 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept-modulated model-based offline reinforcement learning for rapid generalization
Sep 07, 2022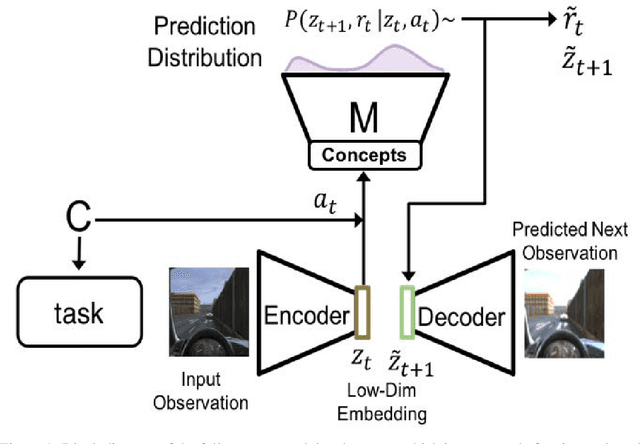
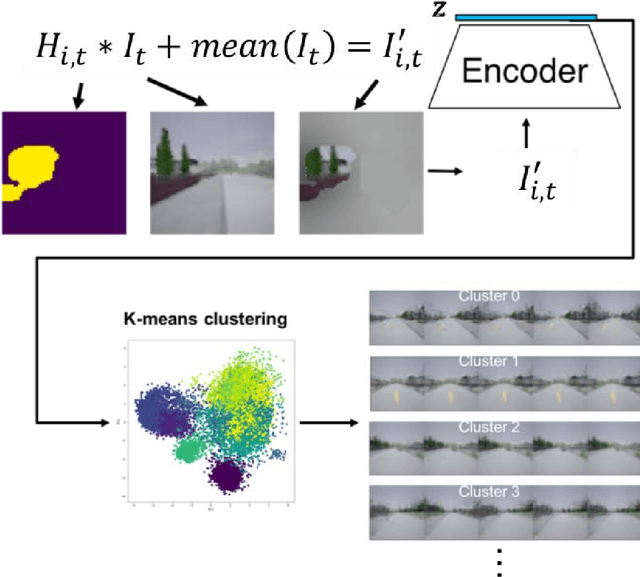
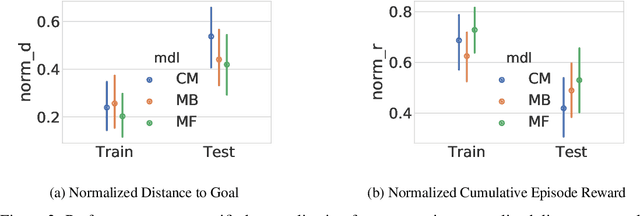
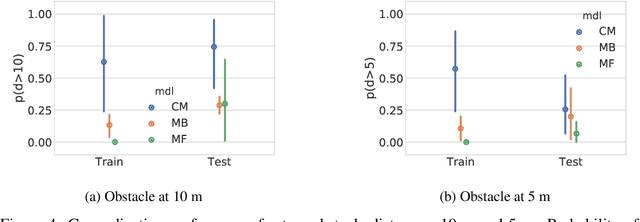
The robustness of any machine learning solution is fundamentally bound by the data it was trained on. One way to generalize beyond the original training is through human-informed augmentation of the original dataset; however, it is impossible to specify all possible failure cases that can occur during deployment. To address this limitation we combine model-based reinforcement learning and model-interpretability methods to propose a solution that self-generates simulated scenarios constrained by environmental concepts and dynamics learned in an unsupervised manner. In particular, an internal model of the agent's environment is conditioned on low-dimensional concept representations of the input space that are sensitive to the agent's actions. We demonstrate this method within a standard realistic driving simulator in a simple point-to-point navigation task, where we show dramatic improvements in one-shot generalization to different instances of specified failure cases as well as zero-shot generalization to similar variations compared to model-based and model-free approaches.
Context Meta-Reinforcement Learning via Neuromodulation
Oct 30, 2021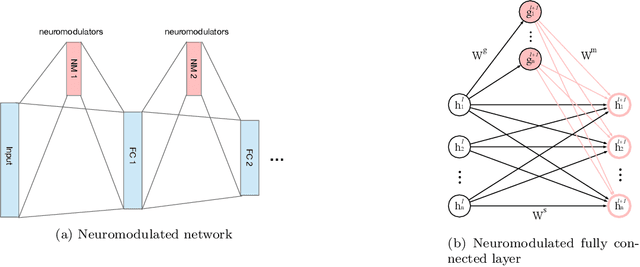
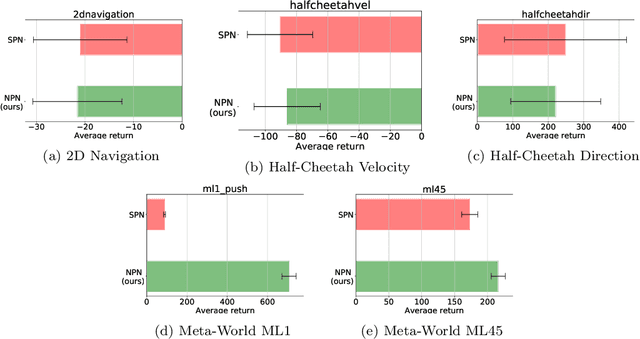
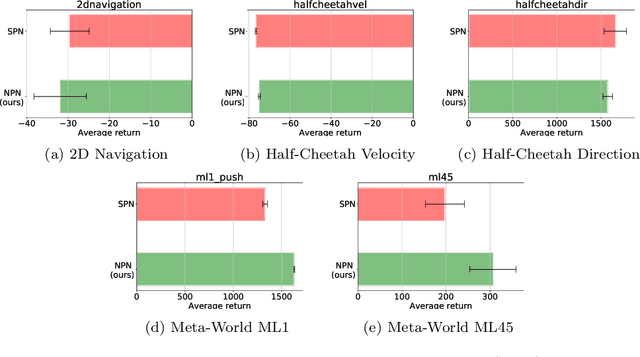

Meta-reinforcement learning (meta-RL) algorithms enable agents to adapt quickly to tasks from few samples in dynamic environments. Such a feat is achieved through dynamic representations in an agent's policy network (obtained via reasoning about task context, model parameter updates, or both). However, obtaining rich dynamic representations for fast adaptation beyond simple benchmark problems is challenging due to the burden placed on the policy network to accommodate different policies. This paper addresses the challenge by introducing neuromodulation as a modular component to augment a standard policy network that regulates neuronal activities in order to produce efficient dynamic representations for task adaptation. The proposed extension to the policy network is evaluated across multiple discrete and continuous control environments of increasing complexity. To prove the generality and benefits of the extension in meta-RL, the neuromodulated network was applied to two state-of-the-art meta-RL algorithms (CAVIA and PEARL). The result demonstrates that meta-RL augmented with neuromodulation produces significantly better result and richer dynamic representations in comparison to the baselines.