 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHAM: action recognition using convolutional hierarchical attention model
Paper and Code
May 19, 2017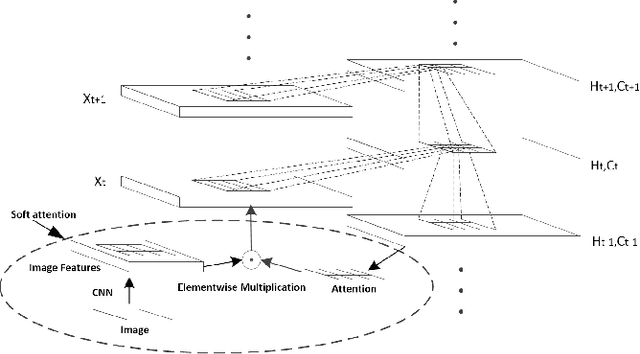
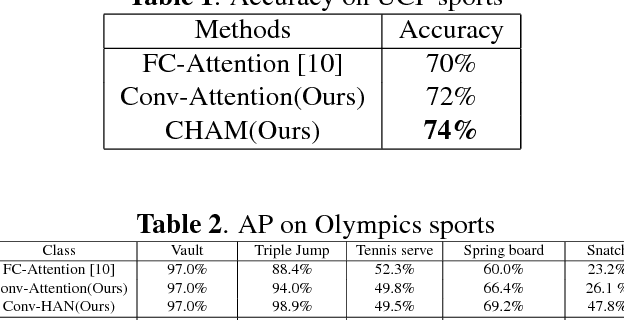
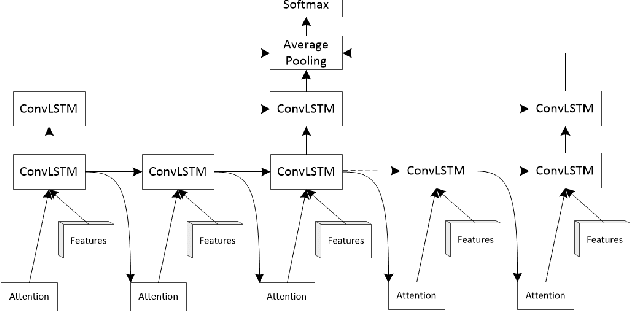
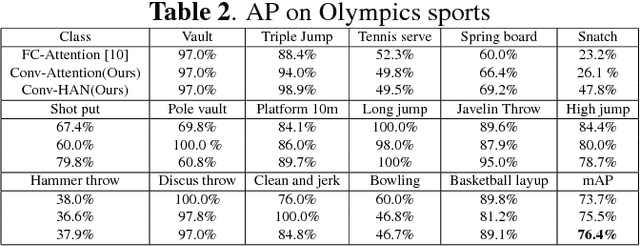
Recently, the soft attention mechanism, which was originally proposed in language processing, has been applied in computer vision tasks like image captioning. This paper presents improvements to the soft attention model by combining a convolutional LSTM with a hierarchical system architecture to recognize action categories in videos. We call this model the Convolutional Hierarchical Attention Model (CHAM). The model applies a convolutional operation inside the LSTM cell and an attention map generation process to recognize actions. The hierarchical architecture of this model is able to explicitly reason on multi-granularities of action categories. The proposed architecture achieved improved results on three publicly available datasets: the UCF sports dataset, the Olympic sports dataset and the HMDB51 dataset.