 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Video Corpus Moment Retrieval with Partial Relevance Enhancement
Feb 21, 2024Video corpus moment retrieval~(VCMR) is a new video retrieval task aimed at retrieving a relevant moment from a large corpus of untrimmed videos using a natural language text as query. The relevance between the video and query is partial, mainly evident in two aspects: (1) Scope: The untrimmed video contains information-rich frames, and not all are relevant to the query. Strong correlation is typically observed only within the relevant moment, emphasizing the importance of capturing key content. (2) Modality: The relevance of query to different modalities varies; action descriptions align more with the visual elements, while character conversations are more related to textual information. Recognizing and addressing these modality-specific nuances is crucial for effective retrieval in VCMR. However, existing methods often treat all video contents equally, leading to sub-optimal moment retrieval. We argue that effectively capturing the partial relevance between the query and video is essential for the VCMR task. To this end, we propose a Partial Relevance Enhanced Model~(PREM) to improve VCMR. VCMR involves two sub-tasks: video retrieval and moment localization. To align with their distinct objectives, we implement specialized partial relevance enhancement strategies. For video retrieval, we introduce a multi-modal collaborative video retriever, generating distinct query representations tailored for different modalities by modality-specific pooling, ensuring a more effective match. For moment localization, we propose the focus-then-fuse moment localizer, utilizing modality-specific gates to capture essential content, followed by fusing multi-modal information for moment localization. Experimental results on TVR and DiDeMo datasets show that the proposed model outperforms the baselines, achieving a new state-of-the-art of VCMR.
Event-aware Video Corpus Moment Retrieval
Feb 21, 2024



Video Corpus Moment Retrieval (VCMR) is a practical video retrieval task focused on identifying a specific moment within a vast corpus of untrimmed videos using the natural language query. Existing methods for VCMR typically rely on frame-aware video retrieval, calculating similarities between the query and video frames to rank videos based on maximum frame similarity.However, this approach overlooks the semantic structure embedded within the information between frames, namely, the event, a crucial element for human comprehension of videos. Motivated by this, we propose EventFormer, a model that explicitly utilizes events within videos as fundamental units for video retrieval. The model extracts event representations through event reasoning and hierarchical event encoding. The event reasoning module groups consecutive and visually similar frame representations into events, while the hierarchical event encoding encodes information at both the frame and event levels. We also introduce anchor multi-head self-attenion to encourage Transformer to capture the relevance of adjacent content in the video. The training of EventFormer is conducted by two-branch contrastive learning and dual optimization for two sub-tasks of VCMR. Extensive experiments on TVR, ANetCaps, and DiDeMo benchmarks show the effectiveness and efficiency of EventFormer in VCMR, achieving new state-of-the-art results. Additionally, the effectiveness of EventFormer is also validated on partially relevant video retrieval task.
AI-Generated Images Introduce Invisible Relevance Bias to Text-Image Retrieval
Nov 27, 2023With the advancement of generation models, AI-generated content (AIGC) is becoming more realistic, flooding the Internet. A recent study suggests that this phenomenon has elevated the issue of source bias in text retrieval for web searches. Specifically, neural retrieval models tend to rank generated texts higher than human-written texts. In this paper, we extend the study of this bias to cross-modal retrieval. Firstly, we successfully construct a suitable benchmark to explore the existence of the bias. Subsequent extensive experiments on this benchmark reveal that AI-generated images introduce an invisible relevance bias to text-image retrieval models. Specifically, our experiments show that text-image retrieval models tend to rank the AI-generated images higher than the real images, even though the AI-generated images do not exhibit more visually relevant features to the query than real images. This invisible relevance bias is prevalent across retrieval models with varying training data and architectures. Furthermore, our subsequent exploration reveals that the inclusion of AI-generated images in the training data of the retrieval models exacerbates the invisible relevance bias. The above phenomenon triggers a vicious cycle, which makes the invisible relevance bias become more and more serious. To elucidate the potential causes of invisible relevance and address the aforementioned issues, we introduce an effective training method aimed at alleviating the invisible relevance bias. Subsequently, we apply our proposed debiasing method to retroactively identify the causes of invisible relevance, revealing that the AI-generated images induce the image encoder to embed additional information into their representation. This information exhibits a certain consistency across generated images with different semantics and can make the retriever estimate a higher relevance score.
