 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA sequential guiding network with attention for image captioning
Nov 01, 2018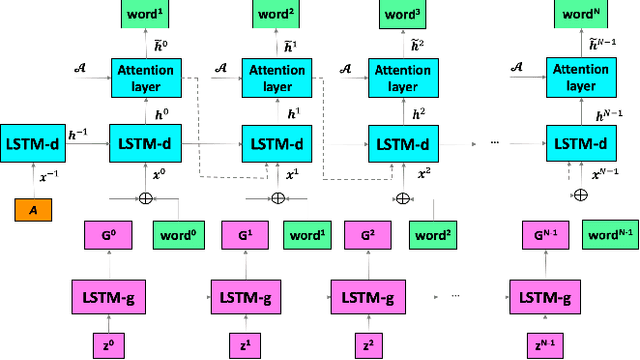
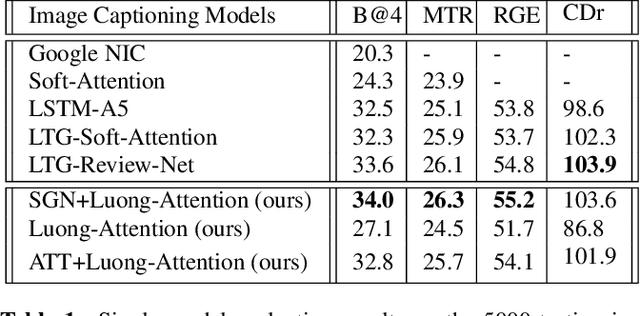
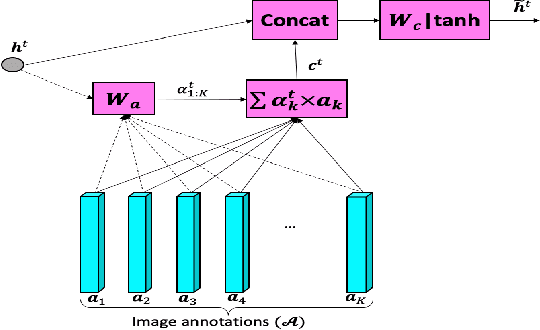
The recent advances of deep learning in both computer vision (CV)and natural language processing (NLP) provide us a new way of un-derstanding semantics, by which we can deal with more challeng-ing tasks such as automatic description generation from natural im-ages. In this challenge, the encoder-decoder framework has achievedpromising performance when a convolutional neural network (CNN)is used as image encoder and a recurrent neural network (RNN) asdecoder. In this paper, we introduce a sequential guiding networkthat guides the decoder during word generation. The new model is anextension of the encoder-decoder framework with attention that hasan additional guiding long short-term memory (LSTM) and can betrained in an end-to-end manner by using image/descriptions pairs.We validate our approach by conducting extensive experiments on abenchmark dataset, i.e., MS COCO Captions. The proposed model achieves significant improvement comparing to the other state-of-the-art deep learning models.