attributes of a face image, i.e., to generate a new face with desired attributes while preserving other details. Recently, generative adversarial net (GAN) and encoder-decoder architecture are usually incorporated to handle this task with promising results. Based on the encoder-decoder architecture, facial attribute editing is achieved by decoding the latent representation of the given face conditioned on the desired attributes. Some existing methods attempt to establish an attribute-independent latent representation for further attribute editing. However, such attribute-independent constraint on the latent representation is excessive because it restricts the capacity of the latent representation and may result in information loss, leading to over-smooth and distorted generation. Instead of imposing constraints on the latent representation, in this work we apply an attribute classification constraint to the generated image to just guarantee the correct change of desired attributes, i.e., to "change what you want". Meanwhile, the reconstruction learning is introduced to preserve attribute-excluding details, in other words, to "only change what you want". Besides, the adversarial learning is employed for visually realistic editing. These three components cooperate with each other forming an effective framework for high quality facial attribute editing, referred as AttGAN. Furthermore, our method is also directly applicable for attribute intensity control and can be naturally extended for attribute style manipulation. Experiments on CelebA dataset show that our method outperforms the state-of-the-arts on realistic attribute editing with facial details well preserved.