 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Semantics-aware Representation Enhancement for Self-supervised Monocular Depth Estimation
Paper and Code
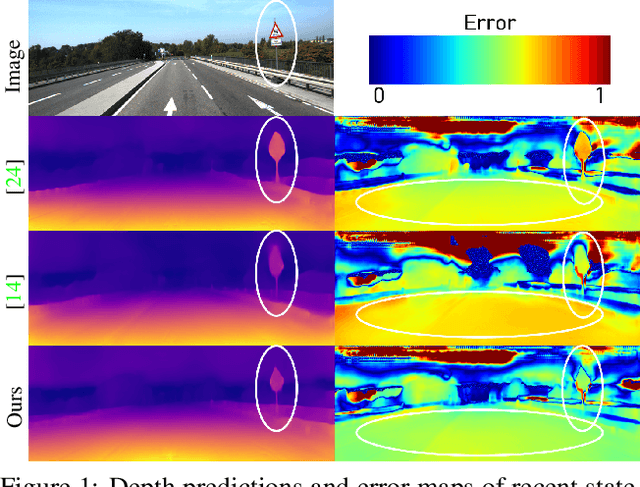
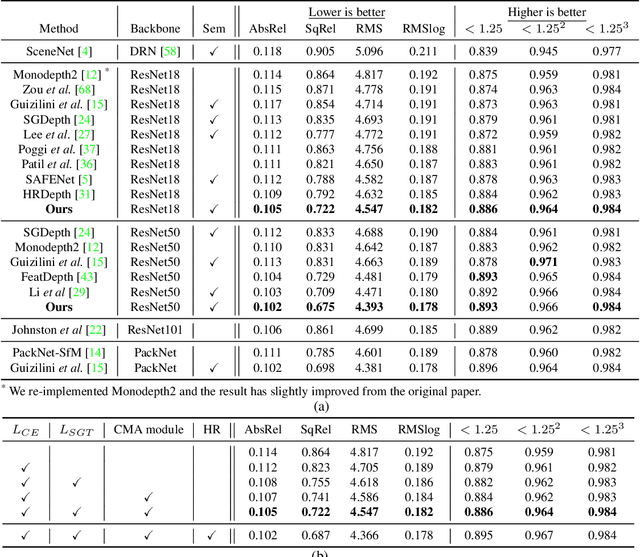
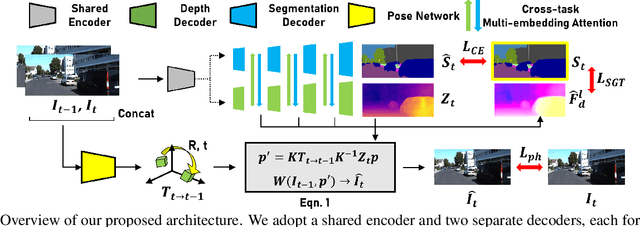
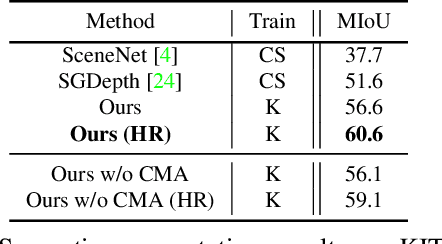
Self-supervised monocular depth estimation has been widely studied, owing to its practical importance and recent promising improvements. However, most works suffer from limited supervision of photometric consistency, especially in weak texture regions and at object boundaries. To overcome this weakness, we propose novel ideas to improve self-supervised monocular depth estimation by leveraging cross-domain information, especially scene semantics. We focus on incorporating implicit semantic knowledge into geometric representation enhancement and suggest two ideas: a metric learning approach that exploits the semantics-guided local geometry to optimize intermediate depth representations and a novel feature fusion module that judiciously utilizes cross-modality between two heterogeneous feature representations. We comprehensively evaluate our methods on the KITTI dataset and demonstrate that our method outperforms state-of-the-art methods. The source code is available at https://github.com/hyBlue/FSRE-Depth.