 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMean Teacher based SSL Framework for Indoor Localization Using Wi-Fi RSSI Fingerprinting
Jul 18, 2024Wi-Fi fingerprinting is widely applied for indoor localization due to the widespread availability of Wi-Fi devices. However, traditional methods are not ideal for multi-building and multi-floor environments due to the scalability issues. Therefore, more and more researchers have employed deep learning techniques to enable scalable indoor localization. This paper introduces a novel semi-supervised learning framework for neural networks based on wireless access point selection, noise injection, and Mean Teacher model, which leverages unlabeled fingerprints to enhance localization performance. The proposed framework can manage hybrid in/outsourcing and voluntarily contributed databases and continually expand the fingerprint database with newly submitted unlabeled fingerprints during service. The viability of the proposed framework was examined using two established deep-learning models with the UJIIndoorLoc database. The experimental results suggest that the proposed framework significantly improves localization performance compared to the supervised learning-based approach in terms of floor-level coordinate estimation using EvAAL metric. It shows enhancements up to 10.99% and 8.98% in the former scenario and 4.25% and 9.35% in the latter, respectively with additional studies highlight the importance of the essential components of the proposed framework.
Hierarchical Stage-Wise Training of Linked Deep Neural Networks for Multi-Building and Multi-Floor Indoor Localization Based on Wi-Fi RSSI Fingerprinting
