 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe FACTS Grounding Leaderboard: Benchmarking LLMs' Ability to Ground Responses to Long-Form Input
Jan 06, 2025



We introduce FACTS Grounding, an online leaderboard and associated benchmark that evaluates language models' ability to generate text that is factually accurate with respect to given context in the user prompt. In our benchmark, each prompt includes a user request and a full document, with a maximum length of 32k tokens, requiring long-form responses. The long-form responses are required to be fully grounded in the provided context document while fulfilling the user request. Models are evaluated using automated judge models in two phases: (1) responses are disqualified if they do not fulfill the user request; (2) they are judged as accurate if the response is fully grounded in the provided document. The automated judge models were comprehensively evaluated against a held-out test-set to pick the best prompt template, and the final factuality score is an aggregate of multiple judge models to mitigate evaluation bias. The FACTS Grounding leaderboard will be actively maintained over time, and contains both public and private splits to allow for external participation while guarding the integrity of the leaderboard. It can be found at https://www.kaggle.com/facts-leaderboard.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Policy Distillation with Selective Input Gradient Regularization for Efficient Interpretability
May 18, 2022
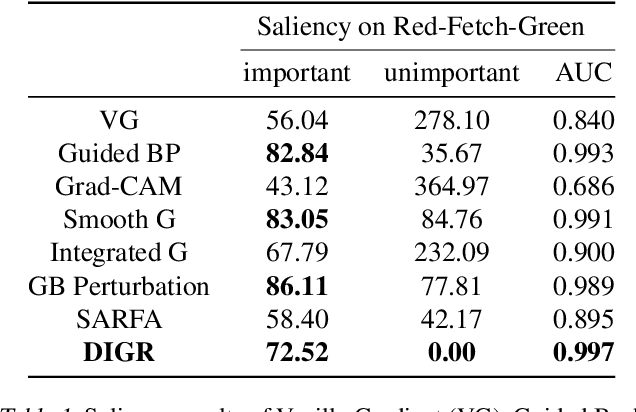
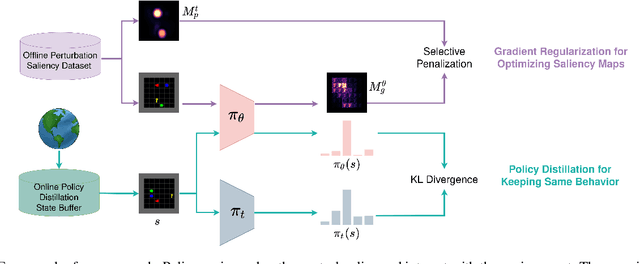
Although deep Reinforcement Learning (RL) has proven successful in a wide range of tasks, one challenge it faces is interpretability when applied to real-world problems. Saliency maps are frequently used to provide interpretability for deep neural networks. However, in the RL domain, existing saliency map approaches are either computationally expensive and thus cannot satisfy the real-time requirement of real-world scenarios or cannot produce interpretable saliency maps for RL policies. In this work, we propose an approach of Distillation with selective Input Gradient Regularization (DIGR) which uses policy distillation and input gradient regularization to produce new policies that achieve both high interpretability and computation efficiency in generating saliency maps. Our approach is also found to improve the robustness of RL policies to multiple adversarial attacks. We conduct experiments on three tasks, MiniGrid (Fetch Object), Atari (Breakout) and CARLA Autonomous Driving, to demonstrate the importance and effectiveness of our approach.
Domain Adaptation In Reinforcement Learning Via Latent Unified State Representation
Feb 10, 2021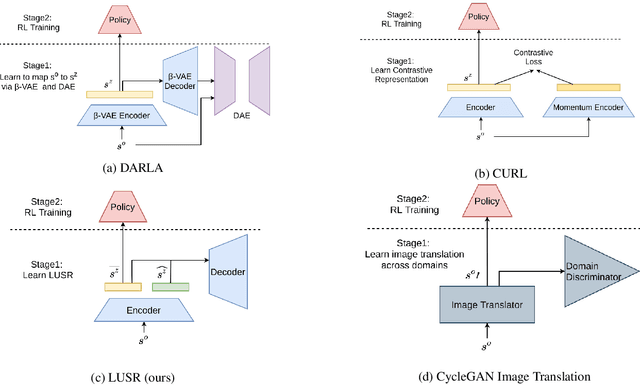

