 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-Arguments Extraction Corpus and Modeling using BERT for Arabic
Jul 30, 2024

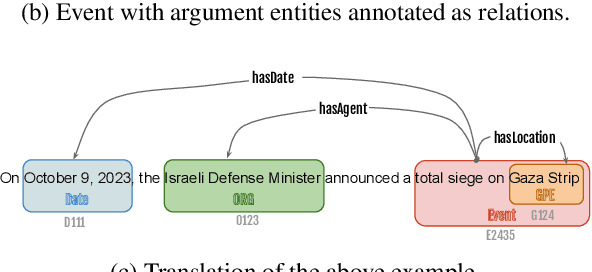

Event-argument extraction is a challenging task, particularly in Arabic due to sparse linguistic resources. To fill this gap, we introduce the \hadath corpus ($550$k tokens) as an extension of Wojood, enriched with event-argument annotations. We used three types of event arguments: $agent$, $location$, and $date$, which we annotated as relation types. Our inter-annotator agreement evaluation resulted in $82.23\%$ $Kappa$ score and $87.2\%$ $F_1$-score. Additionally, we propose a novel method for event relation extraction using BERT, in which we treat the task as text entailment. This method achieves an $F_1$-score of $94.01\%$. To further evaluate the generalization of our proposed method, we collected and annotated another out-of-domain corpus (about $80$k tokens) called \testNLI and used it as a second test set, on which our approach achieved promising results ($83.59\%$ $F_1$-score). Last but not least, we propose an end-to-end system for event-arguments extraction. This system is implemented as part of SinaTools, and both corpora are publicly available at {\small \url{https://sina.birzeit.edu/wojood}}
Sina at FigNews 2024: Multilingual Datasets Annotated with Bias and Propaganda
Jul 12, 2024The proliferation of bias and propaganda on social media is an increasingly significant concern, leading to the development of techniques for automatic detection. This article presents a multilingual corpus of 12, 000 Facebook posts fully annotated for bias and propaganda. The corpus was created as part of the FigNews 2024 Shared Task on News Media Narratives for framing the Israeli War on Gaza. It covers various events during the War from October 7, 2023 to January 31, 2024. The corpus comprises 12, 000 posts in five languages (Arabic, Hebrew, English, French, and Hindi), with 2, 400 posts for each language. The annotation process involved 10 graduate students specializing in Law. The Inter-Annotator Agreement (IAA) was used to evaluate the annotations of the corpus, with an average IAA of 80.8% for bias and 70.15% for propaganda annotations. Our team was ranked among the bestperforming teams in both Bias and Propaganda subtasks. The corpus is open-source and available at https://sina.birzeit.edu/fada