 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetacognition for Unknown Situations and Environments (MUSE)
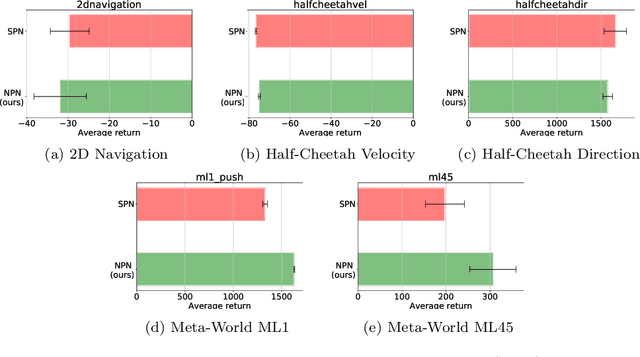
Nov 20, 2024Metacognition--the awareness and regulation of one's cognitive processes--is central to human adaptability in unknown situations. In contrast, current autonomous agents often struggle in novel environments due to their limited capacity for adaptation. We hypothesize that metacognition is a critical missing ingredient in adaptive autonomous systems, equipping them with the cognitive flexibility needed to tackle unfamiliar challenges. Given the broad scope of metacognitive abilities, we focus on two key aspects: competence awareness and strategy selection for novel tasks. To this end, we propose the Metacognition for Unknown Situations and Environments (MUSE) framework, which integrates metacognitive processes--specifically self-awareness and self-regulation--into autonomous agents. We present two initial implementations of MUSE: one based on world modeling and another leveraging large language models (LLMs), both instantiating the metacognitive cycle. Our system continuously learns to assess its competence on a given task and uses this self-awareness to guide iterative cycles of strategy selection. MUSE agents show significant improvements in self-awareness and self-regulation, enabling them to solve novel, out-of-distribution tasks more effectively compared to Dreamer-v3-based reinforcement learning and purely prompt-based LLM agent approaches. This work highlights the promise of approaches inspired by cognitive and neural systems in enabling autonomous systems to adapt to new environments, overcoming the limitations of current methods that rely heavily on extensive training data.
A Domain-Agnostic Approach for Characterization of Lifelong Learning Systems
Jan 18, 2023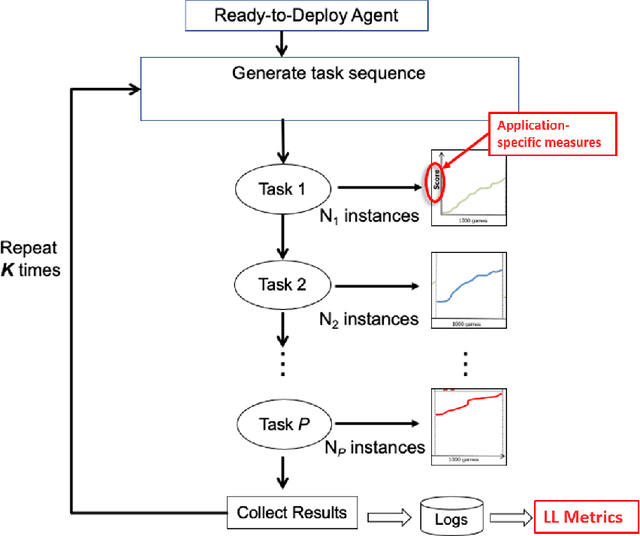


Despite the advancement of machine learning techniques in recent years, state-of-the-art systems lack robustness to "real world" events, where the input distributions and tasks encountered by the deployed systems will not be limited to the original training context, and systems will instead need to adapt to novel distributions and tasks while deployed. This critical gap may be addressed through the development of "Lifelong Learning" systems that are capable of 1) Continuous Learning, 2) Transfer and Adaptation, and 3) Scalability. Unfortunately, efforts to improve these capabilities are typically treated as distinct areas of research that are assessed independently, without regard to the impact of each separate capability on other aspects of the system. We instead propose a holistic approach, using a suite of metrics and an evaluation framework to assess Lifelong Learning in a principled way that is agnostic to specific domains or system techniques. Through five case studies, we show that this suite of metrics can inform the development of varied and complex Lifelong Learning systems. We highlight how the proposed suite of metrics quantifies performance trade-offs present during Lifelong Learning system development - both the widely discussed Stability-Plasticity dilemma and the newly proposed relationship between Sample Efficient and Robust Learning. Further, we make recommendations for the formulation and use of metrics to guide the continuing development of Lifelong Learning systems and assess their progress in the future.
