 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXLM-K: Improving Cross-Lingual Language Model Pre-Training with Multilingual Knowledge
Paper and Code
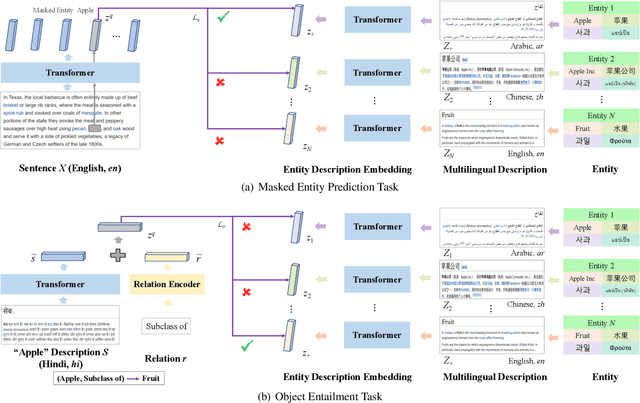
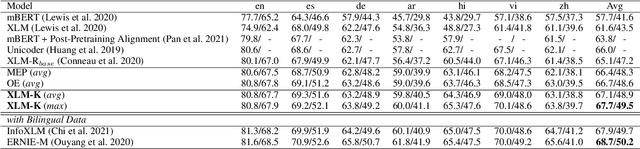
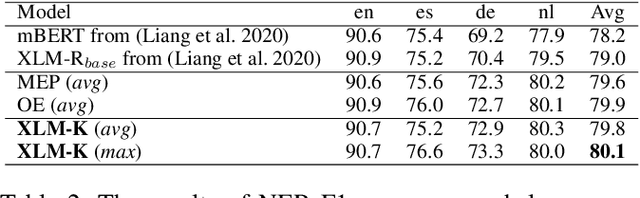

Cross-lingual pre-training has achieved great successes using monolingual and bilingual plain text corpora. However, existing pre-trained models neglect multilingual knowledge, which is language agnostic but comprises abundant cross-lingual structure alignment. In this paper, we propose XLM-K, a cross-lingual language model incorporating multilingual knowledge in pre-training. XLM-K augments existing multilingual pre-training with two knowledge tasks, namely Masked Entity Prediction Task and Object Entailment Task. We evaluate XLM-K on MLQA, NER and XNLI. Experimental results clearly demonstrate significant improvements over existing multilingual language models. The results on MLQA and NER exhibit the superiority of XLM-K in knowledge related tasks. The success in XNLI shows a better cross-lingual transferability obtained in XLM-K. What is more, we provide a detailed probing analysis to confirm the desired knowledge captured in our pre-training regimen.