 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Distillation with Selective Input Gradient Regularization for Efficient Interpretability
May 18, 2022
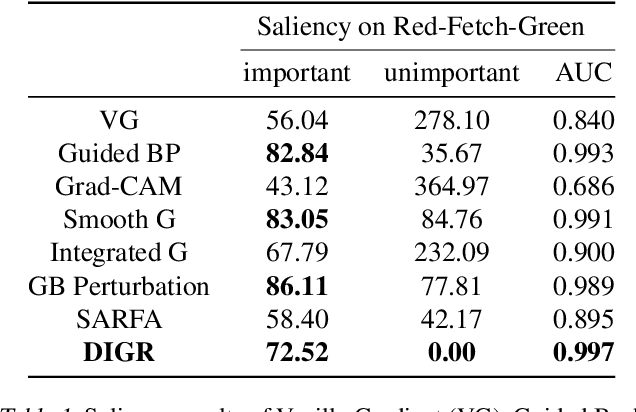
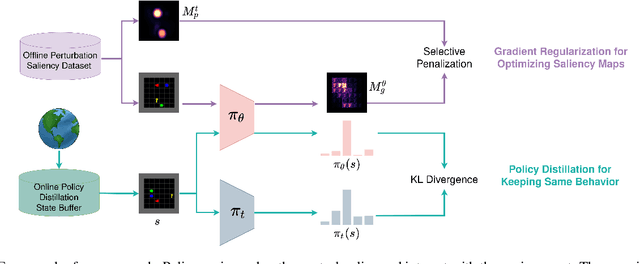
Although deep Reinforcement Learning (RL) has proven successful in a wide range of tasks, one challenge it faces is interpretability when applied to real-world problems. Saliency maps are frequently used to provide interpretability for deep neural networks. However, in the RL domain, existing saliency map approaches are either computationally expensive and thus cannot satisfy the real-time requirement of real-world scenarios or cannot produce interpretable saliency maps for RL policies. In this work, we propose an approach of Distillation with selective Input Gradient Regularization (DIGR) which uses policy distillation and input gradient regularization to produce new policies that achieve both high interpretability and computation efficiency in generating saliency maps. Our approach is also found to improve the robustness of RL policies to multiple adversarial attacks. We conduct experiments on three tasks, MiniGrid (Fetch Object), Atari (Breakout) and CARLA Autonomous Driving, to demonstrate the importance and effectiveness of our approach.
Neuroevolution of a Recurrent Neural Network for Spatial and Working Memory in a Simulated Robotic Environment
Feb 25, 2021
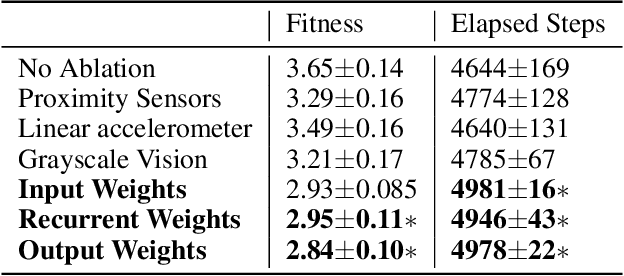

Animals ranging from rats to humans can demonstrate cognitive map capabilities. We evolved weights in a biologically plausible recurrent neural network (RNN) using an evolutionary algorithm to replicate the behavior and neural activity observed in rats during a spatial and working memory task in a triple T-maze. The rat was simulated in the Webots robot simulator and used vision, distance and accelerometer sensors to navigate a virtual maze. After evolving weights from sensory inputs to the RNN, within the RNN, and from the RNN to the robot's motors, the Webots agent successfully navigated the space to reach all four reward arms with minimal repeats before time-out. Our current findings suggest that it is the RNN dynamics that are key to performance, and that performance is not dependent on any one sensory type, which suggests that neurons in the RNN are performing mixed selectivity and conjunctive coding. Moreover, the RNN activity resembles spatial information and trajectory-dependent coding observed in the hippocampus. Collectively, the evolved RNN exhibits navigation skills, spatial memory, and working memory. Our method demonstrates how the dynamic activity in evolved RNNs can capture interesting and complex cognitive behavior and may be used to create RNN controllers for robotic applications.
Domain Adaptation In Reinforcement Learning Via Latent Unified State Representation
Feb 10, 2021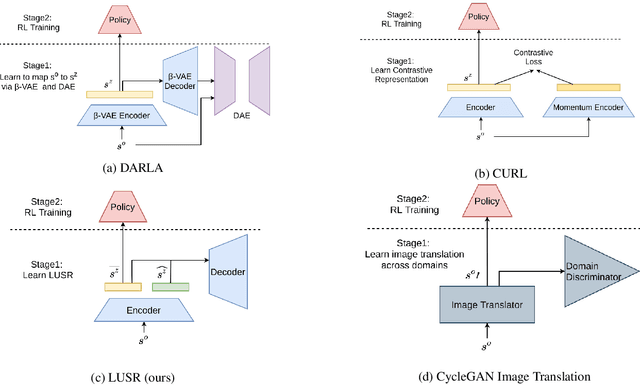

