 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClone-Seeker: Effective Code Clone Search Using Annotations
Jun 06, 2021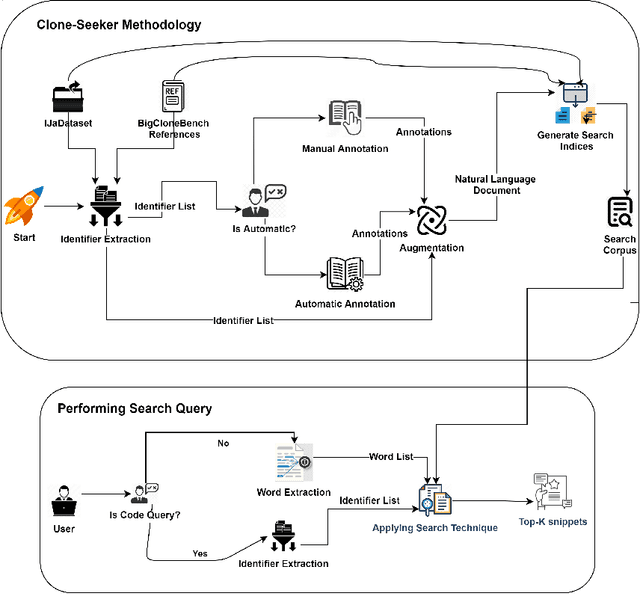
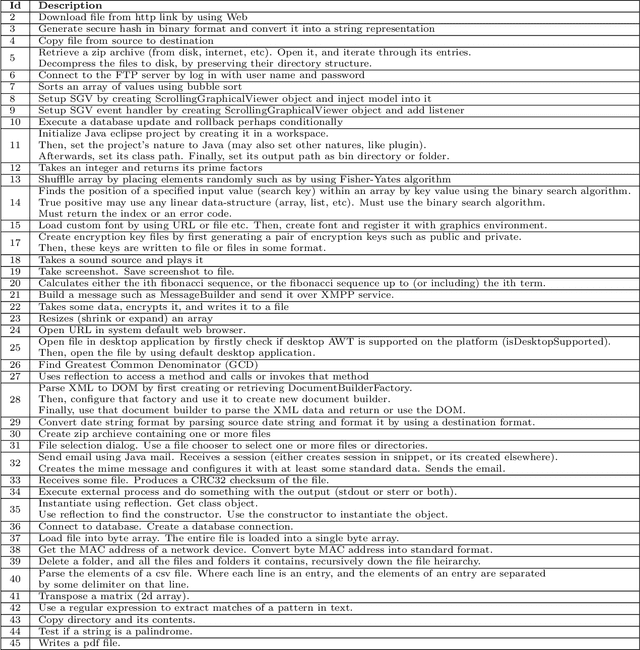

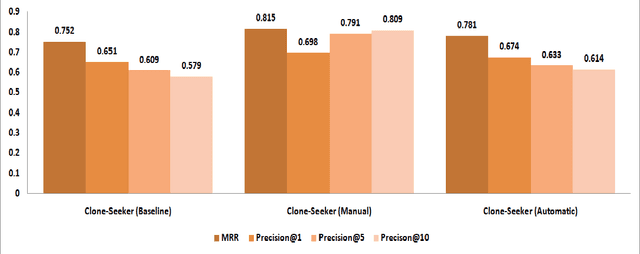
Source code search plays an important role in software development, e.g. for exploratory development or opportunistic reuse of existing code from a code base. Often, exploration of different implementations with the same functionality is needed for tasks like automated software transplantation, software diversification, and software repair. Code clones, which are syntactically or semantically similar code fragments, are perfect candidates for such tasks. Searching for code clones involves a given search query to retrieve the relevant code fragments. We propose a novel approach called Clone-Seeker that focuses on utilizing clone class features in retrieving code clones. For this purpose, we generate metadata for each code clone in the form of a natural language document. The metadata includes a pre-processed list of identifiers from the code clones augmented with a list of keywords indicating the semantics of the code clone. This keyword list can be extracted from a manually annotated general description of the clone class, or automatically generated from the source code of the entire clone class. This approach helps developers to perform code clone search based on a search query written either as source code terms, or as natural language. In our quantitative evaluation, we show that (1) Clone-Seeker has a higher recall when searching for semantic code clones (i.e., Type-4) in BigCloneBench than the state-of-the-art; and (2) Clone-Seeker can accurately search for relevant code clones by applying natural language queries.