 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraffic scene recognition based on deep cnn and vlad spatial pyramids
Jul 24, 2017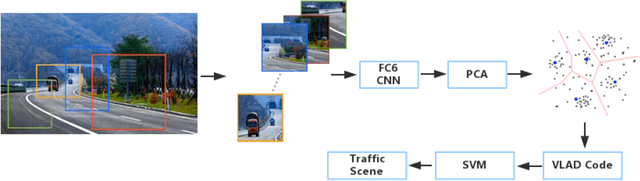
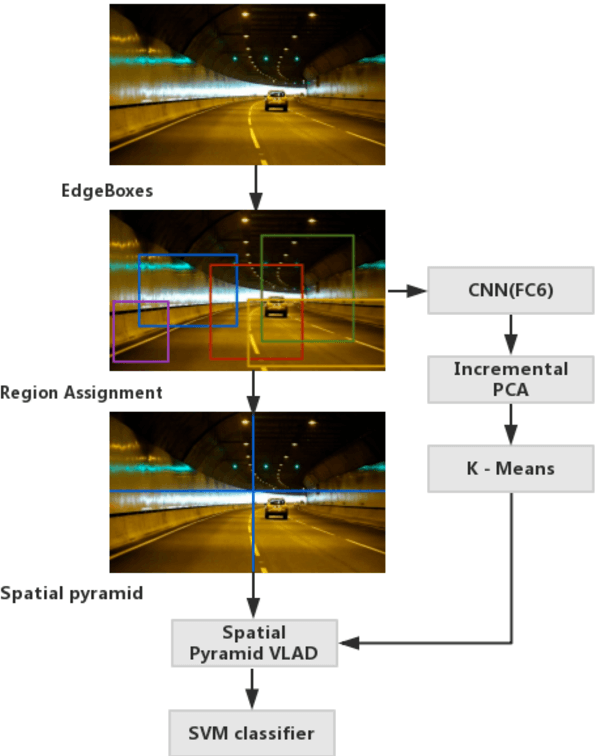
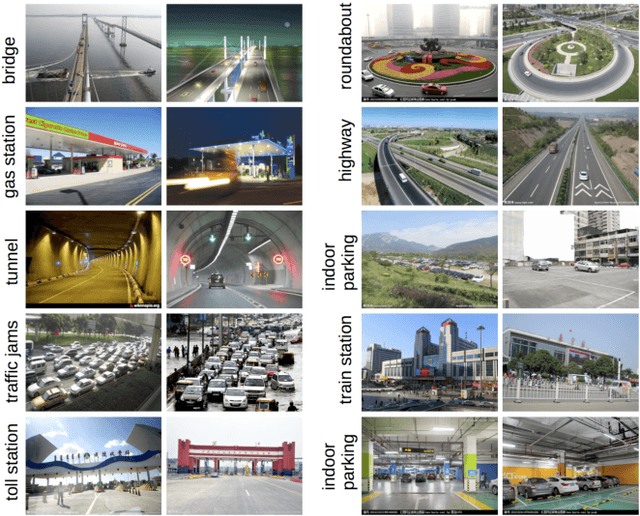

Traffic scene recognition is an important and challenging issue in Intelligent Transportation Systems (ITS). Recently, Convolutional Neural Network (CNN) models have achieved great success in many applications, including scene classification. The remarkable representational learning capability of CNN remains to be further explored for solving real-world problems. Vector of Locally Aggregated Descriptors (VLAD) encoding has also proved to be a powerful method in catching global contextual information. In this paper, we attempted to solve the traffic scene recognition problem by combining the features representational capabilities of CNN with the VLAD encoding scheme. More specifically, the CNN features of image patches generated by a region proposal algorithm are encoded by applying VLAD, which subsequently represent an image in a compact representation. To catch the spatial information, spatial pyramids are exploited to encode CNN features. We experimented with a dataset of 10 categories of traffic scenes, with satisfactory categorization performances.