 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEAR-IR: Clarity-Enhanced Active Reconstruction of Infrared Imagery
Oct 06, 2025



This paper presents a novel approach for enabling robust robotic perception in dark environments using infrared (IR) stream. IR stream is less susceptible to noise than RGB in low-light conditions. However, it is dominated by active emitter patterns that hinder high-level tasks such as object detection, tracking and localisation. To address this, a U-Net-based architecture is proposed that reconstructs clean IR images from emitter-populated input, improving both image quality and downstream robotic performance. This approach outperforms existing enhancement techniques and enables reliable operation of vision-driven robotic systems across illumination conditions from well-lit to extreme low-light scenes.
Exploration in Deep Reinforcement Learning: A Survey
May 02, 2022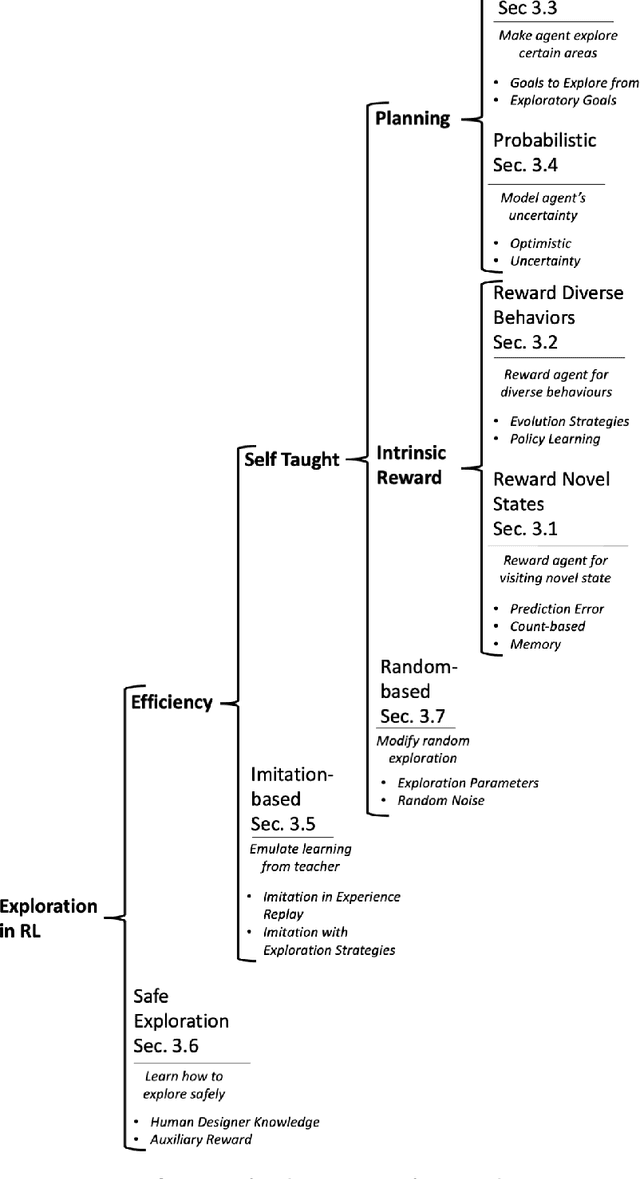
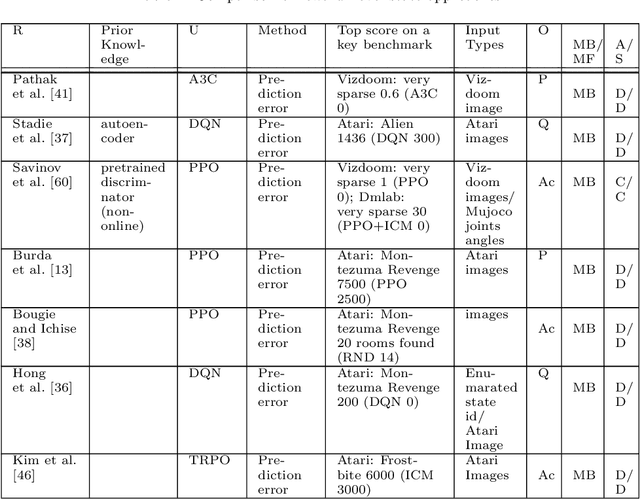
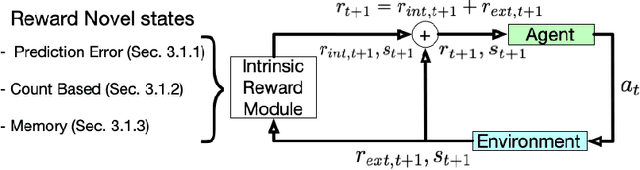
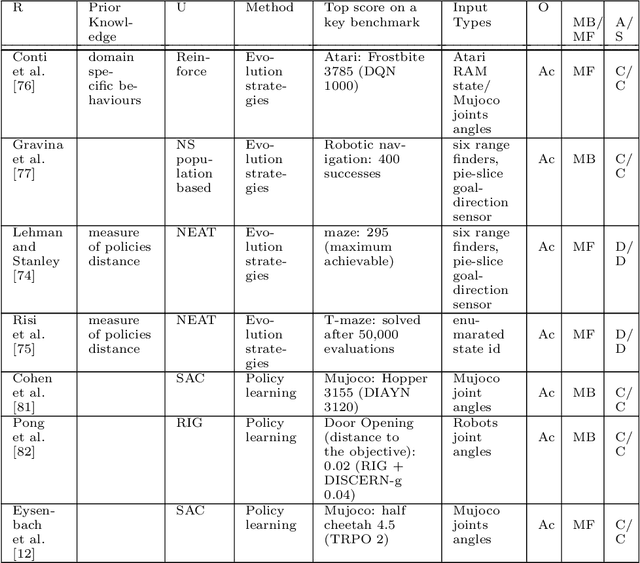
This paper reviews exploration techniques in deep reinforcement learning. Exploration techniques are of primary importance when solving sparse reward problems. In sparse reward problems, the reward is rare, which means that the agent will not find the reward often by acting randomly. In such a scenario, it is challenging for reinforcement learning to learn rewards and actions association. Thus more sophisticated exploration methods need to be devised. This review provides a comprehensive overview of existing exploration approaches, which are categorized based on the key contributions as follows reward novel states, reward diverse behaviours, goal-based methods, probabilistic methods, imitation-based methods, safe exploration and random-based methods. Then, the unsolved challenges are discussed to provide valuable future research directions. Finally, the approaches of different categories are compared in terms of complexity, computational effort and overall performance.
