 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInv-Adapter: ID Customization Generation via Image Inversion and Lightweight Adapter
Jun 06, 2024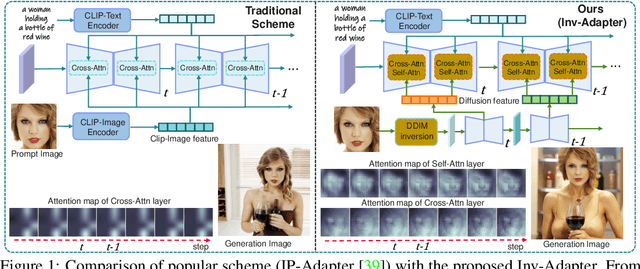

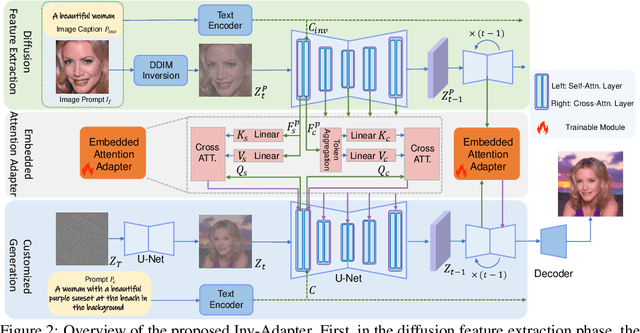

The remarkable advancement in text-to-image generation models significantly boosts the research in ID customization generation. However, existing personalization methods cannot simultaneously satisfy high fidelity and high-efficiency requirements. Their main bottleneck lies in the prompt image encoder, which produces weak alignment signals with the text-to-image model and significantly increased model size. Towards this end, we propose a lightweight Inv-Adapter, which first extracts diffusion-domain representations of ID images utilizing a pre-trained text-to-image model via DDIM image inversion, without additional image encoder. Benefiting from the high alignment of the extracted ID prompt features and the intermediate features of the text-to-image model, we then embed them efficiently into the base text-to-image model by carefully designing a lightweight attention adapter. We conduct extensive experiments to assess ID fidelity, generation loyalty, speed, and training parameters, all of which show that the proposed Inv-Adapter is highly competitive in ID customization generation and model scale.
Contextual Similarity Aggregation with Self-attention for Visual Re-ranking
Oct 26, 2021

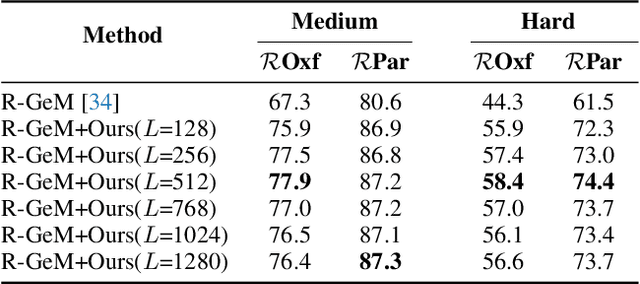
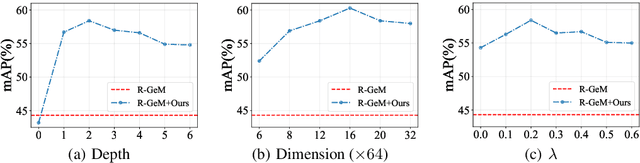
In content-based image retrieval, the first-round retrieval result by simple visual feature comparison may be unsatisfactory, which can be refined by visual re-ranking techniques. In image retrieval, it is observed that the contextual similarity among the top-ranked images is an important clue to distinguish the semantic relevance. Inspired by this observation, in this paper, we propose a visual re-ranking method by contextual similarity aggregation with self-attention. In our approach, for each image in the top-K ranking list, we represent it into an affinity feature vector by comparing it with a set of anchor images. Then, the affinity features of the top-K images are refined by aggregating the contextual information with a transformer encoder. Finally, the affinity features are used to recalculate the similarity scores between the query and the top-K images for re-ranking of the latter. To further improve the robustness of our re-ranking model and enhance the performance of our method, a new data augmentation scheme is designed. Since our re-ranking model is not directly involved with the visual feature used in the initial retrieval, it is ready to be applied to retrieval result lists obtained from various retrieval algorithms. We conduct comprehensive experiments on four benchmark datasets to demonstrate the generality and effectiveness of our proposed visual re-ranking method.