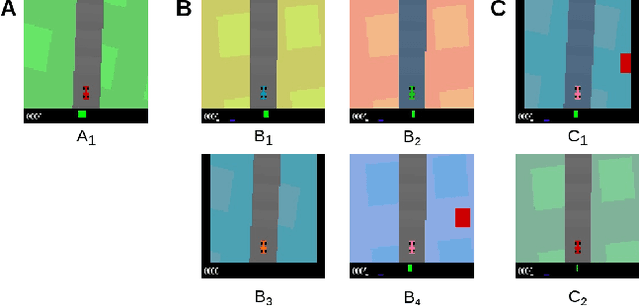
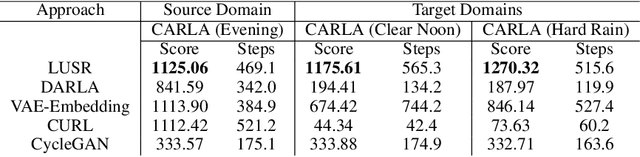
Despite the recent success of deep reinforcement learning (RL), domain adaptation remains an open problem. Although the generalization ability of RL agents is critical for the real-world applicability of Deep RL, zero-shot policy transfer is still a challenging problem since even minor visual changes could make the trained agent completely fail in the new task. To address this issue, we propose a two-stage RL agent that first learns a latent unified state representation (LUSR) which is consistent across multiple domains in the first stage, and then do RL training in one source domain based on LUSR in the second stage. The cross-domain consistency of LUSR allows the policy acquired from the source domain to generalize to other target domains without extra training. We first demonstrate our approach in variants of CarRacing games with customized manipulations, and then verify it in CARLA, an autonomous driving simulator with more complex and realistic visual observations. Our results show that this approach can achieve state-of-the-art domain adaptation performance in related RL tasks and outperforms prior approaches based on latent-representation based RL and image-to-image translation.
Neuromodulated Patience for Robot and Self-Driving Vehicle Navigation
Sep 14, 2019

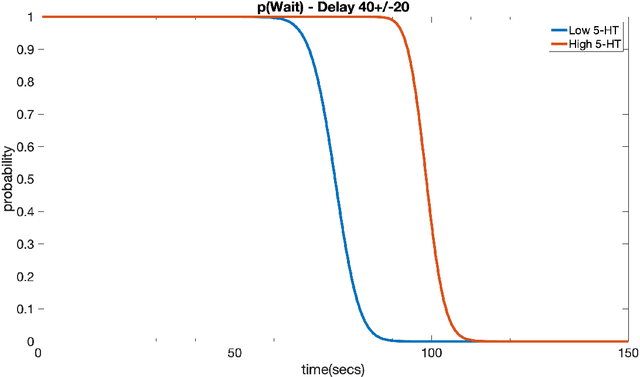
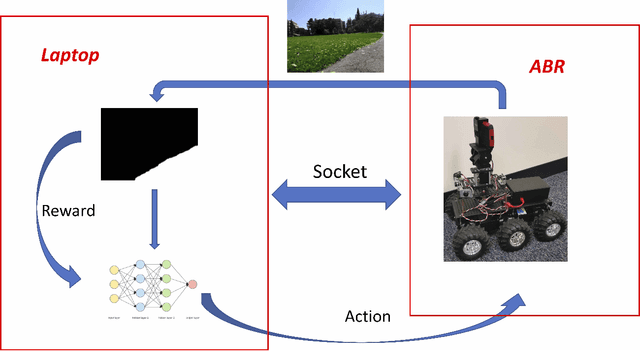
Robots and self-driving vehicles face a number of challenges when navigating through real environments. Successful navigation in dynamic environments requires prioritizing subtasks and monitoring resources. Animals are under similar constraints. It has been shown that the neuromodulator serotonin regulates impulsiveness and patience in animals. In the present paper, we take inspiration from the serotonergic system and apply it to the task of robot navigation. In a set of outdoor experiments, we show how changing the level of patience can affect the amount of time the robot will spend searching for a desired location. To navigate GPS compromised environments, we introduce a deep reinforcement learning paradigm in which the robot learns to follow sidewalks. This may further regulate a tradeoff between a smooth long route and a rough shorter route. Using patience as a parameter may be beneficial for autonomous systems under time pressure.
Attention-Based Structural-Plasticity
Mar 02, 2019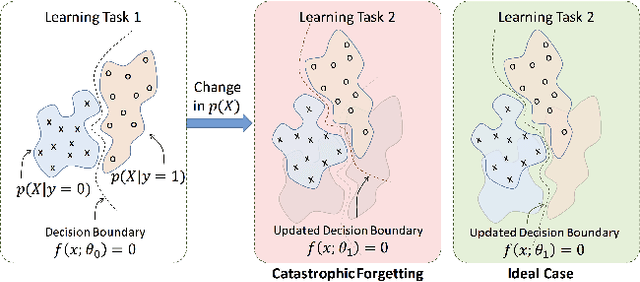

