 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePool-Select-Refine: Allocation-Aware Generative Dataset Distillation with Soft-Label-Guided Latent Refinement
Jun 01, 2026Diffusion-based dataset distillation has recently emerged as a promising paradigm for condensing large-scale datasets into compact synthetic sets. By leveraging pretrained generative priors, these methods can produce realistic class-conditional samples more efficiently than traditional matching-based approaches. However, most existing diffusion-based methods still adopt a rigid ``Generate-and-Use'' strategy, where the generated samples are directly treated as the final distilled set under a fixed images-per-class budget. Such a design tightly couples candidate generation with final budget allocation, which may result in redundant waste of the limited budget or insufficiently informative samples. In this paper, we propose ``Pool-Select-Refine'', a two-stage framework for allocation-aware generative dataset distillation. First, instead of directly using a fixed number of generated samples, we construct an over-complete candidate pool and select a compact subset under the target budget. Second, we refine the selected samples in latent space using soft-label supervision derived from the teacher model, improving semantic alignment while preserving the generative prior. This design explicitly decouples generation, selection, and refinement, enabling more effective use of the distillation budget. Experiments on large-scale and fine-grained image classification benchmarks show that the proposed framework delivers consistent gains over diffusion-based baselines. The results suggest that introducing a curation stage before refinement is a simple yet effective way to improve diffusion-based dataset distillation.
Seaweed-7B: Cost-Effective Training of Video Generation Foundation Model
Apr 11, 2025
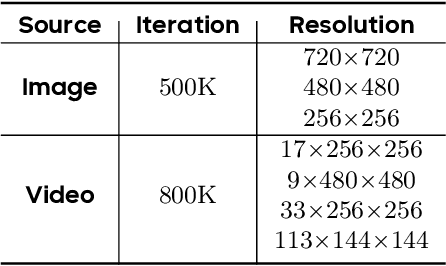
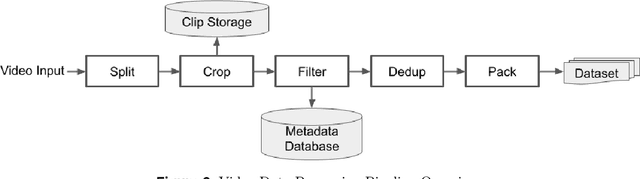

