 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Online Data-Driven Emergency-Response Method for Autonomous Agents in Unforeseen Situations
Dec 17, 2021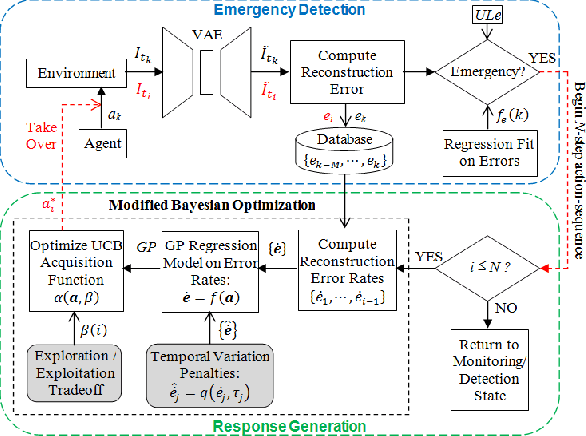
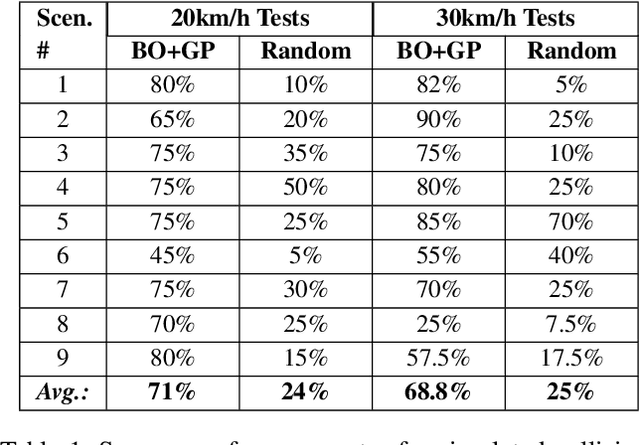

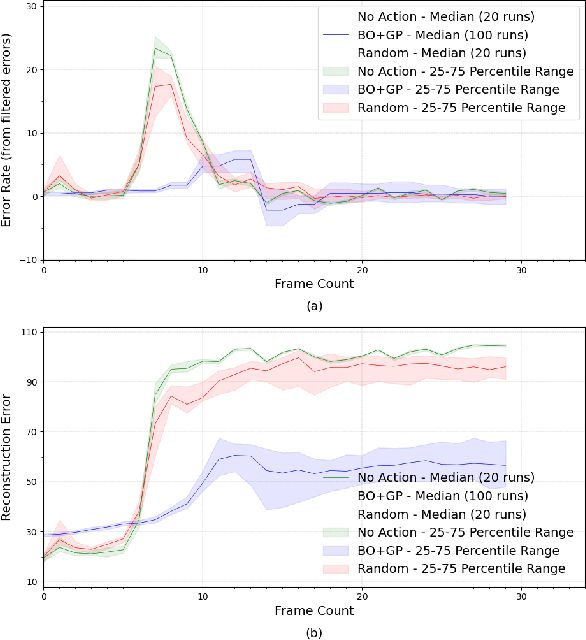
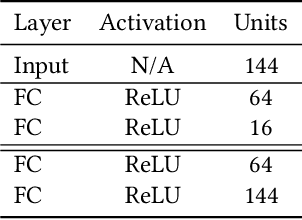
Reinforcement learning agents perform well when presented with inputs within the distribution of those encountered during training. However, they are unable to respond effectively when faced with novel, out-of-distribution events, until they have undergone additional training. This paper presents an online, data-driven, emergency-response method that aims to provide autonomous agents the ability to react to unexpected situations that are very different from those it has been trained or designed to address. In such situations, learned policies cannot be expected to perform appropriately since the observations obtained in these novel situations would fall outside the distribution of inputs that the agent has been optimized to handle. The proposed approach devises a customized response to the unforeseen situation sequentially, by selecting actions that minimize the rate of increase of the reconstruction error from a variational auto-encoder. This optimization is achieved online in a data-efficient manner (on the order of 30 data-points) using a modified Bayesian optimization procedure. We demonstrate the potential of this approach in a simulated 3D car driving scenario, in which the agent devises a response in under 2 seconds to avoid collisions with objects it has not seen during training.