Jul 18, 2024
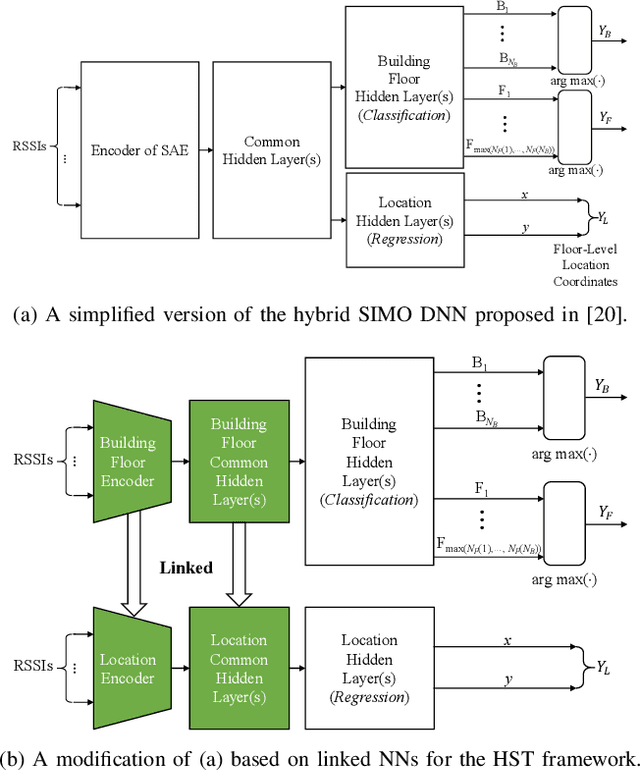
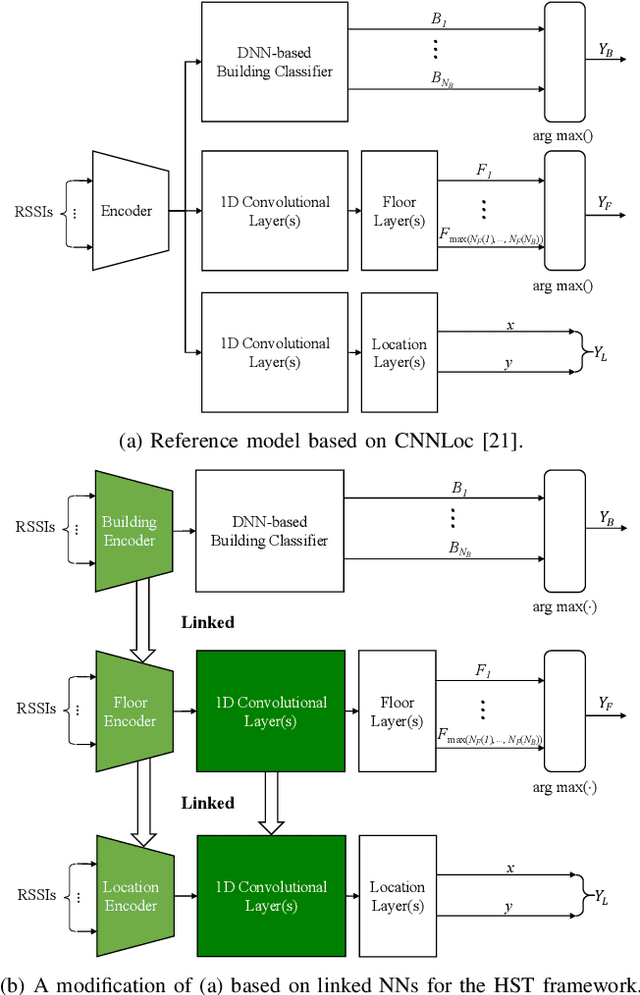
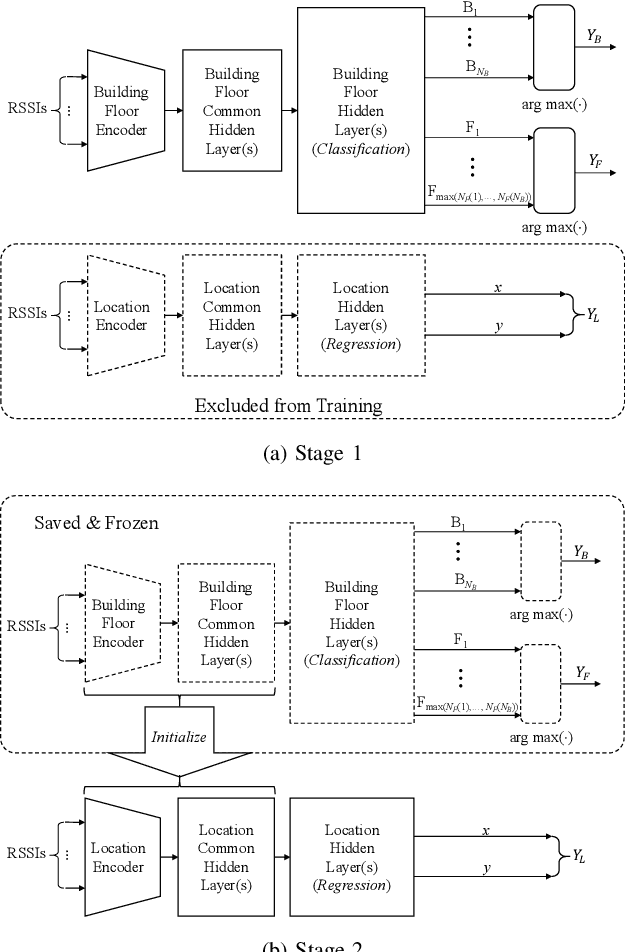
In this paper, we present a new solution to the problem of large-scale multi-building and multi-floor indoor localization based on linked neural networks, where each neural network is dedicated to a sub-problem and trained under a hierarchical stage-wise training framework. When the measured data from sensors have a hierarchical representation as in multi-building and multi-floor indoor localization, it is important to exploit the hierarchical nature in data processing to provide a scalable solution. In this regard, the hierarchical stage-wise training framework extends the original stage-wise training framework to the case of multiple linked networks by training a lower-hierarchy network based on the prior knowledge gained from the training of higher-hierarchy networks. The experimental results with the publicly-available UJIIndoorLoc multi-building and multi-floor Wi-Fi RSSI fingerprint database demonstrate that the linked neural networks trained under the proposed hierarchical stage-wise training framework can achieve a three-dimensional localization error of 8.19 m, which, to the best of the authors' knowledge, is the most accurate result ever obtained for neural network-based models trained and evaluated with the full datasets of the UJIIndoorLoc database, and that, when applied to a model based on hierarchical convolutional neural networks, the proposed training framework can also significantly reduce the three-dimensional localization error from 11.78 m to 8.71 m.