This technical report presents a cost-efficient strategy for training a video generation foundation model. We present a mid-sized research model with approximately 7 billion parameters (7B) called Seaweed-7B trained from scratch using 665,000 H100 GPU hours. Despite being trained with moderate computational resources, Seaweed-7B demonstrates highly competitive performance compared to contemporary video generation models of much larger size. Design choices are especially crucial in a resource-constrained setting. This technical report highlights the key design decisions that enhance the performance of the medium-sized diffusion model. Empirically, we make two observations: (1) Seaweed-7B achieves performance comparable to, or even surpasses, larger models trained on substantially greater GPU resources, and (2) our model, which exhibits strong generalization ability, can be effectively adapted across a wide range of downstream applications either by lightweight fine-tuning or continue training. See the project page at https://seaweed.video/
What If the TV Was Off? Examining Counterfactual Reasoning Abilities of Multi-modal Language Models
Oct 10, 2023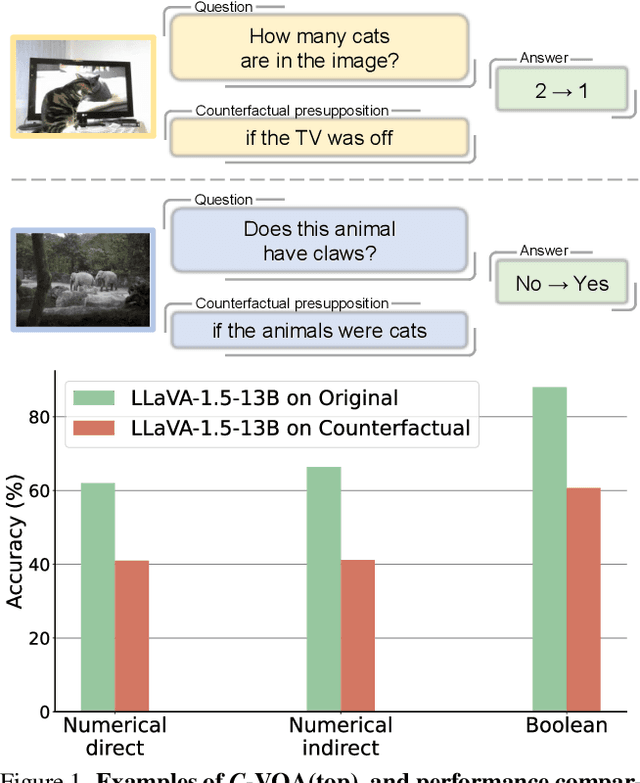
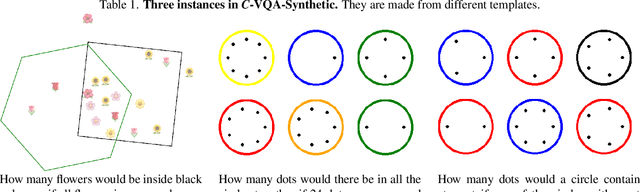
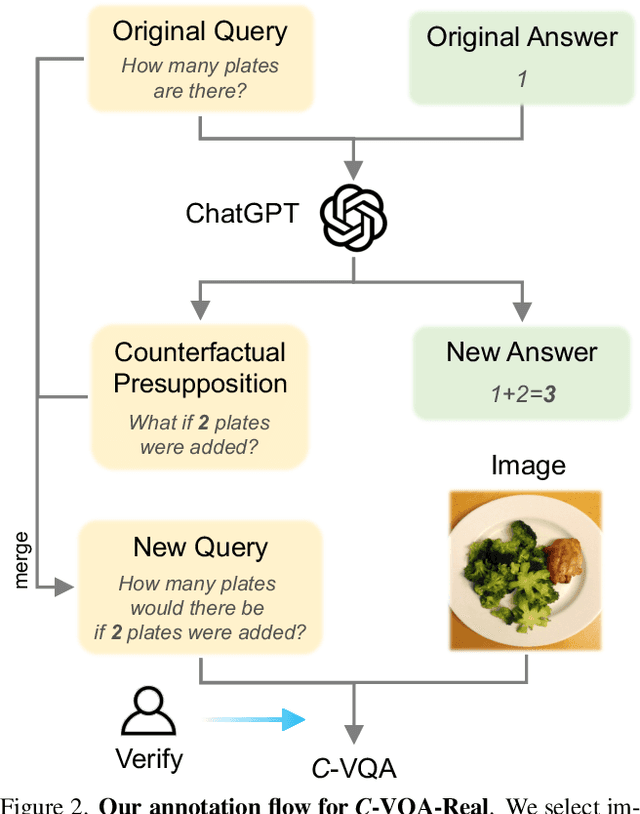

Counterfactual reasoning ability is one of the core abilities of human intelligence. This reasoning process involves the processing of alternatives to observed states or past events, and this process can improve our ability for planning and decision-making. In this work, we focus on benchmarking the counterfactual reasoning ability of multi-modal large language models. We take the question and answer pairs from the VQAv2 dataset and add one counterfactual presupposition to the questions, with the answer being modified accordingly. After generating counterfactual questions and answers using ChatGPT, we manually examine all generated questions and answers to ensure correctness. Over 2k counterfactual question and answer pairs are collected this way. We evaluate recent vision language models on our newly collected test dataset and found that all models exhibit a large performance drop compared to the results tested on questions without the counterfactual presupposition. This result indicates that there still exists space for developing vision language models. Apart from the vision language models, our proposed dataset can also serves as a benchmark for evaluating the ability of code generation LLMs, results demonstrate a large gap between GPT-4 and current open-source models. Our code and dataset are available at \url{https://github.com/Letian2003/C-VQA}.