Evolving Inborn Knowledge For Fast Adaptation in Dynamic POMDP Problems
Apr 28, 2020
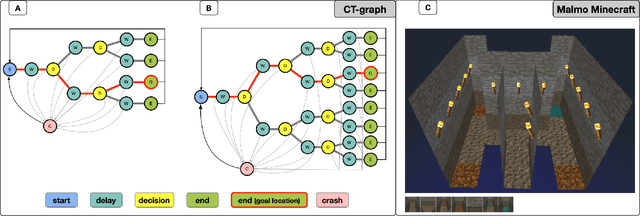
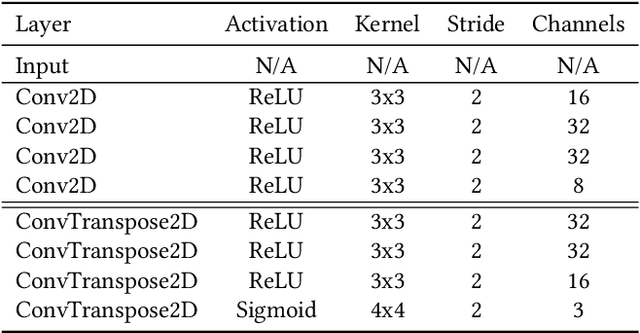
Rapid online adaptation to changing tasks is an important problem in machine learning and, recently, a focus of meta-reinforcement learning. However, reinforcement learning (RL) algorithms struggle in POMDP environments because the state of the system, essential in a RL framework, is not always visible. Additionally, hand-designed meta-RL architectures may not include suitable computational structures for specific learning problems. The evolution of online learning mechanisms, on the contrary, has the ability to incorporate learning strategies into an agent that can (i) evolve memory when required and (ii) optimize adaptation speed to specific online learning problems. In this paper, we exploit the highly adaptive nature of neuromodulated neural networks to evolve a controller that uses the latent space of an autoencoder in a POMDP. The analysis of the evolved networks reveals the ability of the proposed algorithm to acquire inborn knowledge in a variety of aspects such as the detection of cues that reveal implicit rewards, and the ability to evolve location neurons that help with navigation. The integration of inborn knowledge and online plasticity enabled fast adaptation and better performance in comparison to some non-evolutionary meta-reinforcement learning algorithms. The algorithm proved also to succeed in the 3D gaming environment Malmo Minecraft.
Deep Reinforcement Learning with Modulated Hebbian plus Q Network Architecture
Sep 21, 2019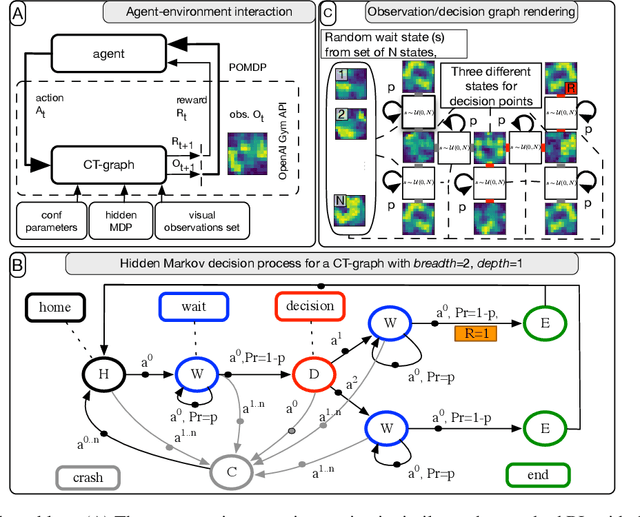
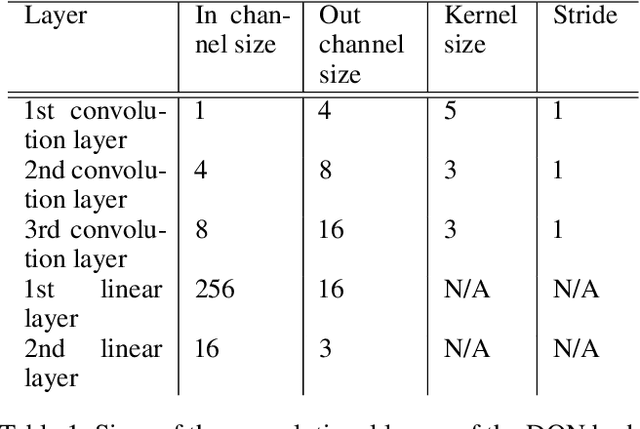
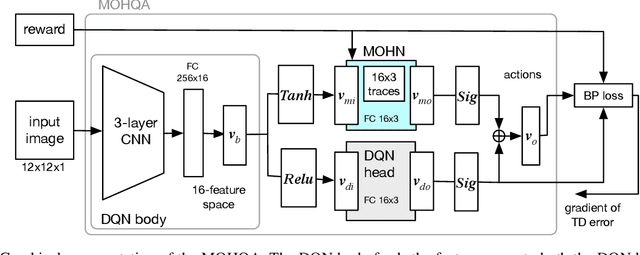
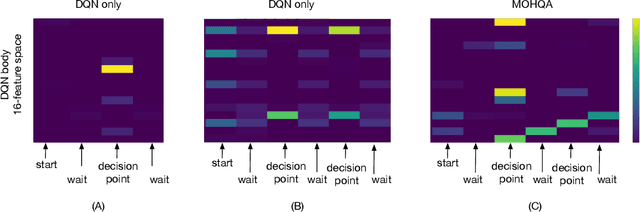
This paper introduces the modulated Hebbian plus Q network architecture (MOHQA) for solving challenging partially observable Markov decision processes (POMDPs) deep reinforcement learning problems with sparse rewards and confounding observations. The proposed architecture combines a deep Q-network (DQN), and a modulated Hebbian network with neural eligibility traces (MOHN). Bio-inspired neural traces are used to bridge temporal delays between actions and rewards. The purpose is to discover distal cause-effect relationships where confounding observations and sparse rewards cause standard RL algorithms to fail. Each of the two modules of the network (DQN and MOHN) is responsible for different aspects of learning. DQN learns low level features and control, while MOHN contributes to the high-level decisions by bridging rewards with past actions. The strength of the approach is to support a DQN standard framework when temporal difference errors are difficult to compute due to non-observable states. The system is tested on a set of generalized decision making problems encoded as decision tree graphs that deliver delayed rewards after key decision points and confounding observations. The simulations show that the proposed approach helps solve problems that are currently challenging for state-of-the-art deep reinforcement learning algorithms.
Generative Continual Concept Learning
Jun 10, 2019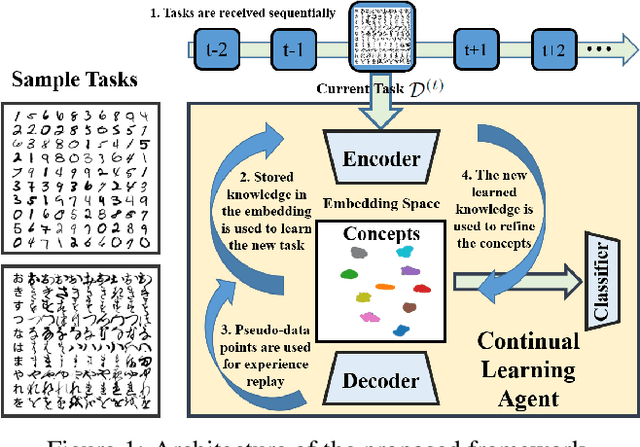
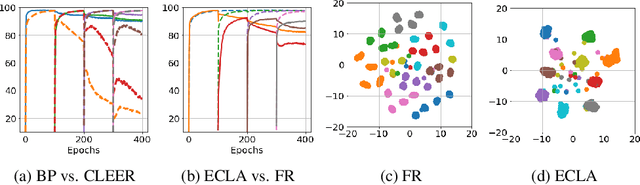
After learning a concept, humans are also able to continually generalize their learned concepts to new domains by observing only a few labeled instances without any interference with the past learned knowledge. In contrast, learning concepts efficiently in a continual learning setting remains an open challenge for current Artificial Intelligence algorithms as persistent model retraining is necessary. Inspired by the Parallel Distributed Processing learning and the Complementary Learning Systems theories, we develop a computational model that is able to expand its previously learned concepts efficiently to new domains using a few labeled samples. We couple the new form of a concept to its past learned forms in an embedding space for effective continual learning. Doing so, a generative distribution is learned such that it is shared across the tasks in the embedding space and models the abstract concepts. This procedure enables the model to generate pseudo-data points to replay the past experience to tackle catastrophic forgetting.