Static vs. Dynamic Databases for Indoor Localization based on Wi-Fi Fingerprinting: A Discussion from a Data Perspective
Feb 20, 2024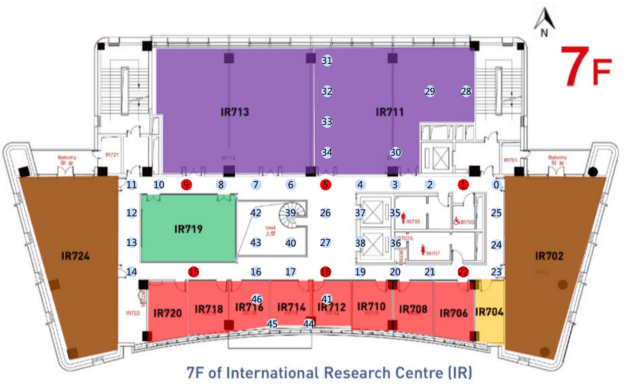
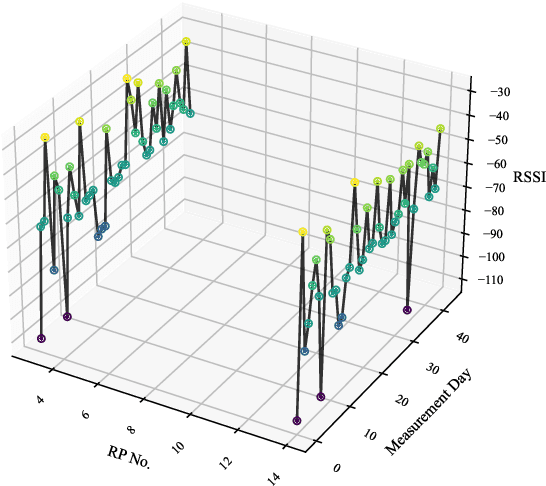
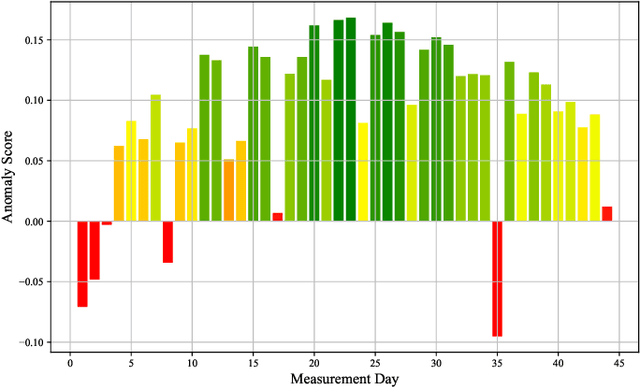
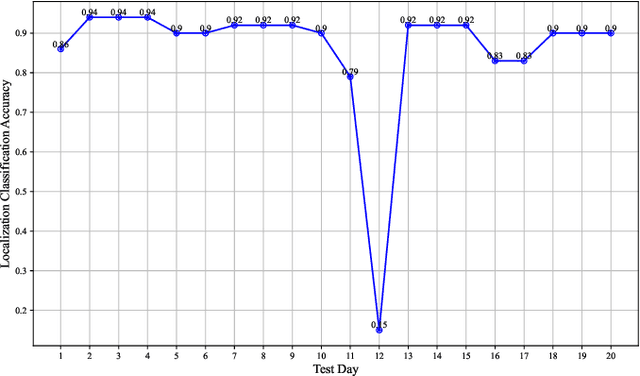
Wi-Fi fingerprinting has emerged as the most popular approach to indoor localization. The use of ML algorithms has greatly improved the localization performance of Wi-Fi fingerprinting, but its success depends on the availability of fingerprint databases composed of a large number of RSSIs, the MAC addresses of access points, and the other measurement information. However, most fingerprint databases do not reflect well the time varying nature of electromagnetic interferences in complicated modern indoor environment. This could result in significant changes in statistical characteristics of training/validation and testing datasets, which are often constructed at different times, and even the characteristics of the testing datasets could be different from those of the data submitted by users during the operation of localization systems after their deployment. In this paper, we consider the implications of time-varying Wi-Fi fingerprints on indoor localization from a data-centric point of view and discuss the differences between static and dynamic databases. As a case study, we have constructed a dynamic database covering three floors of the IR building of XJTLU based on RSSI measurements, over 44 days, and investigated the differences between static and dynamic databases in terms of statistical characteristics and localization performance. The analyses based on variance calculations and Isolation Forest show the temporal shifts in RSSIs, which result in a noticeable trend of the increase in the localization error of a Gaussian process regression model with the maximum error of 6.65 m after 14 days of training without model adjustments. The results of the case study with the XJTLU dynamic database clearly demonstrate the limitations of static databases and the importance of the creation and adoption of dynamic databases for future indoor localization research and real-world deployment.