SIM2E: Benchmarking the Group Equivariant Capability of Correspondence Matching Algorithms
Aug 21, 2022
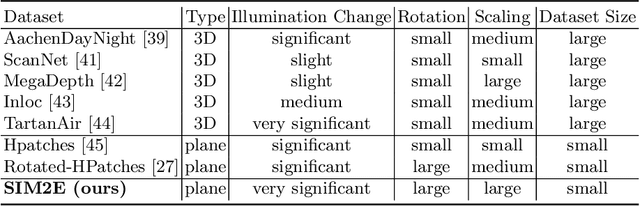

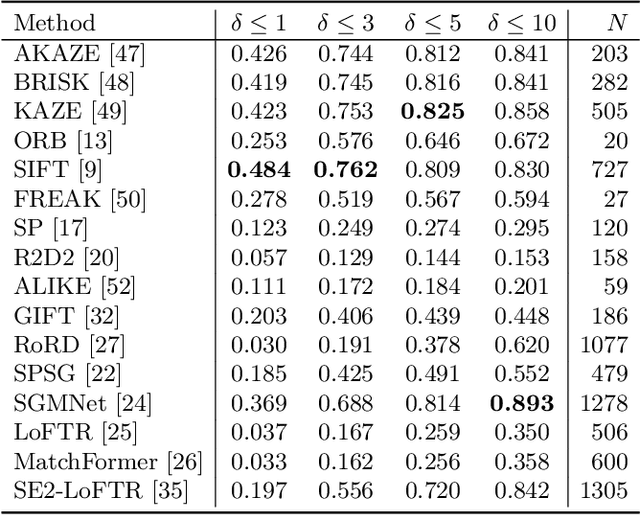
Correspondence matching is a fundamental problem in computer vision and robotics applications. Solving correspondence matching problems using neural networks has been on the rise recently. Rotation-equivariance and scale-equivariance are both critical in correspondence matching applications. Classical correspondence matching approaches are designed to withstand scaling and rotation transformations. However, the features extracted using convolutional neural networks (CNNs) are only translation-equivariant to a certain extent. Recently, researchers have strived to improve the rotation-equivariance of CNNs based on group theories. Sim(2) is the group of similarity transformations in the 2D plane. This paper presents a specialized dataset dedicated to evaluating sim(2)-equivariant correspondence matching algorithms. We compare the performance of 16 state-of-the-art (SoTA) correspondence matching approaches. The experimental results demonstrate the importance of group equivariant algorithms for correspondence matching on various sim(2) transformation conditions. Since the subpixel accuracy achieved by CNN-based correspondence matching approaches is unsatisfactory, this specific area requires more attention in future works. Our dataset is publicly available at: mias.group/SIM2E.
XCon: Learning with Experts for Fine-grained Category Discovery
Aug 03, 2022

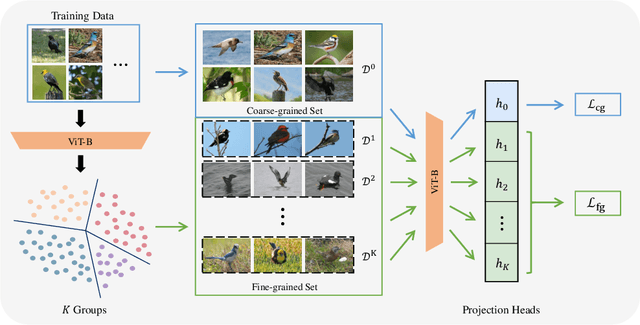
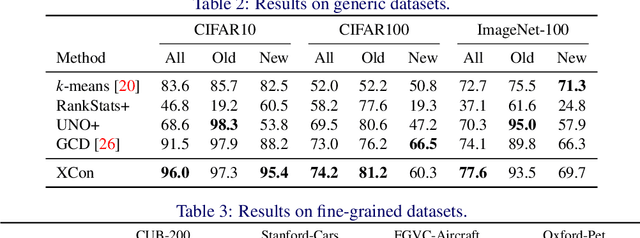
We address the problem of generalized category discovery (GCD) in this paper, i.e. clustering the unlabeled images leveraging the information from a set of seen classes, where the unlabeled images could contain both seen classes and unseen classes. The seen classes can be seen as an implicit criterion of classes, which makes this setting different from unsupervised clustering where the cluster criteria may be ambiguous. We mainly concern the problem of discovering categories within a fine-grained dataset since it is one of the most direct applications of category discovery, i.e. helping experts discover novel concepts within an unlabeled dataset using the implicit criterion set forth by the seen classes. State-of-the-art methods for generalized category discovery leverage contrastive learning to learn the representations, but the large inter-class similarity and intra-class variance pose a challenge for the methods because the negative examples may contain irrelevant cues for recognizing a category so the algorithms may converge to a local-minima. We present a novel method called Expert-Contrastive Learning (XCon) to help the model to mine useful information from the images by first partitioning the dataset into sub-datasets using k-means clustering and then performing contrastive learning on each of the sub-datasets to learn fine-grained discriminative features. Experiments on fine-grained datasets show a clear improved performance over the previous best methods, indicating the effectiveness of our method.