 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptagator: Few-shot Dense Retrieval From 8 Examples
Sep 23, 2022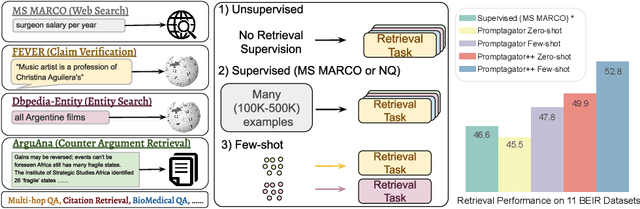
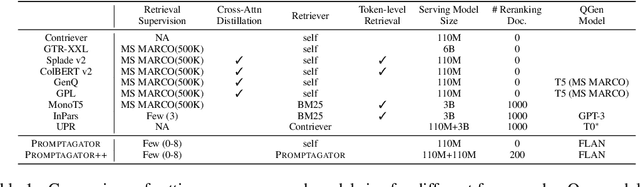
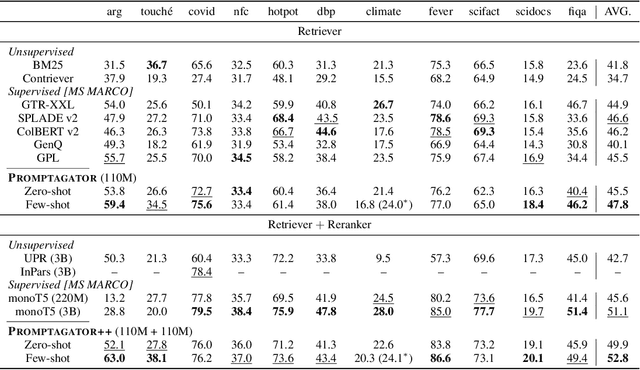
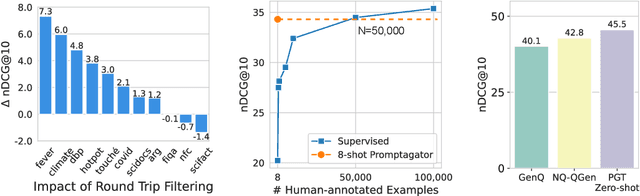
Much recent research on information retrieval has focused on how to transfer from one task (typically with abundant supervised data) to various other tasks where supervision is limited, with the implicit assumption that it is possible to generalize from one task to all the rest. However, this overlooks the fact that there are many diverse and unique retrieval tasks, each targeting different search intents, queries, and search domains. In this paper, we suggest to work on Few-shot Dense Retrieval, a setting where each task comes with a short description and a few examples. To amplify the power of a few examples, we propose Prompt-base Query Generation for Retriever (Promptagator), which leverages large language models (LLM) as a few-shot query generator, and creates task-specific retrievers based on the generated data. Powered by LLM's generalization ability, Promptagator makes it possible to create task-specific end-to-end retrievers solely based on a few examples {without} using Natural Questions or MS MARCO to train %question generators or dual encoders. Surprisingly, LLM prompting with no more than 8 examples allows dual encoders to outperform heavily engineered models trained on MS MARCO like ColBERT v2 by more than 1.2 nDCG on average on 11 retrieval sets. Further training standard-size re-rankers using the same generated data yields another 5.0 point nDCG improvement. Our studies determine that query generation can be far more effective than previously observed, especially when a small amount of task-specific knowledge is given.
