 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT-based Multi-Task Model for Country and Province Level Modern Standard Arabic and Dialectal Arabic Identification
Paper and Code
Jun 23, 2021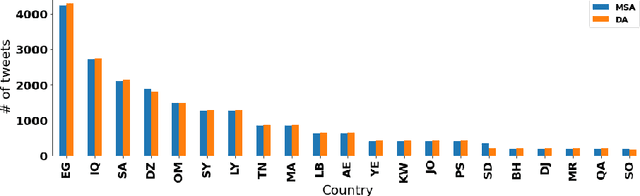

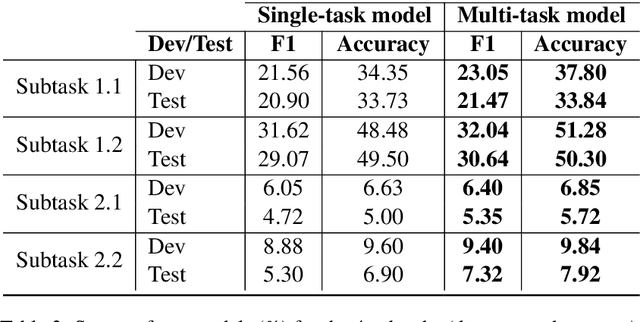
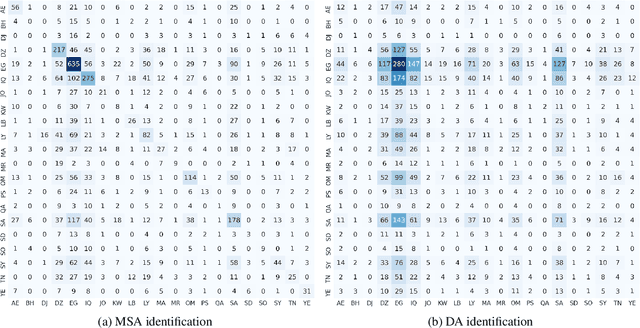
Dialect and standard language identification are crucial tasks for many Arabic natural language processing applications. In this paper, we present our deep learning-based system, submitted to the second NADI shared task for country-level and province-level identification of Modern Standard Arabic (MSA) and Dialectal Arabic (DA). The system is based on an end-to-end deep Multi-Task Learning (MTL) model to tackle both country-level and province-level MSA/DA identification. The latter MTL model consists of a shared Bidirectional Encoder Representation Transformers (BERT) encoder, two task-specific attention layers, and two classifiers. Our key idea is to leverage both the task-discriminative and the inter-task shared features for country and province MSA/DA identification. The obtained results show that our MTL model outperforms single-task models on most subtasks.