Evolving Inborn Knowledge For Fast Adaptation in Dynamic POMDP Problems
Apr 28, 2020
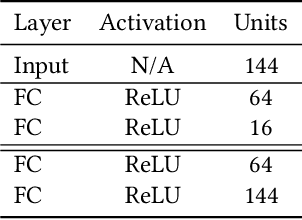
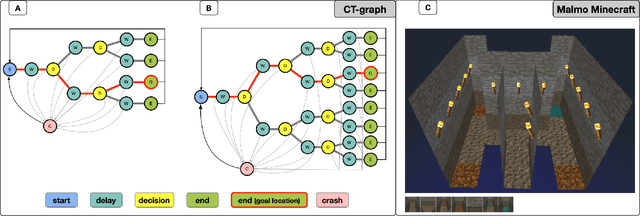
Rapid online adaptation to changing tasks is an important problem in machine learning and, recently, a focus of meta-reinforcement learning. However, reinforcement learning (RL) algorithms struggle in POMDP environments because the state of the system, essential in a RL framework, is not always visible. Additionally, hand-designed meta-RL architectures may not include suitable computational structures for specific learning problems. The evolution of online learning mechanisms, on the contrary, has the ability to incorporate learning strategies into an agent that can (i) evolve memory when required and (ii) optimize adaptation speed to specific online learning problems. In this paper, we exploit the highly adaptive nature of neuromodulated neural networks to evolve a controller that uses the latent space of an autoencoder in a POMDP. The analysis of the evolved networks reveals the ability of the proposed algorithm to acquire inborn knowledge in a variety of aspects such as the detection of cues that reveal implicit rewards, and the ability to evolve location neurons that help with navigation. The integration of inborn knowledge and online plasticity enabled fast adaptation and better performance in comparison to some non-evolutionary meta-reinforcement learning algorithms. The algorithm proved also to succeed in the 3D gaming environment Malmo Minecraft.
