 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHalluSearch at SemEval-2025 Task 3: A Search-Enhanced RAG Pipeline for Hallucination Detection
Apr 14, 2025

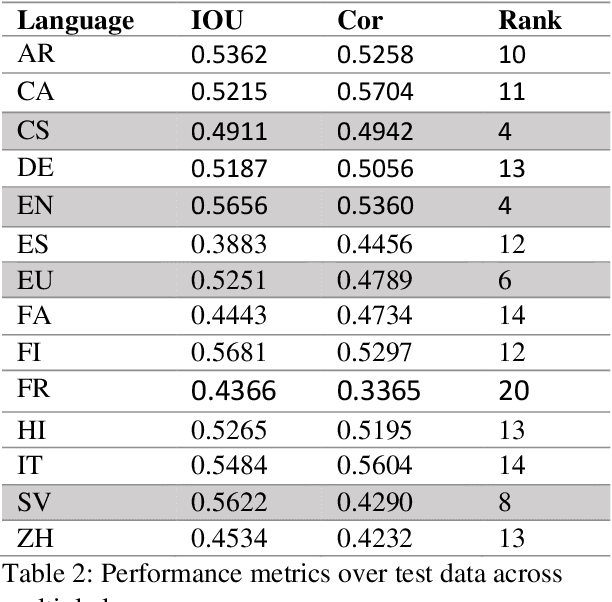
In this paper, we present HalluSearch, a multilingual pipeline designed to detect fabricated text spans in Large Language Model (LLM) outputs. Developed as part of Mu-SHROOM, the Multilingual Shared-task on Hallucinations and Related Observable Overgeneration Mistakes, HalluSearch couples retrieval-augmented verification with fine-grained factual splitting to identify and localize hallucinations in fourteen different languages. Empirical evaluations show that HalluSearch performs competitively, placing fourth in both English (within the top ten percent) and Czech. While the system's retrieval-based strategy generally proves robust, it faces challenges in languages with limited online coverage, underscoring the need for further research to ensure consistent hallucination detection across diverse linguistic contexts.
Exploring Retrieval Augmented Generation in Arabic
Aug 14, 2024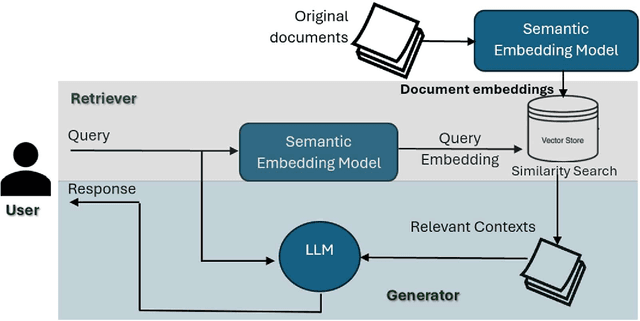



Recently, Retrieval Augmented Generation (RAG) has emerged as a powerful technique in natural language processing, combining the strengths of retrieval-based and generation-based models to enhance text generation tasks. However, the application of RAG in Arabic, a language with unique characteristics and resource constraints, remains underexplored. This paper presents a comprehensive case study on the implementation and evaluation of RAG for Arabic text. The work focuses on exploring various semantic embedding models in the retrieval stage and several LLMs in the generation stage, in order to investigate what works and what doesn't in the context of Arabic. The work also touches upon the issue of variations between document dialect and query dialect in the retrieval stage. Results show that existing semantic embedding models and LLMs can be effectively employed to build Arabic RAG pipelines.