Large Dual Encoders Are Generalizable Retrievers
Dec 15, 2021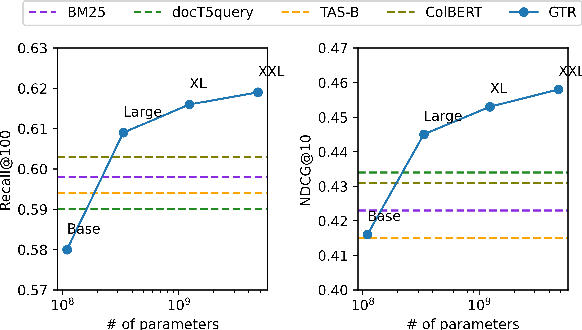
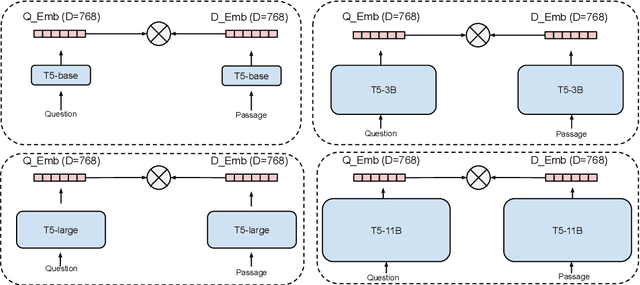

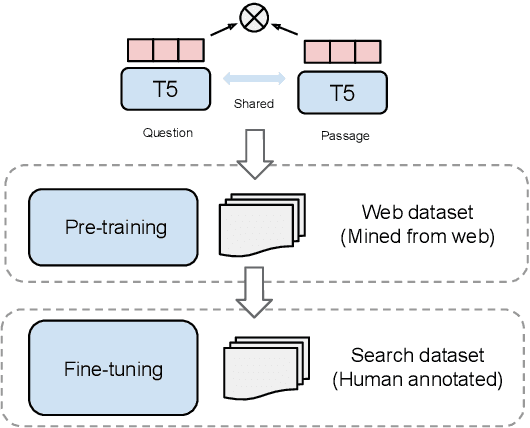
It has been shown that dual encoders trained on one domain often fail to generalize to other domains for retrieval tasks. One widespread belief is that the bottleneck layer of a dual encoder, where the final score is simply a dot-product between a query vector and a passage vector, is too limited to make dual encoders an effective retrieval model for out-of-domain generalization. In this paper, we challenge this belief by scaling up the size of the dual encoder model {\em while keeping the bottleneck embedding size fixed.} With multi-stage training, surprisingly, scaling up the model size brings significant improvement on a variety of retrieval tasks, especially for out-of-domain generalization. Experimental results show that our dual encoders, \textbf{G}eneralizable \textbf{T}5-based dense \textbf{R}etrievers (GTR), outperform %ColBERT~\cite{khattab2020colbert} and existing sparse and dense retrievers on the BEIR dataset~\cite{thakur2021beir} significantly. Most surprisingly, our ablation study finds that GTR is very data efficient, as it only needs 10\% of MS Marco supervised data to achieve the best out-of-domain performance. All the GTR models are released at https://tfhub.dev/google/collections/gtr/1.
Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models
Aug 26, 2021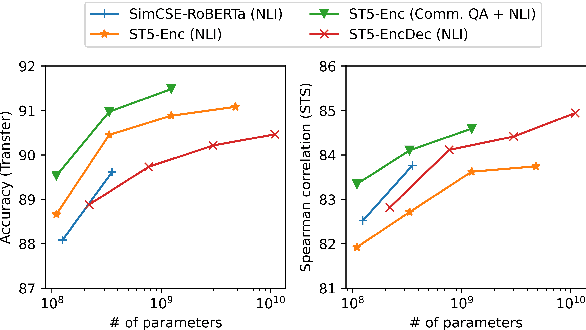
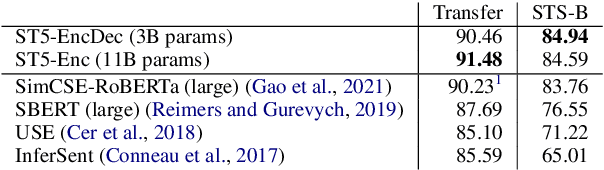
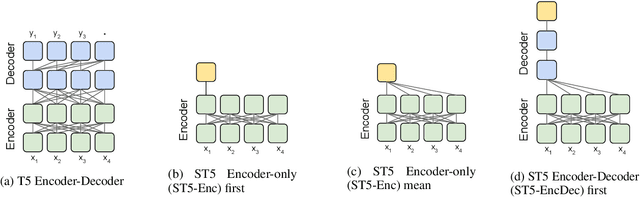
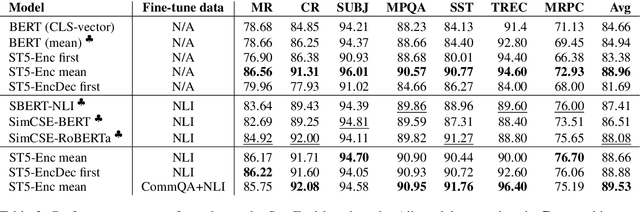
We provide the first exploration of text-to-text transformers (T5) sentence embeddings. Sentence embeddings are broadly useful for language processing tasks. While T5 achieves impressive performance on language tasks cast as sequence-to-sequence mapping problems, it is unclear how to produce sentence embeddings from encoder-decoder models. We investigate three methods for extracting T5 sentence embeddings: two utilize only the T5 encoder and one uses the full T5 encoder-decoder model. Our encoder-only models outperforms BERT-based sentence embeddings on both transfer tasks and semantic textual similarity (STS). Our encoder-decoder method achieves further improvement on STS. Scaling up T5 from millions to billions of parameters is found to produce consistent improvements on downstream tasks. Finally, we introduce a two-stage contrastive learning approach that achieves a new state-of-art on STS using sentence embeddings, outperforming both Sentence BERT and SimCSE.