 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Captioning Based on a Hierarchical Attention Mechanism and Policy Gradient Optimization
Nov 13, 2018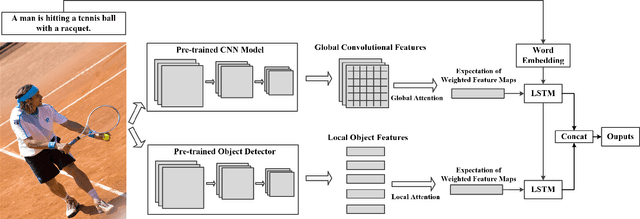
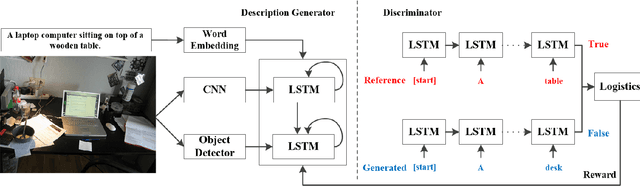
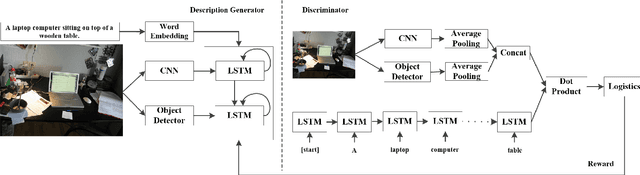
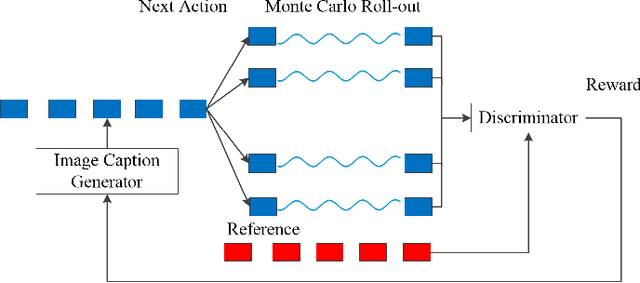
Automatically generating the descriptions of an image, i.e., image captioning, is an important and fundamental topic in artificial intelligence, which bridges the gap between computer vision and natural language processing. Based on the successful deep learning models, especially the CNN model and Long Short-Term Memories (LSTMs) with attention mechanism, we propose a hierarchical attention model by utilizing both of the global CNN features and the local object features for more effective feature representation and reasoning in image captioning. The generative adversarial network (GAN), together with a reinforcement learning (RL) algorithm, is applied to solve the exposure bias problem in RNN-based supervised training for language problems. In addition, through the automatic measurement of the consistency between the generated caption and the image content by the discriminator in the GAN framework and RL optimization, we make the finally generated sentences more accurate and natural. Comprehensive experiments show the improved performance of the hierarchical attention mechanism and the effectiveness of our RL-based optimization method. Our model achieves state-of-the-art results on several important metrics in the MSCOCO dataset, using only greedy inference.
Hierarchical Multi-scale Attention Networks for Action Recognition
Aug 28, 2017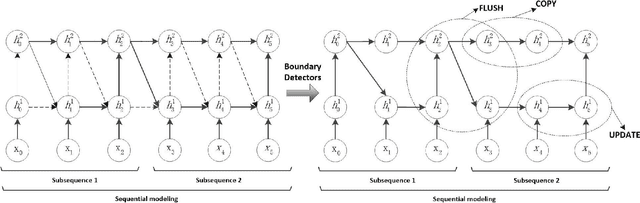
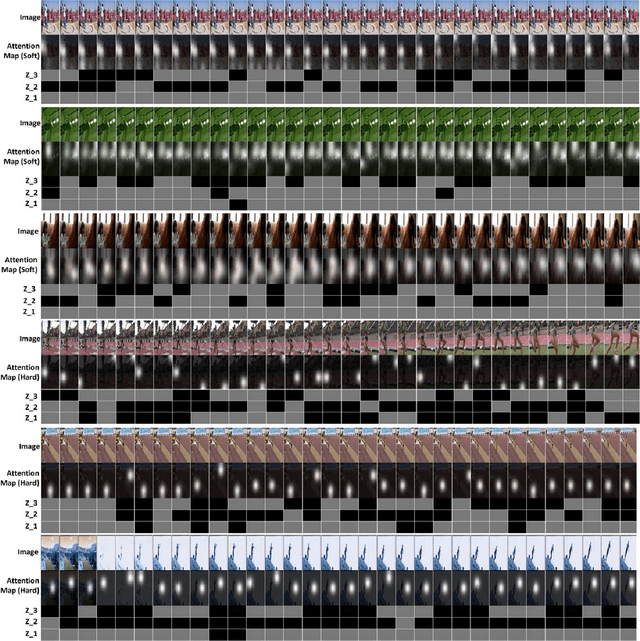
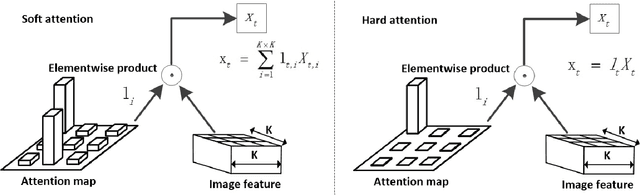
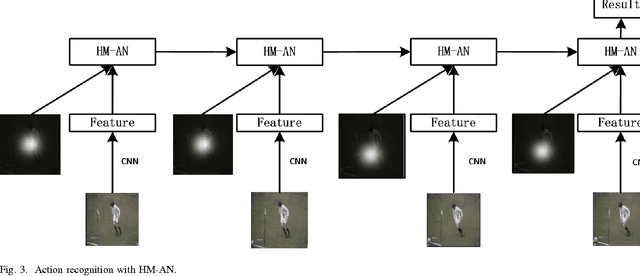
Recurrent Neural Networks (RNNs) have been widely used in natural language processing and computer vision. Among them, the Hierarchical Multi-scale RNN (HM-RNN), a kind of multi-scale hierarchical RNN proposed recently, can learn the hierarchical temporal structure from data automatically. In this paper, we extend the work to solve the computer vision task of action recognition. However, in