 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Multi-Task Models for Misogyny Identification and Categorization on Arabic Social Media
Jun 16, 2022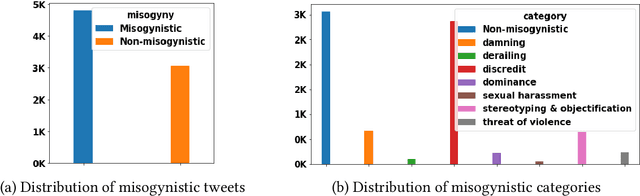
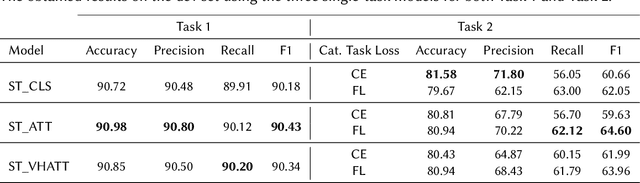
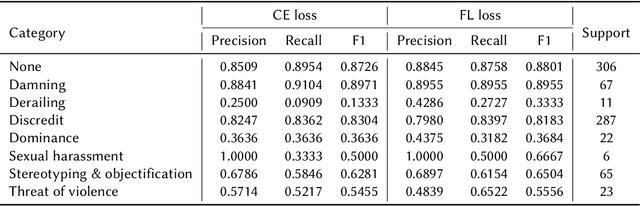
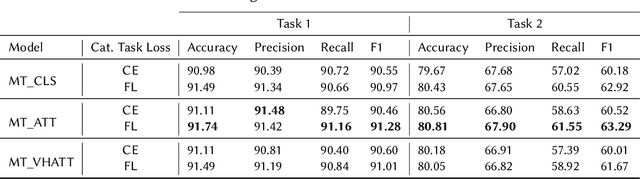
The prevalence of toxic content on social media platforms, such as hate speech, offensive language, and misogyny, presents serious challenges to our interconnected society. These challenging issues have attracted widespread attention in Natural Language Processing (NLP) community. In this paper, we present the submitted systems to the first Arabic Misogyny Identification shared task. We investigate three multi-task learning models as well as their single-task counterparts. In order to encode the input text, our models rely on the pre-trained MARBERT language model. The overall obtained results show that all our submitted models have achieved the best performances (top three ranked submissions) in both misogyny identification and categorization tasks.