 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNADI 2022: The Third Nuanced Arabic Dialect Identification Shared Task
Paper and Code


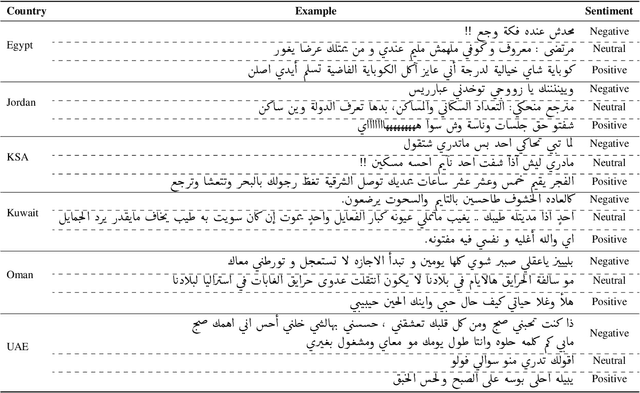
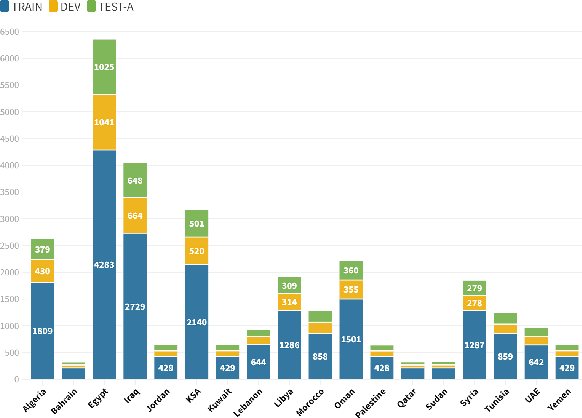
We describe findings of the third Nuanced Arabic Dialect Identification Shared Task (NADI 2022). NADI aims at advancing state of the art Arabic NLP, including on Arabic dialects. It does so by affording diverse datasets and modeling opportunities in a standardized context where meaningful comparisons between models and approaches are possible. NADI 2022 targeted both dialect identification (Subtask 1) and dialectal sentiment analysis (Subtask 2) at the country level. A total of 41 unique teams registered for the shared task, of whom 21 teams have actually participated (with 105 valid submissions). Among these, 19 teams participated in Subtask 1 and 10 participated in Subtask 2. The winning team achieved 27.06 F1 on Subtask 1 and F1=75.16 on Subtask 2, reflecting that the two subtasks remain challenging and motivating future work in this area. We describe methods employed by participating teams and offer an outlook for NADI.