Lifelong Reinforcement Learning with Modulating Masks
Dec 21, 2022Lifelong learning aims to create AI systems that continuously and incrementally learn during a lifetime, similar to biological learning. Attempts so far have met problems, including catastrophic forgetting, interference among tasks, and the inability to exploit previous knowledge. While considerable research has focused on learning multiple input distributions, typically in classification, lifelong reinforcement learning (LRL) must also deal with variations in the state and transition distributions, and in the reward functions. Modulating masks, recently developed for classification, are particularly suitable to deal with such a large spectrum of task variations. In this paper, we adapted modulating masks to work with deep LRL, specifically PPO and IMPALA agents. The comparison with LRL baselines in both discrete and continuous RL tasks shows competitive performance. We further investigated the use of a linear combination of previously learned masks to exploit previous knowledge when learning new tasks: not only is learning faster, the algorithm solves tasks that we could not otherwise solve from scratch due to extremely sparse rewards. The results suggest that RL with modulating masks is a promising approach to lifelong learning, to the composition of knowledge to learn increasingly complex tasks, and to knowledge reuse for efficient and faster learning.
Concept-modulated model-based offline reinforcement learning for rapid generalization
Sep 07, 2022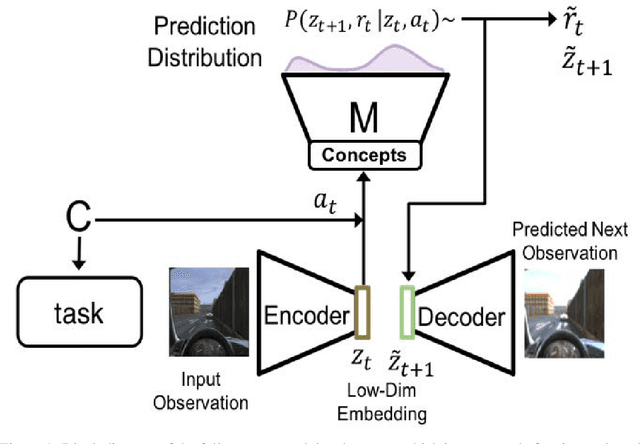
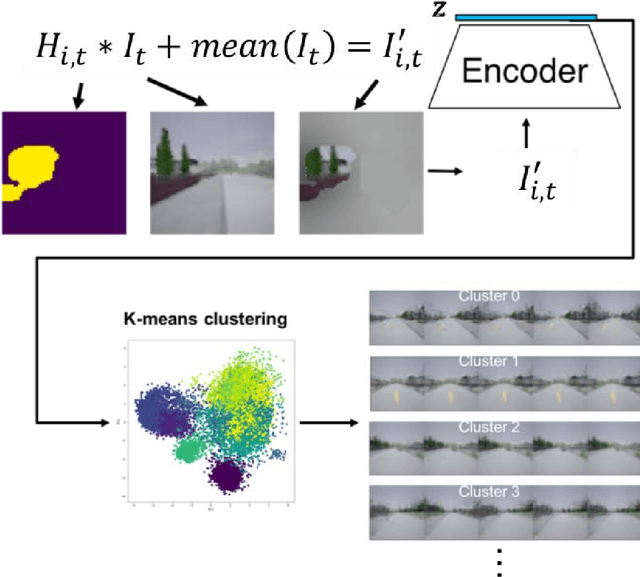
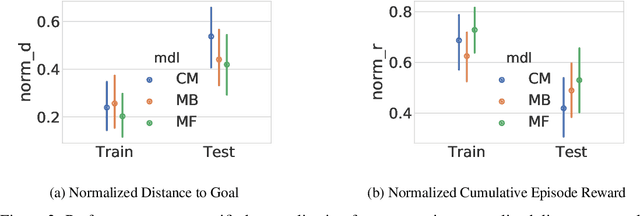
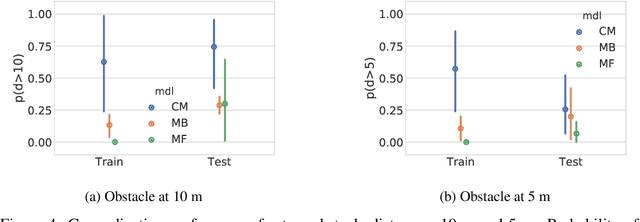
The robustness of any machine learning solution is fundamentally bound by the data it was trained on. One way to generalize beyond the original training is through human-informed augmentation of the original dataset; however, it is impossible to specify all possible failure cases that can occur during deployment. To address this limitation we combine model-based reinforcement