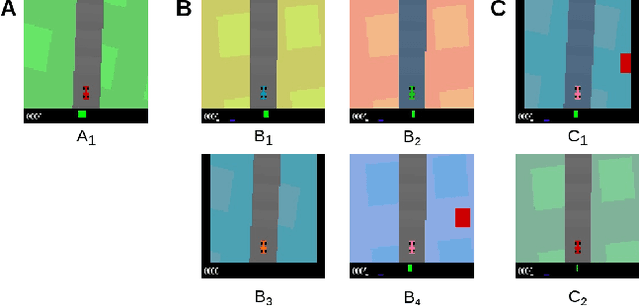
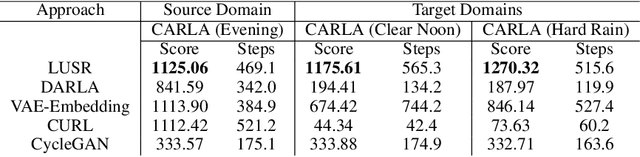
Despite the recent success of deep reinforcement learning (RL), domain adaptation remains an open problem. Although the generalization ability of RL agents is critical for the real-world applicability of Deep RL, zero-shot policy transfer is still a challenging problem since even minor visual changes could make the trained agent completely fail in the new task. To address this issue, we propose a two-stage RL agent that first learns a latent unified state representation (LUSR) which is consistent across multiple domains in the first stage, and then do RL training in one source domain based on LUSR in the second stage. The cross-domain consistency of LUSR allows the policy acquired from the source domain to generalize to other target domains without extra training. We first demonstrate our approach in variants of CarRacing games with customized manipulations, and then verify it in CARLA, an autonomous driving simulator with more complex and realistic visual observations. Our results show that this approach can achieve state-of-the-art domain adaptation performance in related RL tasks and outperforms prior approaches based on latent-representation based RL and image-to-image translation.
Neuromodulated Patience for Robot and Self-Driving Vehicle Navigation
Sep 14, 2019

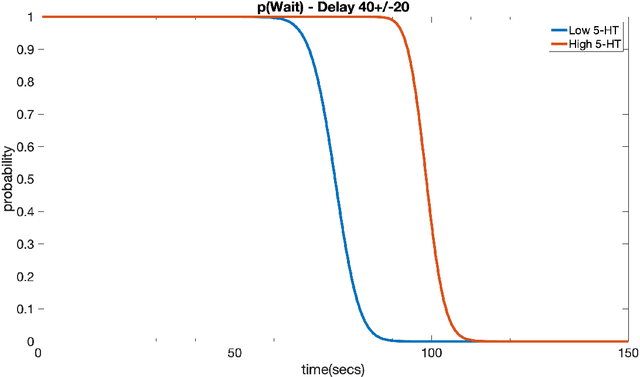
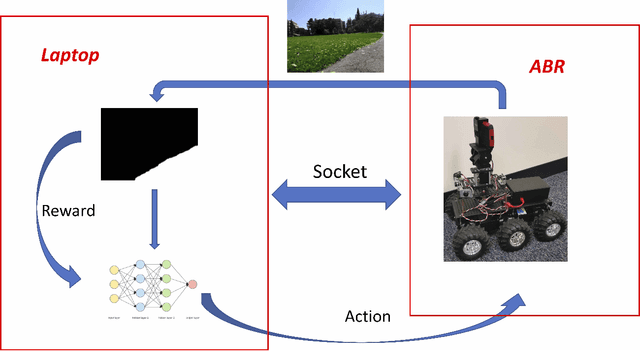
Robots and self-driving vehicles face a number of challenges when navigating through real environments. Successful navigation in dynamic environments requires prioritizing subtasks and monitoring resources. Animals are under similar constraints. It has been shown that the neuromodulator serotonin regulates impulsiveness and patience in animals. In the present paper, we take inspiration from the serotonergic system and apply it to the task of robot navigation. In a set of outdoor experiments, we show how changing the level of patience can affect the amount of time the robot will spend searching for a desired location. To navigate GPS compromised environments, we introduce a deep reinforcement learning paradigm in which the robot learns to follow sidewalks. This may further regulate a tradeoff between a smooth long route and a rough shorter route. Using patience as a parameter may be beneficial for autonomous systems under time pressure.