3D Random Occlusion and Multi-Layer Projection for Deep Multi-Camera Pedestrian Localization
Jul 25, 2022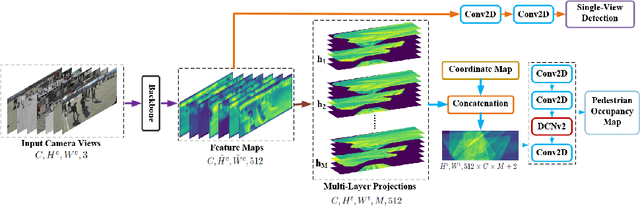

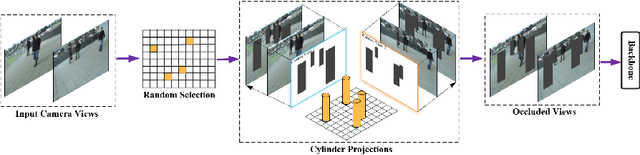
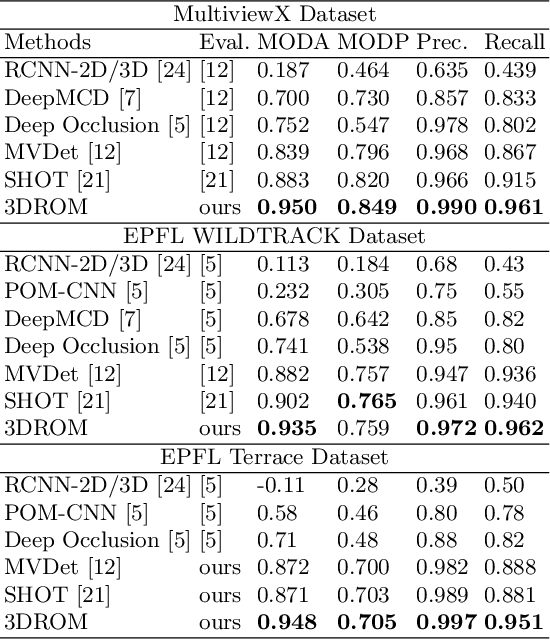
Although deep-learning based methods for monocular pedestrian detection have made great progress, they are still vulnerable to heavy occlusions. Using multi-view information fusion is a potential solution but has limited applications, due to the lack of annotated training samples in existing multi-view datasets, which increases the risk of overfitting. To address this problem, a data augmentation method is proposed to randomly generate 3D cylinder occlusions, on the ground plane, which are of the average size of pedestrians and projected to multiple views, to relieve the impact of overfitting in the training. Moreover, the feature map of each view is projected to multiple parallel planes at different heights, by using homographies, which allows the CNNs to fully utilize the features across the height of each pedestrian to infer the locations of pedestrians on the ground plane. The proposed 3DROM method has a greatly improved performance in comparison with the state-of-the-art deep-learning based methods for multi-view pedestrian detection.
Image Captioning Based on a Hierarchical Attention Mechanism and Policy Gradient Optimization
Nov 13, 2018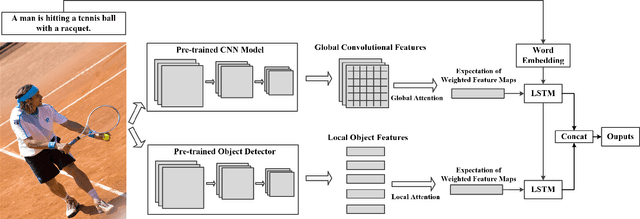
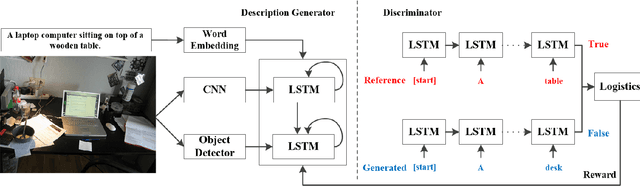
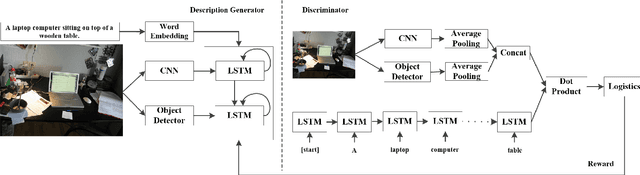
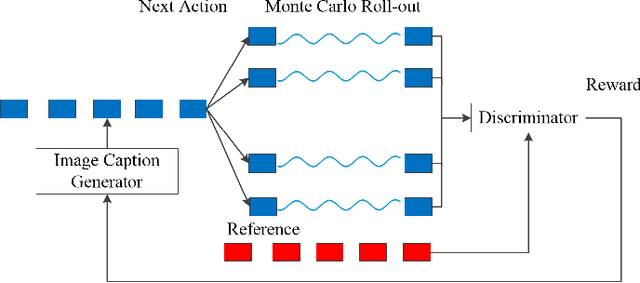
Automatically generating the descriptions of an image, i.e., image captioning, is an important and fundamental topic in artificial intelligence, which bridges the gap between computer vision and natural language processing. Based on the successful deep learning models, especially the CNN model and Long Short-Term Memories (LSTMs) with attention mechanism, we propose a hierarchical attention model by utilizing both of