learning and model-interpretability methods to propose a solution that self-generates simulated scenarios constrained by environmental concepts and dynamics learned in an unsupervised manner. In particular, an internal model of the agent's environment is conditioned on low-dimensional concept representations of the input space that are sensitive to the agent's actions. We demonstrate this method within a standard realistic driving simulator in a simple point-to-point navigation task, where we show dramatic improvements in one-shot generalization to different instances of specified failure cases as well as zero-shot generalization to similar variations compared to model-based and model-free approaches.
Context Meta-Reinforcement Learning via Neuromodulation
Oct 30, 2021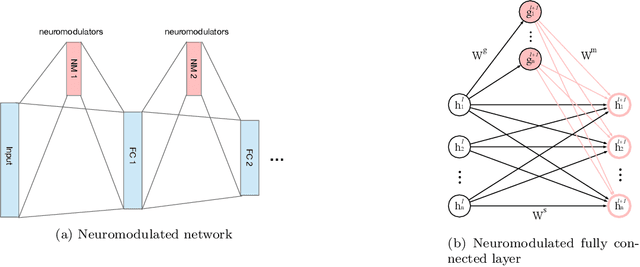
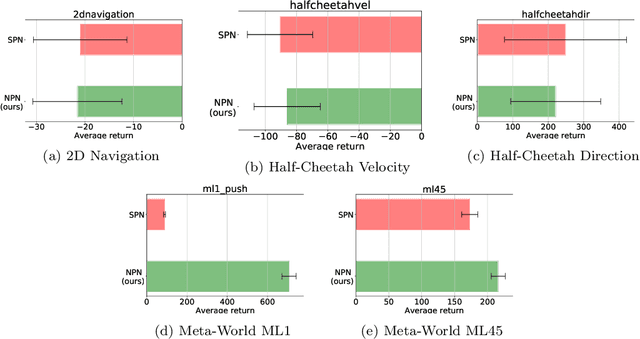

Meta-reinforcement learning (meta-RL) algorithms enable agents to adapt quickly to tasks from few samples in dynamic environments. Such a feat is achieved through dynamic representations in an agent's policy network (obtained via reasoning about task context, model parameter updates, or both). However, obtaining rich dynamic representations for fast adaptation beyond simple benchmark problems is challenging due to the burden placed on the policy network to accommodate different policies. This paper addresses the challenge by introducing neuromodulation as a modular component to augment a standard policy network that regulates neuronal activities in order to produce efficient dynamic representations for task adaptation. The proposed extension to the policy network is evaluated across multiple discrete and continuous control environments of increasing complexity. To prove the generality and benefits of the extension in meta-RL, the neuromodulated network was applied to two state-of-the-art meta-RL algorithms (CAVIA and PEARL). The result demonstrates that meta-RL augmented with neuromodulation produces significantly better result and richer dynamic representations in comparison to the baselines.