sequence-to-sequence models like RNN, it is normally very hard to discover the relationships between inputs and outputs given static inputs. As a solution, attention mechanism could be applied to extract the relevant information from input thus facilitating the modeling of input-output relationships. Based on these considerations, we propose a novel attention network, namely Hierarchical Multi-scale Attention Network (HM-AN), by combining the HM-RNN and the attention mechanism and apply it to action recognition. A newly proposed gradient estimation method for stochastic neurons, namely Gumbel-softmax, is exploited to implement the temporal boundary detectors and the stochastic hard attention mechanism. To amealiate the negative effect of sensitive temperature of the Gumbel-softmax, an adaptive temperature training method is applied to better the system performance. The experimental results demonstrate the improved effect of HM-AN over LSTM with attention on the vision task. Through visualization of what have been learnt by the networks, it can be observed that both the attention regions of images and the hierarchical temporal structure can be captured by HM-AN.
CHAM: action recognition using convolutional hierarchical attention model
May 19, 2017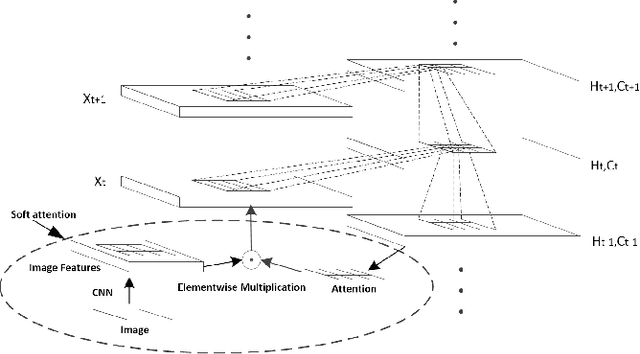
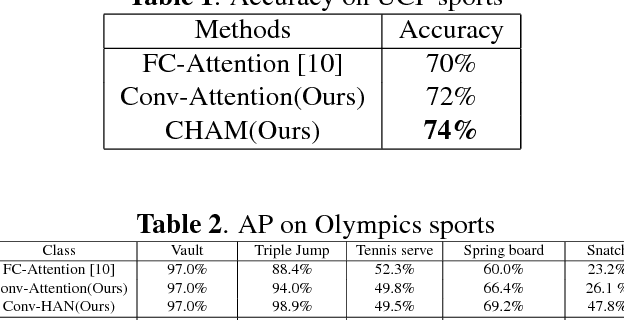
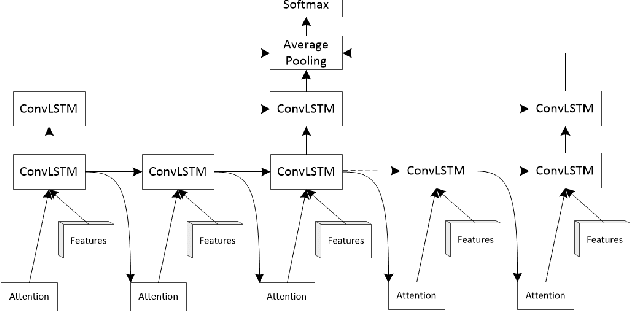
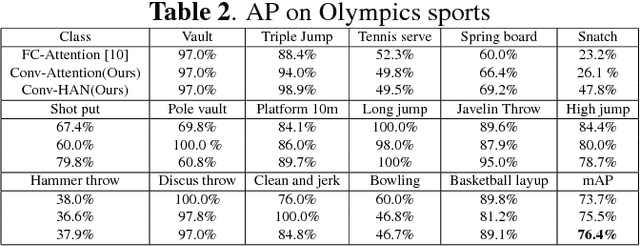
Recently, the soft attention mechanism, which was originally proposed in language processing, has been applied in computer vision tasks like image captioning. This paper presents improvements to the soft attention model by combining a convolutional LSTM with a hierarchical system architecture to recognize action categories in videos. We call this model the Convolutional Hierarchical Attention Model (CHAM). The model applies a convolutional operation inside the LSTM cell and an attention map generation process to recognize actions. The hierarchical architecture of this model is able to explicitly reason on multi-granularities of action categories. The proposed architecture achieved improved results on three publicly available datasets: the UCF sports dataset, the Olympic sports dataset and the HMDB51 dataset.