 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat If the TV Was Off? Examining Counterfactual Reasoning Abilities of Multi-modal Language Models
Oct 10, 2023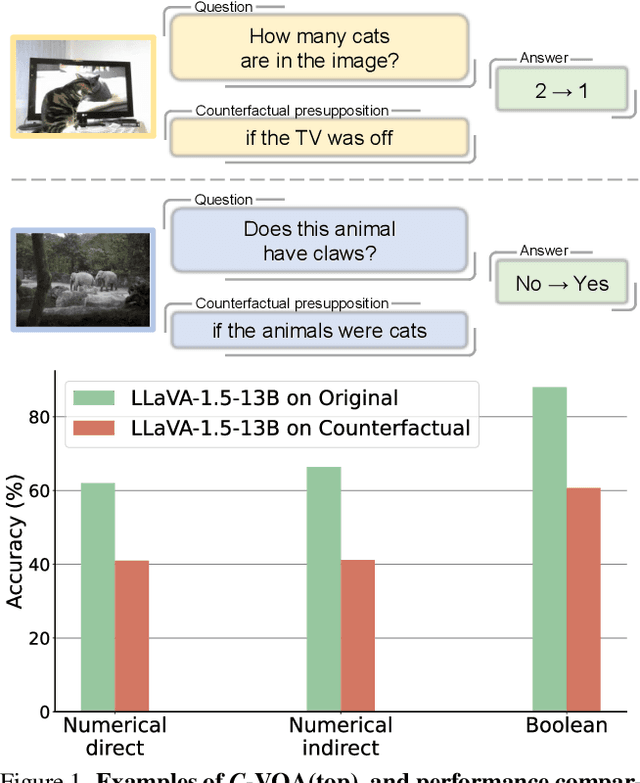
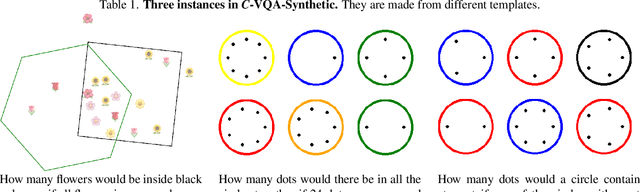
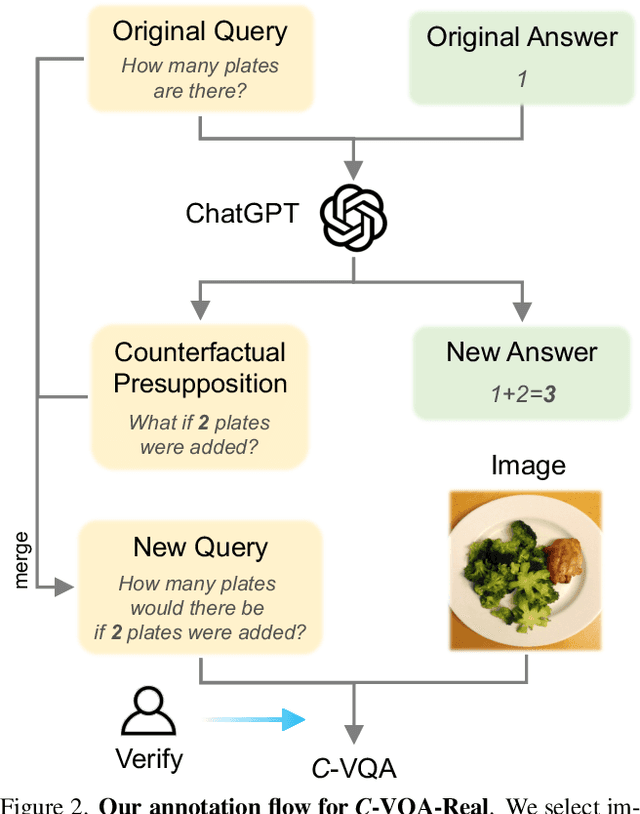

Counterfactual reasoning ability is one of the core abilities of human intelligence. This reasoning process involves the processing of alternatives to observed states or past events, and this process can improve our ability for planning and decision-making. In this work, we focus on benchmarking the counterfactual reasoning ability of multi-modal large language models. We take the question and answer pairs from the VQAv2 dataset and add one counterfactual presupposition to the questions, with the answer being modified accordingly. After generating counterfactual questions and answers using ChatGPT, we manually examine all generated questions and answers to ensure correctness. Over 2k counterfactual question and answer pairs are collected this way. We evaluate recent vision language models on our newly collected test dataset and found that all models exhibit a large performance drop compared to the results tested on questions without the counterfactual presupposition. This result indicates that there still exists space for developing vision language models. Apart from the vision language models, our proposed dataset can also serves as a benchmark for evaluating the ability of code generation LLMs, results demonstrate a large gap between GPT-4 and current open-source models. Our code and dataset are available at \url{https://github.com/Letian2003/C-VQA}.