 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Perspective Knowledge Enrichment for Semi-Supervised 3D Object Detection
Jan 10, 2024



Semi-supervised 3D object detection is a promising yet under-explored direction to reduce data annotation costs, especially for cluttered indoor scenes. A few prior works, such as SESS and 3DIoUMatch, attempt to solve this task by utilizing a teacher model to generate pseudo-labels for unlabeled samples. However, the availability of unlabeled samples in the 3D domain is relatively limited compared to its 2D counterpart due to the greater effort required to collect 3D data. Moreover, the loose consistency regularization in SESS and restricted pseudo-label selection strategy in 3DIoUMatch lead to either low-quality supervision or a limited amount of pseudo labels. To address these issues, we present a novel Dual-Perspective Knowledge Enrichment approach named DPKE for semi-supervised 3D object detection. Our DPKE enriches the knowledge of limited training data, particularly unlabeled data, from two perspectives: data-perspective and feature-perspective. Specifically, from the data-perspective, we propose a class-probabilistic data augmentation method that augments the input data with additional instances based on the varying distribution of class probabilities. Our DPKE achieves feature-perspective knowledge enrichment by designing a geometry-aware feature matching method that regularizes feature-level similarity between object proposals from the student and teacher models. Extensive experiments on the two benchmark datasets demonstrate that our DPKE achieves superior performance over existing state-of-the-art approaches under various label ratio conditions. The source code will be made available to the public.
An End-to-End Network for Generating Social Relationship Graphs
Mar 23, 2019

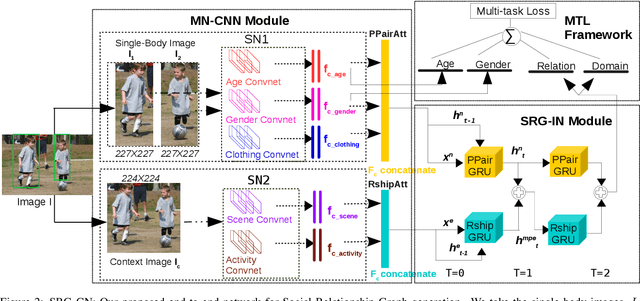

Socially-intelligent agents are of growing interest in artificial intelligence. To this end, we need systems that can understand social relationships in diverse social contexts. Inferring the social context in a given visual scene not only involves recognizing objects, but also demands a more in-depth understanding of the relationships and attributes of the people involved. To achieve this, one computational approach for representing human relationships and attributes is to use an explicit knowledge graph, which allows for high-level reasoning. We introduce a novel end-to-end-trainable neural network that is capable of generating a Social Relationship Graph - a structured, unified representation of social relationships and attributes - from a given input image. Our Social Relationship Graph Generation Network (SRG-GN) is the first to use memory cells like Gated Recurrent Units (GRUs) to iteratively update the social relationship states in a graph using scene and attribute context. The neural network exploits the recurrent connections among the GRUs to implement message passing between nodes and edges in the graph, and results in significant improvement over previous methods for social relationship recognition.
Egocentric Spatial Memory
Jul 31, 2018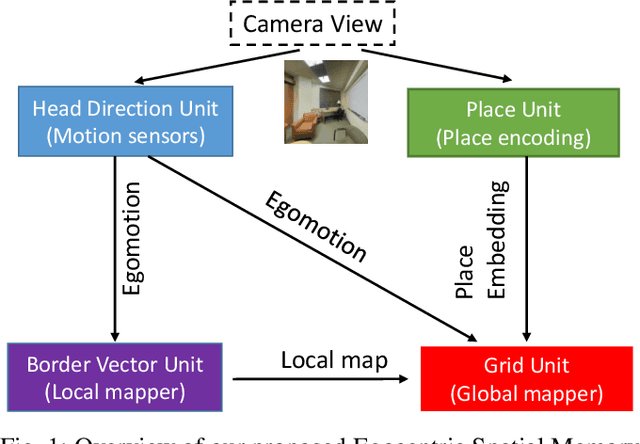
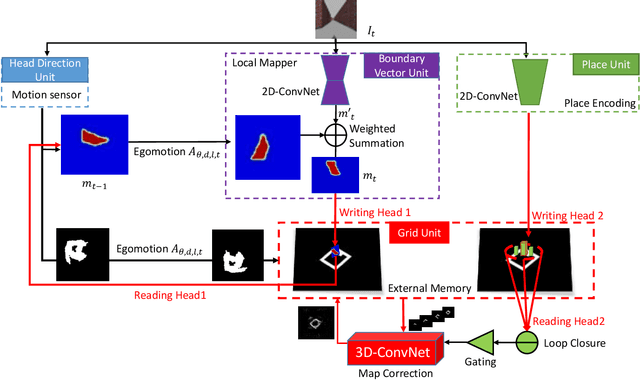