the global CNN features and the local object features for more effective feature representation and reasoning in image captioning. The generative adversarial network (GAN), together with a reinforcement learning (RL) algorithm, is applied to solve the exposure bias problem in RNN-based supervised training for language problems. In addition, through the automatic measurement of the consistency between the generated caption and the image content by the discriminator in the GAN framework and RL optimization, we make the finally generated sentences more accurate and natural. Comprehensive experiments show the improved performance of the hierarchical attention mechanism and the effectiveness of our RL-based optimization method. Our model achieves state-of-the-art results on several important metrics in the MSCOCO dataset, using only greedy inference.
Hierarchical Multi-scale Attention Networks for Action Recognition
Aug 28, 2017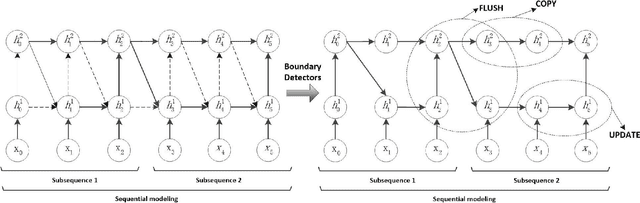
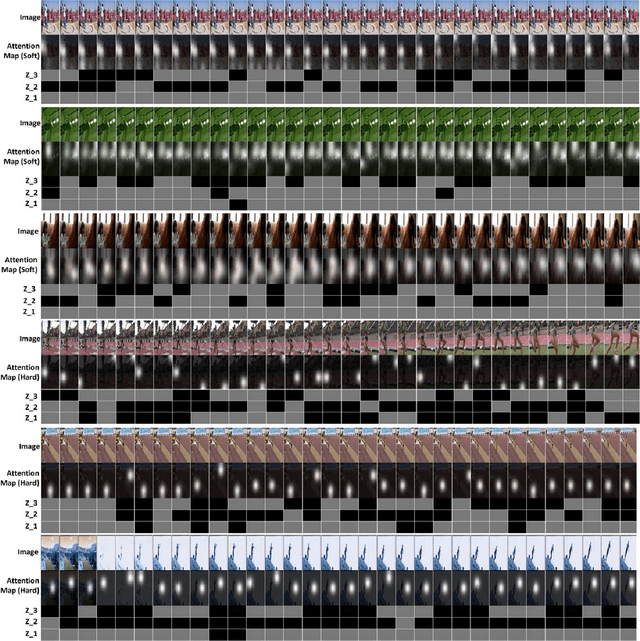
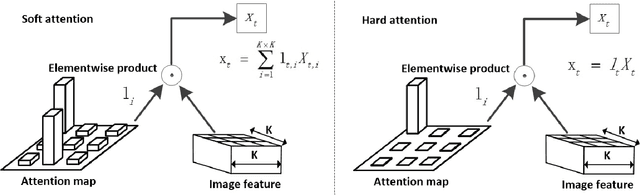
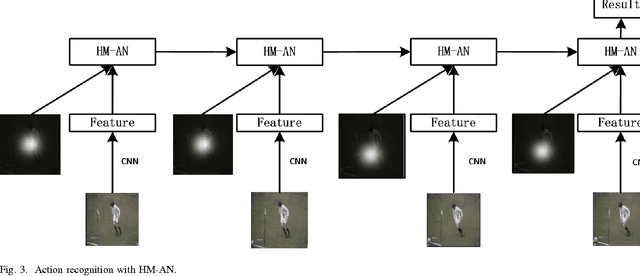
Recurrent Neural Networks (RNNs) have been widely used in natural language processing and computer vision. Among them, the Hierarchical Multi-scale RNN (HM-RNN), a kind of multi-scale hierarchical RNN proposed recently, can learn the hierarchical temporal structure from data automatically. In this paper, we extend the work to solve the computer vision task of action recognition. However, in sequence-to-sequence models like RNN, it is normally very hard to discover the relationships between inputs and outputs given static inputs. As a solution, attention mechanism could be applied to extract the relevant information from input thus facilitating the modeling of input-output relationships. Based on these considerations, we propose a novel attention network, namely Hierarchical Multi-scale Attention Network (HM-AN), by combining the HM-RNN and the attention mechanism