Lifelong Learning with Sketched Structural Regularization
Apr 17, 2021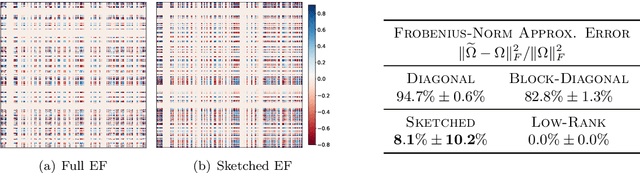
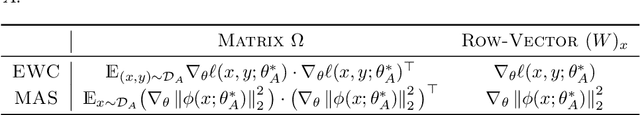
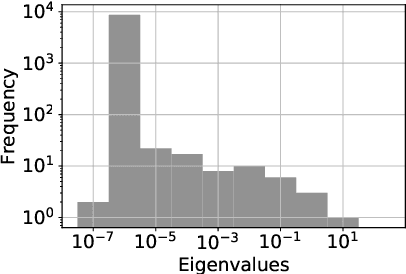
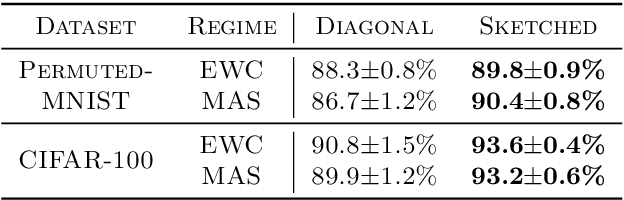
Preventing catastrophic forgetting while continually learning new tasks is an essential problem in lifelong learning. Structural regularization (SR) refers to a family of algorithms that mitigate catastrophic forgetting by penalizing the network for changing its "critical parameters" from previous tasks while learning a new one. The penalty is often induced via a quadratic regularizer defined by an \emph{importance matrix}, e.g., the (empirical) Fisher information matrix in the Elastic Weight Consolidation framework. In practice and due to computational constraints, most SR methods crudely approximate the importance matrix by its diagonal. In this paper, we propose \emph{Sketched Structural Regularization} (Sketched SR) as an alternative approach to compress the importance matrices used for regularizing in SR methods. Specifically, we apply \emph{linear sketching methods} to better approximate the importance matrices in SR algorithms. We show that sketched SR: (i) is computationally efficient and straightforward to implement, (ii) provides an approximation error that is justified in theory, and (iii) is method oblivious by construction and can be adapted to any method that belongs to the structural regularization class. We show that our proposed approach consistently improves various SR algorithms' performance on both synthetic experiments and benchmark continual learning tasks, including permuted-MNIST and CIFAR-100.
Complementary Learning for Overcoming Catastrophic Forgetting Using Experience Replay
Mar 11, 2019
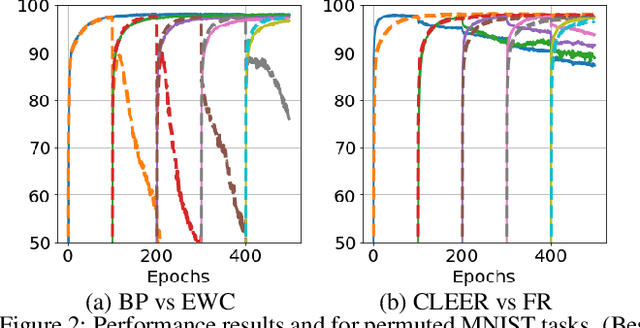
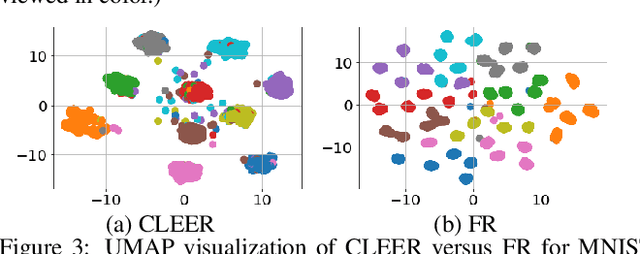
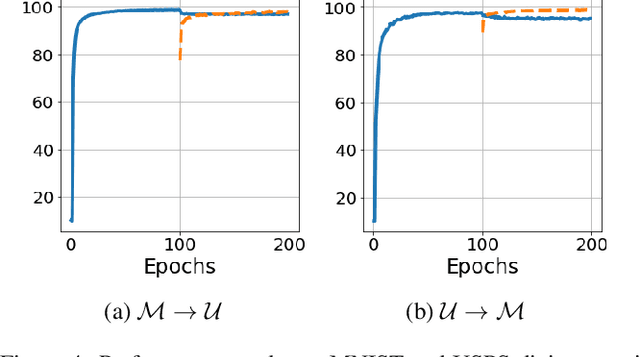
Despite huge success, deep networks are unable to learn effectively in sequential multitask learning settings as they forget the past learned tasks after learning new tasks. Inspired from complementary learning systems theory, we address this challenge by learning a generative model that couples the current task to the past learned tasks through a discriminative embedding space. We learn an abstract level generative distribution in the embedding that allows the generation of data points to represent the experience. We sample from this distribution and utilize experience replay to avoid forgetting and simultaneously accumulate new knowledge to the abstract distribution in order to couple the current task with past experience. We demonstrate theoretically and empirically that our framework learns a distribution in the embedding that is shared across all task and as a result tackles catastrophic forgetting.