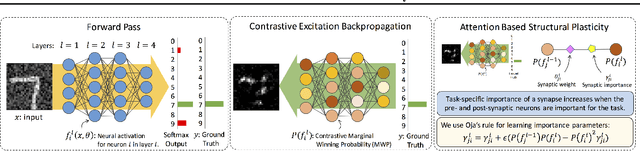

Catastrophic forgetting/interference is a critical problem for lifelong learning machines, which impedes the agents from maintaining their previously learned knowledge while learning new tasks. Neural networks, in particular, suffer plenty from the catastrophic forgetting phenomenon. Recently there has been several efforts towards overcoming catastrophic forgetting in neural networks. Here, we propose a biologically inspired method toward overcoming catastrophic forgetting. Specifically, we define an attention-based selective plasticity of synapses based on the cholinergic neuromodulatory system in the brain. We define synaptic importance parameters in addition to synaptic weights and then use Hebbian learning in parallel with backpropagation algorithm to learn synaptic importances in an online and seamless manner. We test our proposed method on benchmark tasks including the Permuted MNIST and the Split MNIST problems and show competitive performance compared to the state-of-the-art methods.
Neuromodulated Goal-Driven Perception in Uncertain Domains
Feb 16, 2019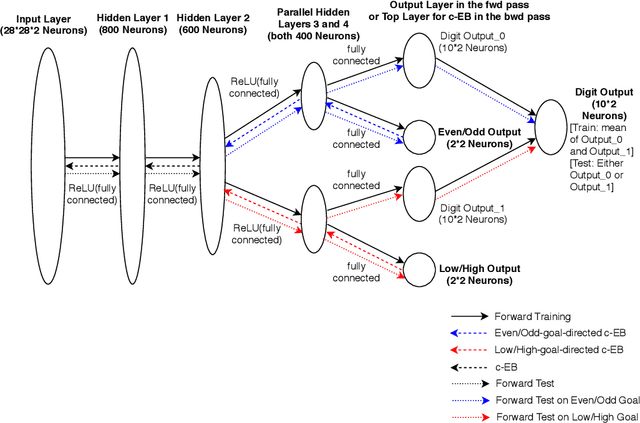
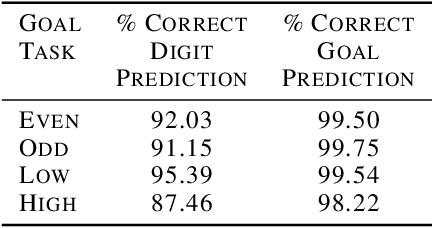
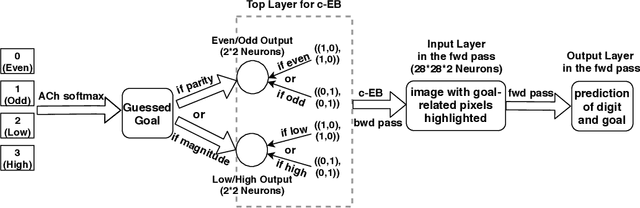
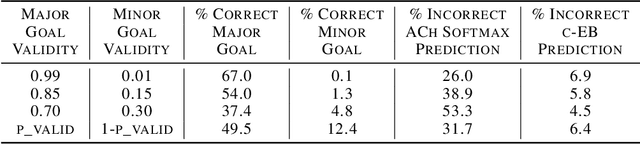
In uncertain domains, the goals are often unknown and need to be predicted by the organism or system. In this paper, contrastive excitation backprop (c-EB) was used in a goal-driven perception task with pairs of noisy MNIST digits, where the system had to increase attention to one of the two digits corresponding to a goal (i.e., even, odd, low value, or high value) and decrease attention to the distractor digit or noisy background pixels. Because the valid goal was unknown, an online learning model based on the cholinergic and noradrenergic neuromodulatory systems was used to predict a noisy goal (expected uncertainty) and re-adapt when the goal changed (unexpected uncertainty). This neurobiologically plausible model demonstrates how neuromodulatory systems can predict goals in uncertain domains and how attentional mechanisms can enhance the perception of that goal.