and apply it to action recognition. A newly proposed gradient estimation method for stochastic neurons, namely Gumbel-softmax, is exploited to implement the temporal boundary detectors and the stochastic hard attention mechanism. To amealiate the negative effect of sensitive temperature of the Gumbel-softmax, an adaptive temperature training method is applied to better the system performance. The experimental results demonstrate the improved effect of HM-AN over LSTM with attention on the vision task. Through visualization of what have been learnt by the networks, it can be observed that both the attention regions of images and the hierarchical temporal structure can be captured by HM-AN.
Traffic scene recognition based on deep cnn and vlad spatial pyramids
Jul 24, 2017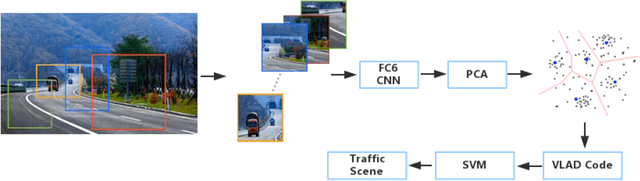
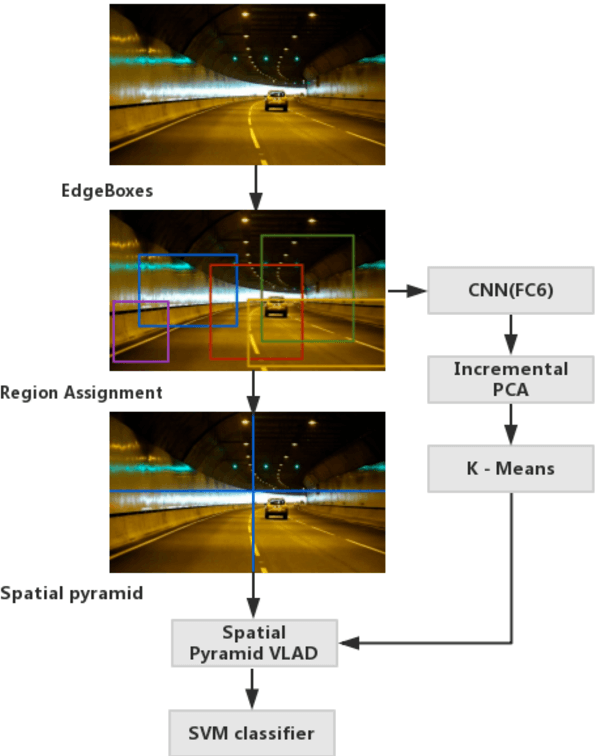
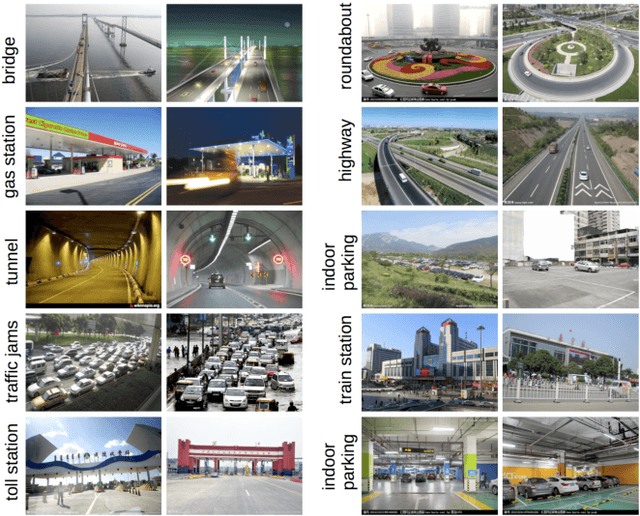

Traffic scene recognition is an important and challenging issue in Intelligent Transportation Systems (ITS). Recently, Convolutional Neural Network (CNN) models have achieved great success in many applications, including scene classification. The remarkable representational learning capability of CNN remains to be further explored for solving real-world problems. Vector of Locally Aggregated Descriptors (VLAD) encoding has also proved to be a powerful method in catching global contextual information. In this paper, we attempted to solve the traffic scene recognition problem by combining the features representational capabilities of CNN with the VLAD encoding scheme. More specifically, the CNN features of image patches generated by a region proposal algorithm are encoded by applying VLAD, which subsequently represent an image in a compact representation. To catch the spatial information, spatial pyramids are exploited to encode CNN features. We experimented with a dataset of 10 categories of traffic scenes, with satisfactory categorization performances.