Multi-video Moment Ranking with Multimodal Clue
Jan 29, 2023Video corpus moment retrieval~(VCMR) is the task of retrieving a relevant video moment from a large corpus of untrimmed videos via a natural language query. State-of-the-art work for VCMR is based on two-stage method. In this paper, we focus on improving two problems of two-stage method: (1) Moment prediction bias: The predicted moments for most queries come from the top retrieved videos, ignoring the possibility that the target moment is in the bottom retrieved videos, which is caused by the inconsistency of Shared Normalization during training and inference. (2) Latent key content: Different modalities of video have different key information for moment localization. To this end, we propose a two-stage model \textbf{M}ult\textbf{I}-video ra\textbf{N}king with m\textbf{U}l\textbf{T}imodal clu\textbf{E}~(MINUTE). MINUTE uses Shared Normalization during both training and inference to rank candidate moments from multiple videos to solve moment predict bias, making it more efficient to predict target moment. In addition, Mutilmdaol Clue Mining~(MCM) of MINUTE can discover key content of different modalities in video to localize moment more accurately. MINUTE outperforms the baselines on TVR and DiDeMo datasets, achieving a new state-of-the-art of VCMR. Our code will be available at GitHub.
WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training
Mar 19, 2021
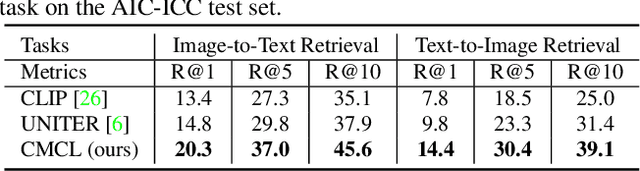
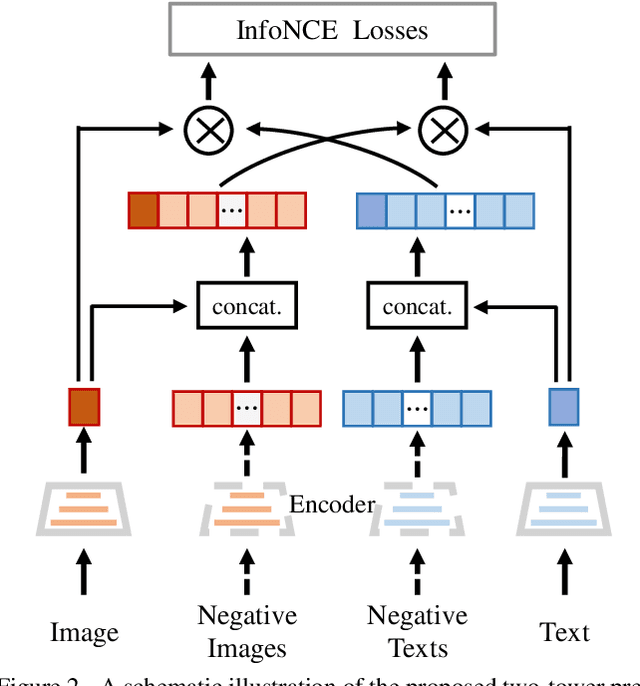
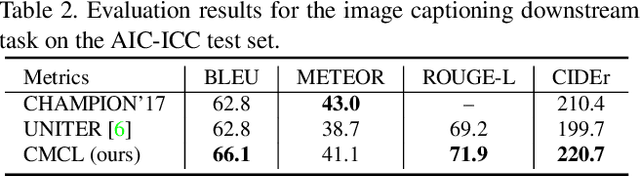
Multi-modal pre-training models have been intensively explored to bridge vision and language in recent years. However, most of them explicitly model the cross-modal interaction between image-text pairs, by assuming that there exists strong semantic correlation between the text and image modalities. Since this strong assumption is often invalid in real-world scenarios, we choose to implicitly model the cross-modal correlation for large-scale multi-modal pre-training, which is the focus of the Chinese project `WenLan' led by our team. Specifically, with the weak correlation assumption over image-text pairs, we propose a two-tower pre-training model called BriVL within the cross-modal contrastive learning framework. Unlike OpenAI CLIP that adopts a simple contrastive learning method, we devise a more advanced algorithm by adapting the latest method MoCo into the cross-modal scenario. By building a large queue-based dictionary, our BriVL can incorporate more negative samples in limited GPU resources. We further construct a large Chinese multi-source image-text dataset called RUC-CAS-WenLan for pre-training our BriVL model. Extensive experiments demonstrate that the pre-trained BriVL model outperforms both UNITER and OpenAI CLIP on various downstream tasks.