Using World Models for Pseudo-Rehearsal in Continual Learning
Mar 06, 2019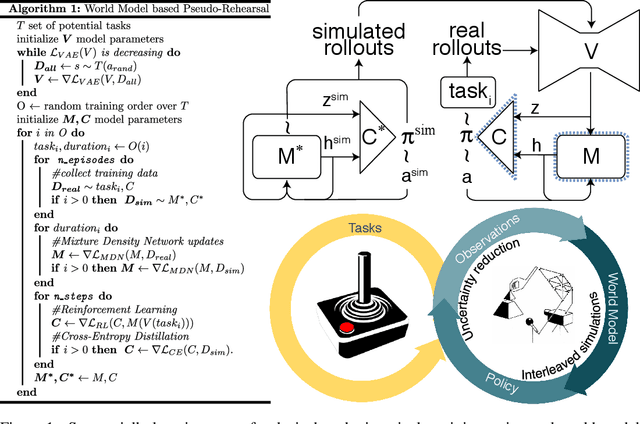
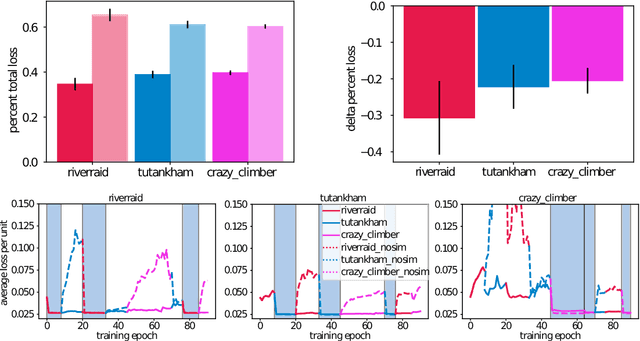
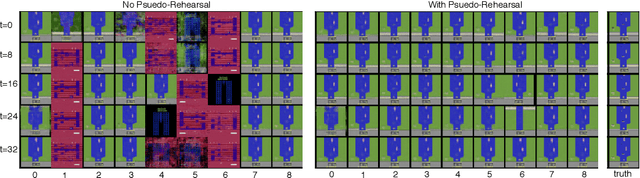
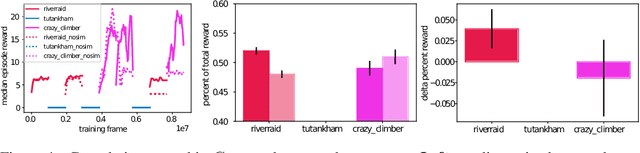
The utility of learning a dynamics/world model of the environment in reinforcement learning has been shown in a many ways. When using neural networks, however, these models suffer catastrophic forgetting when learned in a lifelong or continual fashion. Current solutions to the continual learning problem require experience to be segmented and labeled as discrete tasks, however, in continuous experience it is generally unclear what a sufficient segmentation of tasks would be. Here we propose a method to continually learn these internal world models through the interleaving of internally generated rollouts from past experiences (i.e., pseudo-rehearsal). We show this method can sequentially learn unsupervised temporal prediction, without task labels, in a disparate set of Atari games. Empirically, this interleaving of the internally generated rollouts with the external environment's observations leads to an average 4.5x reduction in temporal prediction loss compared to non-interleaved learning. Similarly, we show that the representations of this internal model remain stable across learned environments. Here, an agent trained using an initial version of the internal model can perform equally well when using a subsequent version that has successfully incorporated experience from multiple new environments.
Attention-Based Structural-Plasticity
Mar 02, 2019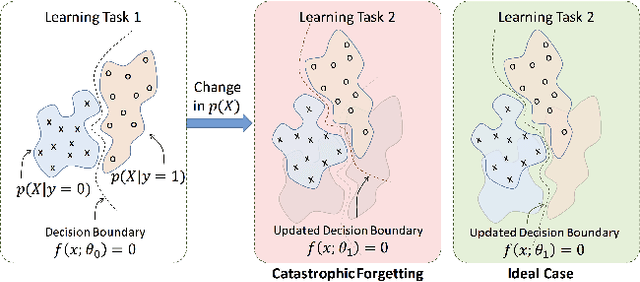

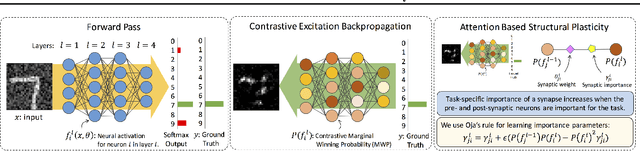

Catastrophic forgetting/interference is a critical problem for lifelong learning machines, which impedes the agents from maintaining their previously learned knowledge while learning new tasks. Neural networks, in particular, suffer plenty from the catastrophic forgetting phenomenon. Recently there has been several efforts towards overcoming catastrophic forgetting in neural networks. Here, we propose a biologically inspired method toward overcoming catastrophic forgetting. Specifically, we define an attention-based selective plasticity of synapses based on the cholinergic neuromodulatory system in the brain. We define synaptic importance parameters in addition to synaptic weights and then use Hebbian learning in parallel with backpropagation algorithm to learn synaptic importances in an online and seamless manner. We test our proposed method on benchmark tasks including the Permuted MNIST and the Split MNIST problems and show competitive performance compared to the state-of-the-art methods.