Neuromodulated Goal-Driven Perception in Uncertain Domains
Feb 16, 2019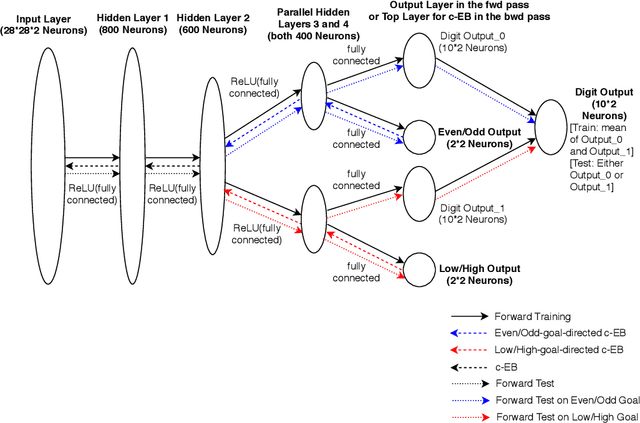
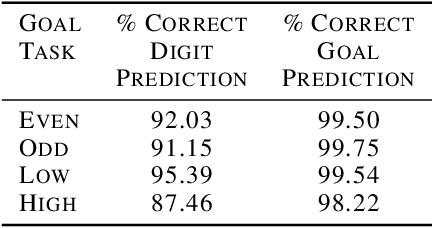
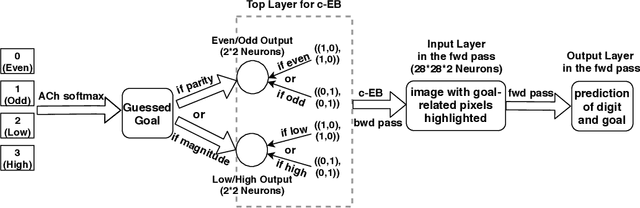
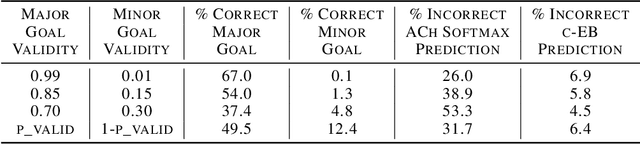
In uncertain domains, the goals are often unknown and need to be predicted by the organism or system. In this paper, contrastive excitation backprop (c-EB) was used in a goal-driven perception task with pairs of noisy MNIST digits, where the system had to increase attention to one of the two digits corresponding to a goal (i.e., even, odd, low value, or high value) and decrease attention to the distractor digit or noisy background pixels. Because the valid goal was unknown, an online learning model based on the cholinergic and noradrenergic neuromodulatory systems was used to predict a noisy goal (expected uncertainty) and re-adapt when the goal changed (unexpected uncertainty). This neurobiologically plausible model demonstrates how neuromodulatory systems can predict goals in uncertain domains and how attentional mechanisms can enhance the perception of that goal.