 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClone-Seeker: Effective Code Clone Search Using Annotations
Jun 06, 2021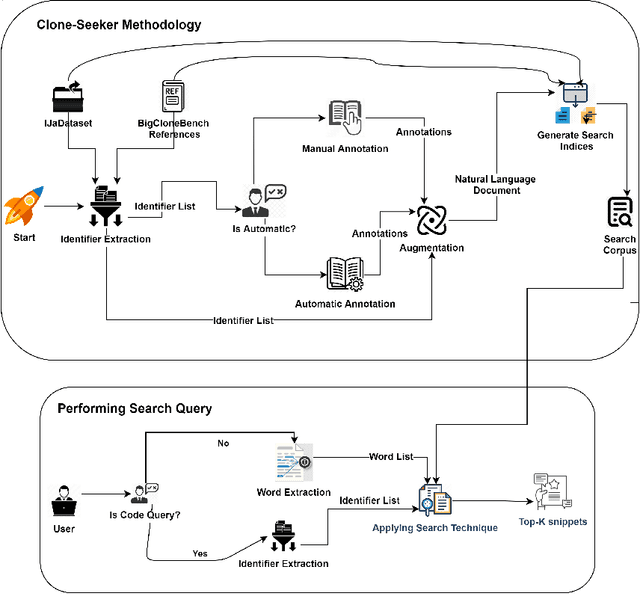
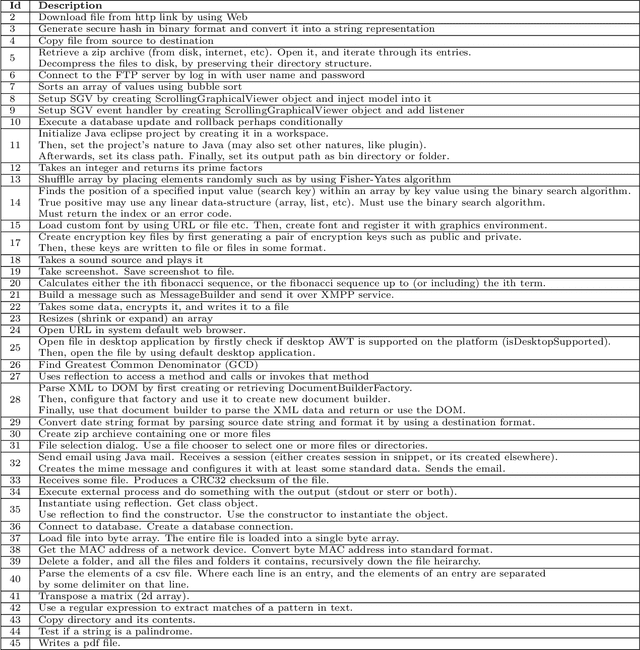

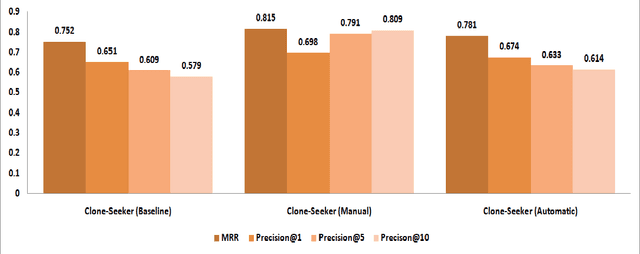
Source code search plays an important role in software development, e.g. for exploratory development or opportunistic reuse of existing code from a code base. Often, exploration of different implementations with the same functionality is needed for tasks like automated software transplantation, software diversification, and software repair. Code clones, which are syntactically or semantically similar code fragments, are perfect candidates for such tasks. Searching for code clones involves a given search query to retrieve the relevant code fragments. We propose a novel approach called Clone-Seeker that focuses on utilizing clone class features in retrieving code clones. For this purpose, we generate metadata for each code clone in the form of a natural language document. The metadata includes a pre-processed list of identifiers from the code clones augmented with a list of keywords indicating the semantics of the code clone. This keyword list can be extracted from a manually annotated general description of the clone class, or automatically generated from the source code of the entire clone class. This approach helps developers to perform code clone search based on a search query written either as source code terms, or as natural language. In our quantitative evaluation, we show that (1) Clone-Seeker has a higher recall when searching for semantic code clones (i.e., Type-4) in BigCloneBench than the state-of-the-art; and (2) Clone-Seeker can accurately search for relevant code clones by applying natural language queries.
Combining Lexical Features and a Supervised Learning Approach for Arabic Sentiment Analysis
Oct 23, 2017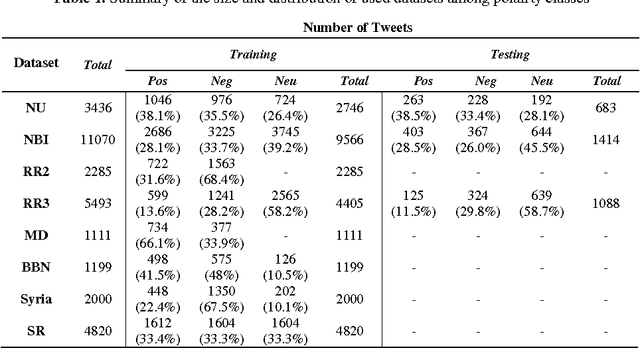
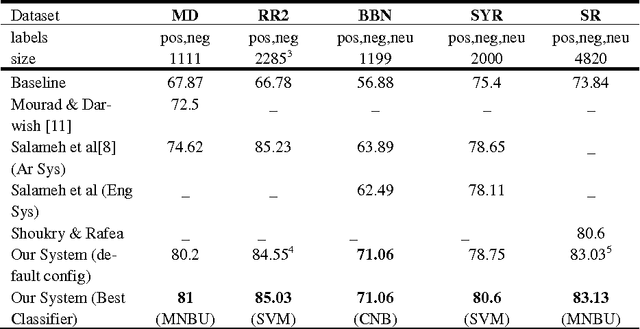
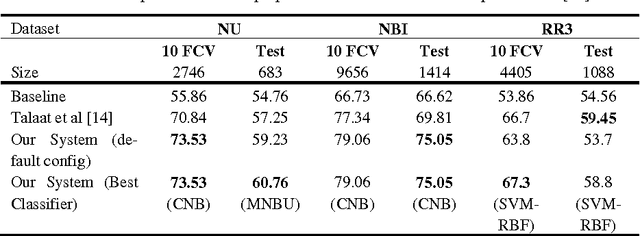
The importance of building sentiment analysis tools for Arabic social media has been recognized during the past couple of years, especially with the rapid increase in the number of Arabic social media users. One of the main difficulties in tackling this problem is that text within social media is mostly colloquial, with many dialects being used within social media platforms. In this paper, we present a set of features that were integrated with a machine learning based sentiment analysis model and applied on Egyptian, Saudi, Levantine, and MSA Arabic social media datasets. Many of the proposed features were derived through the use of an Arabic Sentiment Lexicon. The model also presents emoticon based features, as well as input text related features such as the number of segments within the text, the length of the text, whether the text ends with a question mark or not, etc. We show that the presented features have resulted in an increased accuracy across six of the seven datasets we've experimented with and which are all benchmarked. Since the developed model out-performs all existing Arabic sentiment analysis systems that have publicly available datasets, we can state that this model presents state-of-the-art in Arabic sentiment analysis.