Deep Reinforcement Learning with Modulated Hebbian plus Q Network Architecture
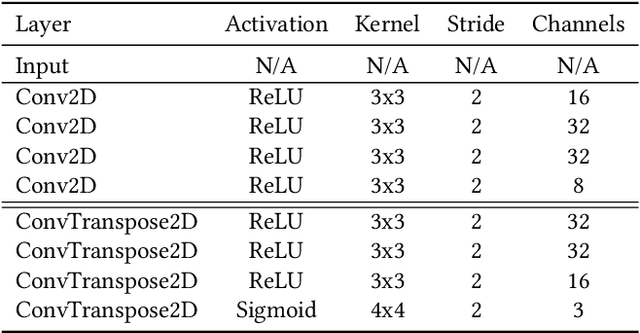
Sep 21, 2019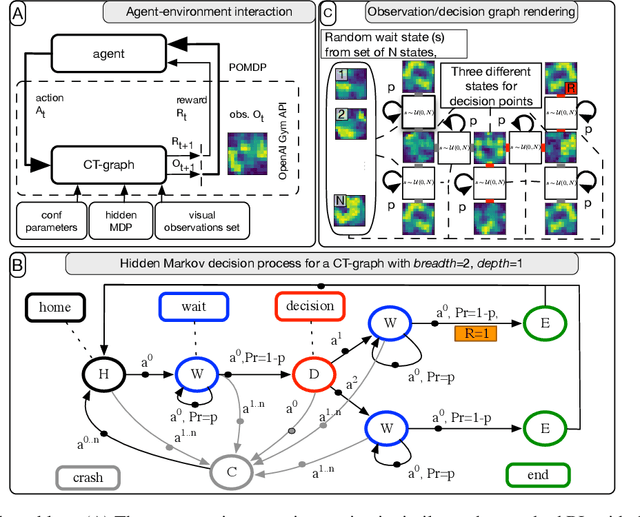
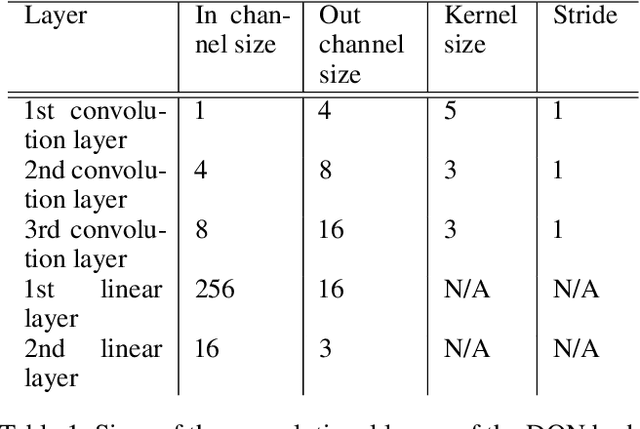
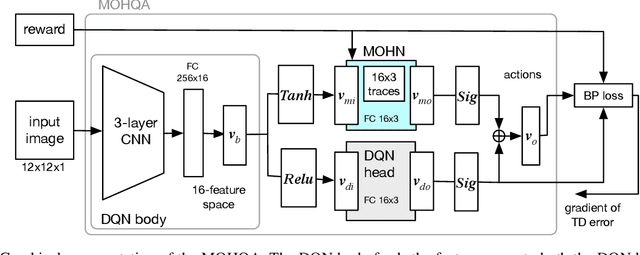
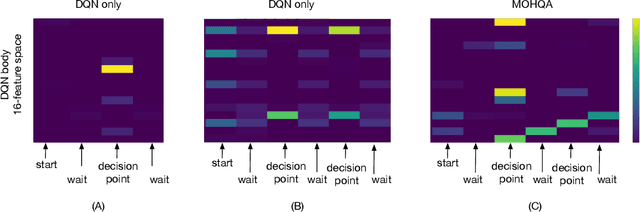
This paper introduces the modulated Hebbian plus Q network architecture (MOHQA) for solving challenging partially observable Markov decision processes (POMDPs) deep reinforcement learning problems with sparse rewards and confounding observations. The proposed architecture combines a deep Q-network (DQN), and a modulated Hebbian network with neural eligibility traces (MOHN). Bio-inspired neural traces are used to bridge temporal delays between actions and rewards. The purpose is to discover distal cause-effect relationships where confounding observations and sparse rewards cause standard RL algorithms to fail. Each of the two modules of the network (DQN and MOHN) is responsible for different aspects of learning. DQN learns low level features and control, while MOHN contributes to the high-level decisions by bridging rewards with past actions. The strength of the approach is to support a DQN standard framework when temporal difference errors are difficult to compute due to non-observable states. The system is tested on a set of generalized decision making problems encoded as decision tree graphs that deliver delayed rewards after key decision points and confounding observations. The simulations show that the proposed approach helps solve problems that are currently challenging for state-of-the-art deep reinforcement learning algorithms.