CHAM: action recognition using convolutional hierarchical attention model
May 19, 2017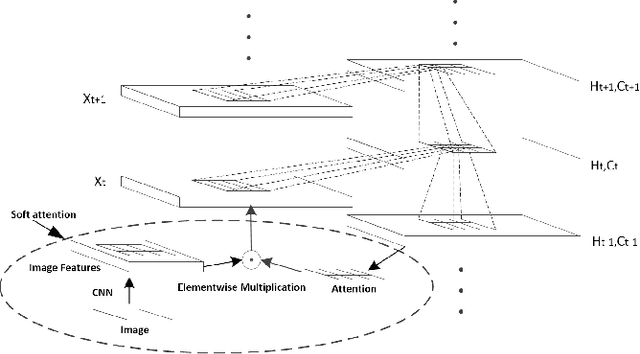
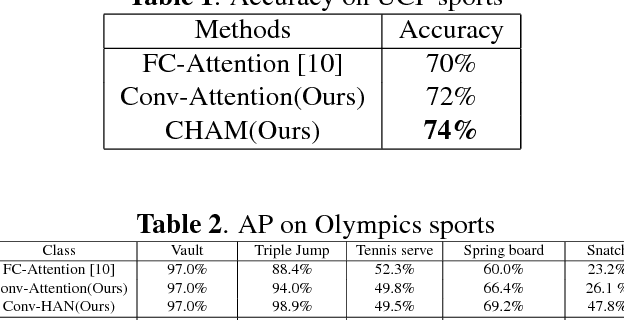
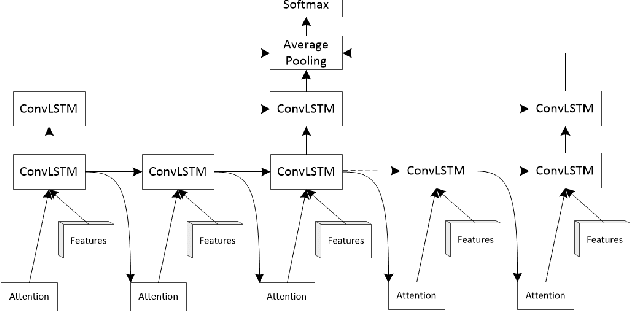
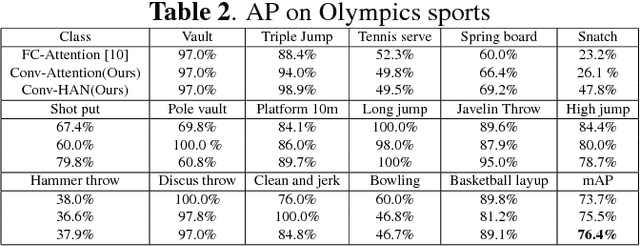
Recently, the soft attention mechanism, which was originally proposed in language processing, has been applied in computer vision tasks like image captioning. This paper presents improvements to the soft attention model by combining a convolutional LSTM with a hierarchical system architecture to recognize action categories in videos. We call this model the Convolutional Hierarchical Attention Model (CHAM). The model applies a convolutional operation inside the LSTM cell and an attention map generation process to recognize actions. The hierarchical architecture of this model is able to explicitly reason on multi-granularities of action categories. The proposed architecture achieved improved results on three publicly available datasets: the UCF sports dataset, the Olympic sports dataset and the HMDB51 dataset.