 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInv-Adapter: ID Customization Generation via Image Inversion and Lightweight Adapter
Paper and Code
Jun 06, 2024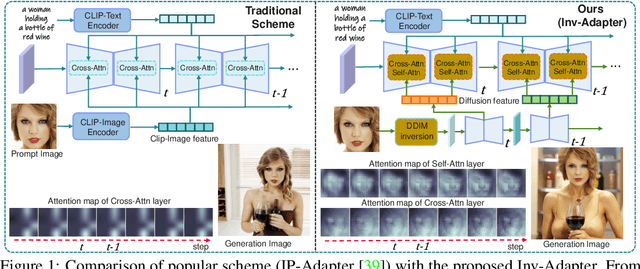

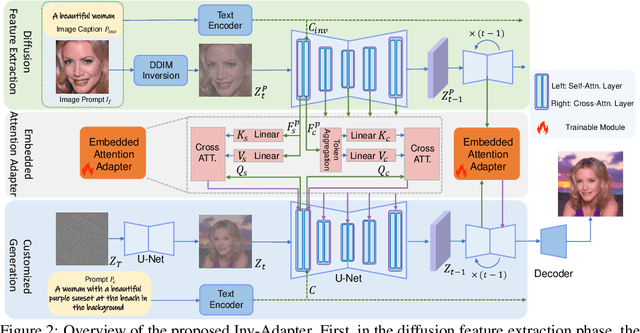

The remarkable advancement in text-to-image generation models significantly boosts the research in ID customization generation. However, existing personalization methods cannot simultaneously satisfy high fidelity and high-efficiency requirements. Their main bottleneck lies in the prompt image encoder, which produces weak alignment signals with the text-to-image model and significantly increased model size. Towards this end, we propose a lightweight Inv-Adapter, which first extracts diffusion-domain representations of ID images utilizing a pre-trained text-to-image model via DDIM image inversion, without additional image encoder. Benefiting from the high alignment of the extracted ID prompt features and the intermediate features of the text-to-image model, we then embed them efficiently into the base text-to-image model by carefully designing a lightweight attention adapter. We conduct extensive experiments to assess ID fidelity, generation loyalty, speed, and training parameters, all of which show that the proposed Inv-Adapter is highly competitive in ID customization generation and model scale.