Egocentric spatial memory (ESM) defines a memory system with encoding, storing, recognizing and recalling the spatial information about the environment from an egocentric perspective. We introduce an integrated deep neural network architecture for modeling ESM. It learns to estimate the occupancy state of the world and progressively construct top-down 2D global maps from egocentric views in a spatially extended environment. During the exploration, our proposed ESM model updates belief of the global map based on local observations using a recurrent neural network. It also augments the local mapping with a novel external memory to encode and store latent representations of the visited places over long-term exploration in large environments which enables agents to perform place recognition and hence, loop closure. Our proposed ESM network contributes in the following aspects: (1) without feature engineering, our model predicts free space based on egocentric views efficiently in an end-to-end manner; (2) different from other deep learning-based mapping system, ESMN deals with continuous actions and states which is vitally important for robotic control in real applications. In the experiments, we demonstrate its accurate and robust global mapping capacities in 3D virtual mazes and realistic indoor environments by comparing with several competitive baselines.
Finding any Waldo: zero-shot invariant and efficient visual search
Jul 18, 2018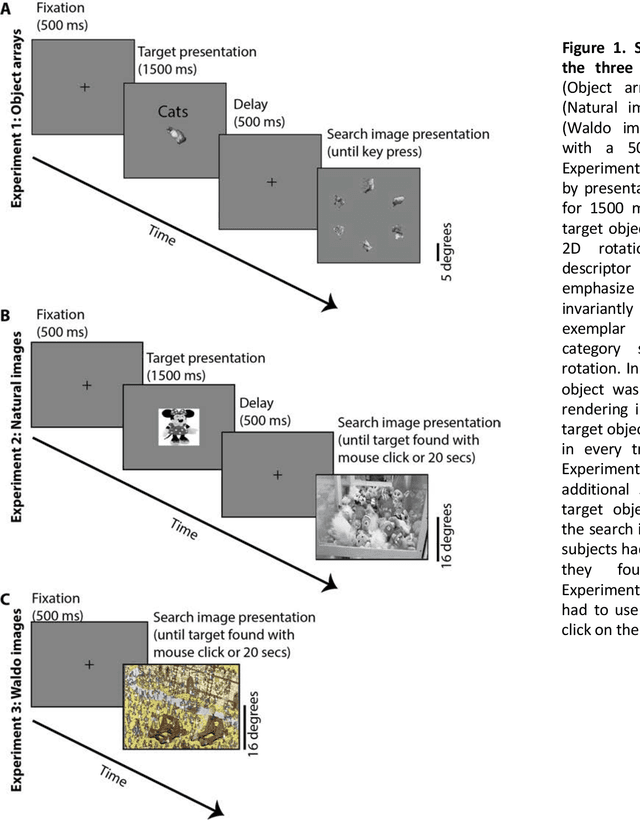
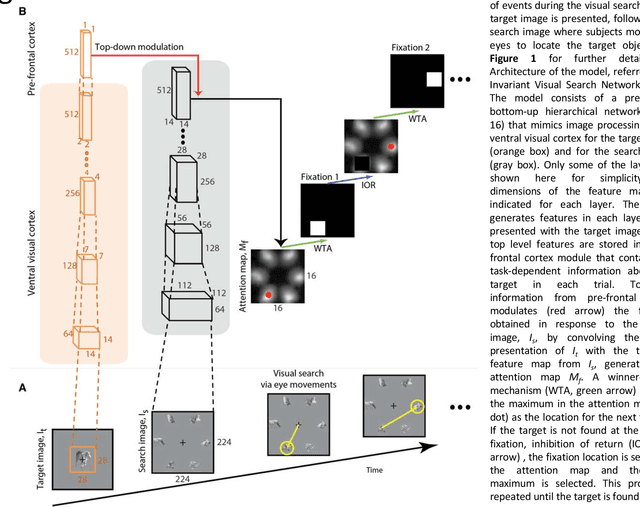
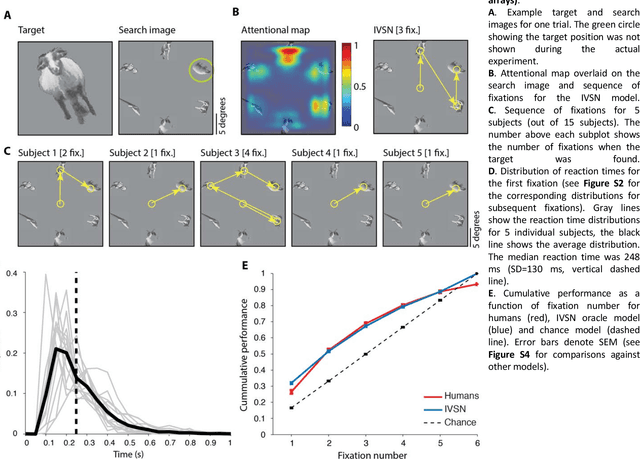
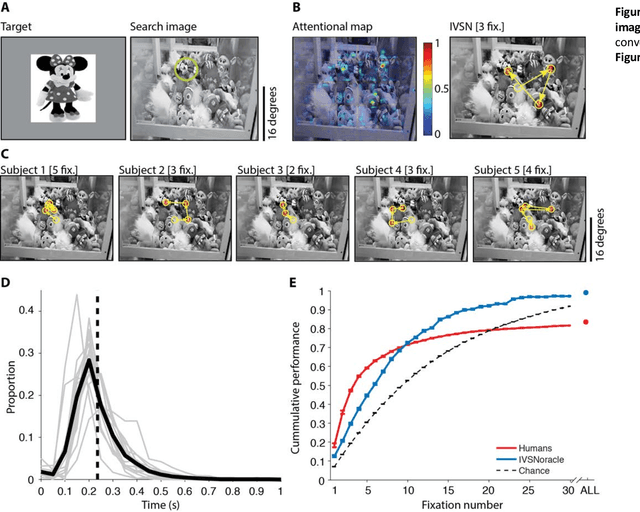
Searching for a target object in a cluttered scene constitutes a fundamental challenge in daily vision. Visual search must be selective enough to discriminate the target from distractors, invariant to changes in the appearance of the target, efficient to avoid exhaustive exploration of the image, and must generalize to locate novel target objects with zero-shot training. Previous work has focused on searching for perfect matches of a target after extensive category-specific training. Here we show for the first time that humans can efficiently and invariantly search for natural objects in complex scenes. To gain insight into the mechanisms that guide visual search, we propose a biologically inspired computational model that can locate targets without exhaustive sampling and generalize to novel objects. The model provides an approximation to the mechanisms integrating bottom-up and top-down signals during search in natural scenes.