 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHorNet: A Hierarchical Offshoot Recurrent Network for Improving Person Re-ID via Image Captioning
Aug 14, 2019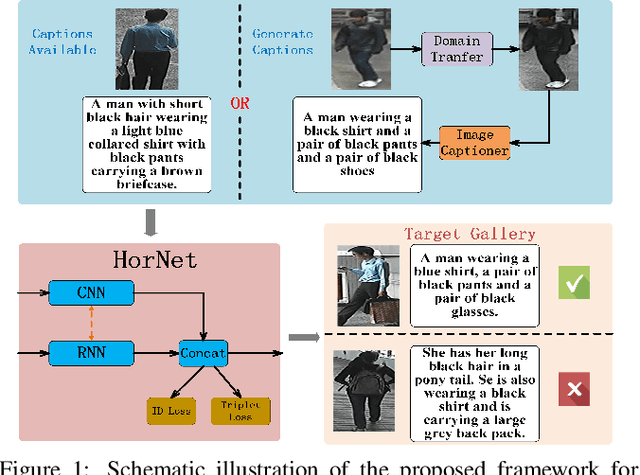
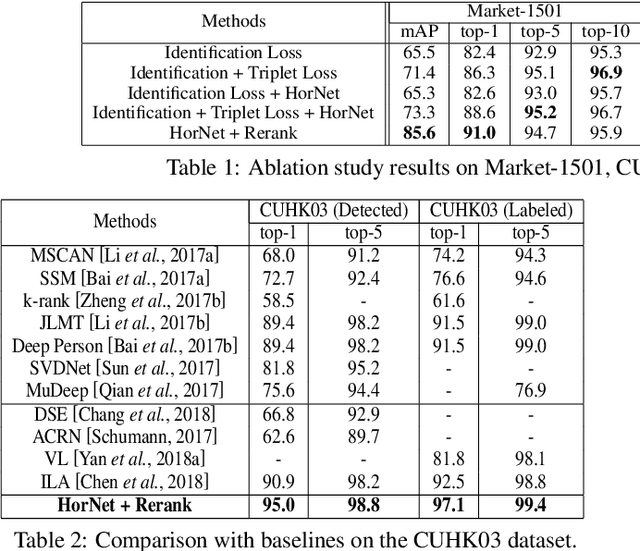
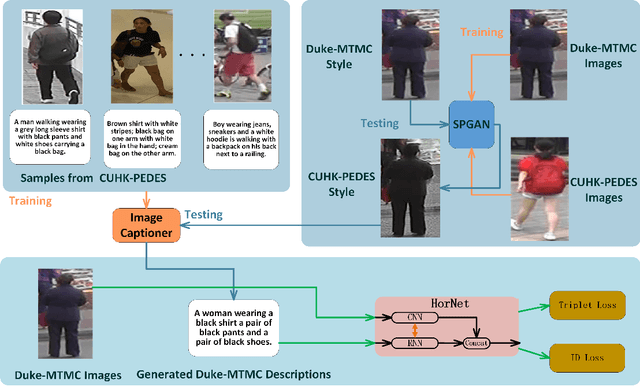
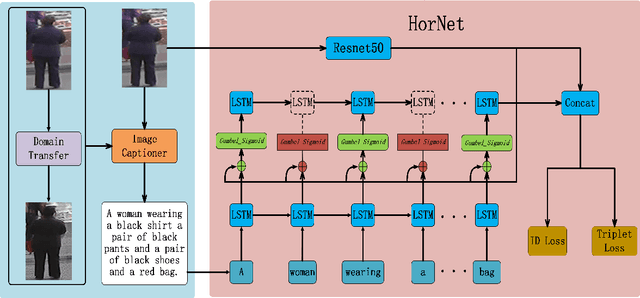
Person re-identification (re-ID) aims to recognize a person-of-interest across different cameras with notable appearance variance. Existing research works focused on the capability and robustness of visual representation. In this paper, instead, we propose a novel hierarchical offshoot recurrent network (HorNet) for improving person re-ID via image captioning. Image captions are semantically richer and more consistent than visual attributes, which could significantly alleviate the variance. We use the similarity preserving generative adversarial network (SPGAN) and an image captioner to fulfill domain transfer and language descriptions generation. Then the proposed HorNet can learn the visual and language representation from both the images and captions jointly, and thus enhance the performance of person re-ID. Extensive experiments are conducted on several benchmark datasets with or without image captions, i.e., CUHK03, Market-1501, and Duke-MTMC, demonstrating the superiority of the proposed method. Our method can generate and extract meaningful image captions while achieving state-of-the-art performance.
Learning with Batch-wise Optimal Transport Loss for 3D Shape Recognition
Mar 21, 2019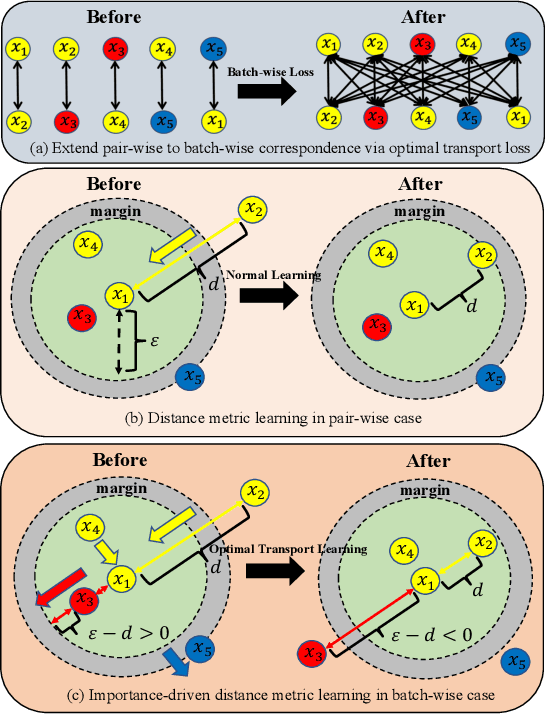



Deep metric learning is essential for visual recognition. The widely used pair-wise (or triplet) based loss objectives cannot make full use of semantical information in training samples or give enough attention to those hard samples during optimization. Thus, they often suffer from a slow convergence rate and inferior performance. In this paper, we show how to learn an importance-driven distance metric via optimal transport programming from batches of samples. It can automatically emphasize hard examples and lead to significant improvements in convergence. We propose a new batch-wise optimal transport loss and combine it in an end-to-end deep metric learning manner. We use it to learn the distance metric and deep feature representation jointly for recognition. Empirical results on visual retrieval and classification tasks with six benchmark datasets, i.e., MNIST, CIFAR10, SHREC13, SHREC14, ModelNet10, and ModelNet40, demonstrate the superiority of the proposed method. It can accelerate the convergence rate significantly while achieving a state-of-the-art recognition performance. For example, in 3D shape recognition experiments, we show that our method can achieve better recognition performance within only 5 epochs than what can be obtained by mainstream 3D shape recognition approaches after 200 epochs.