 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Deep Animation Video Interpolation
Jun 25, 2022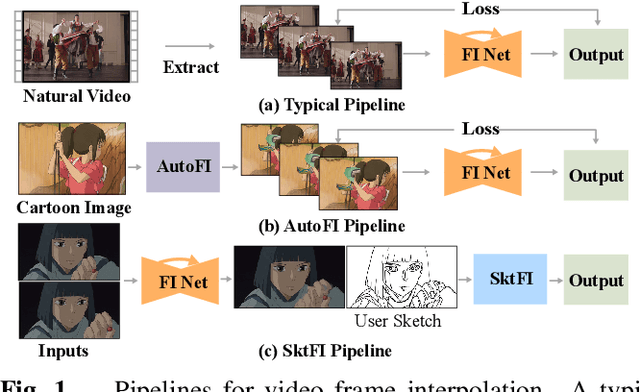

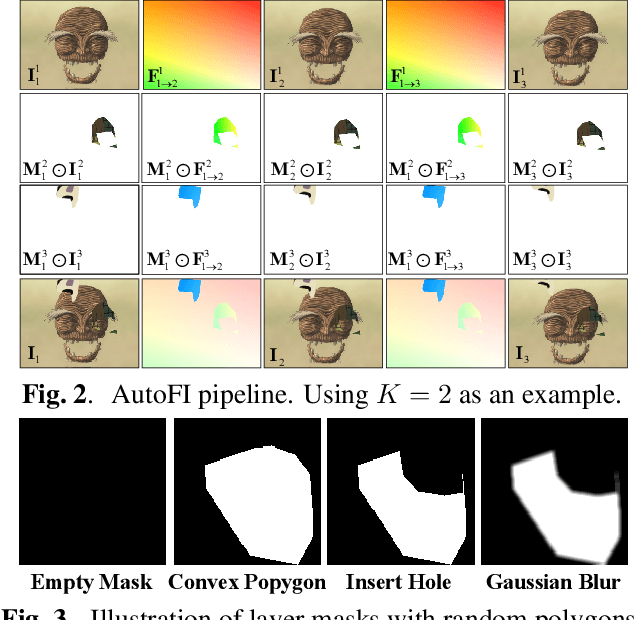
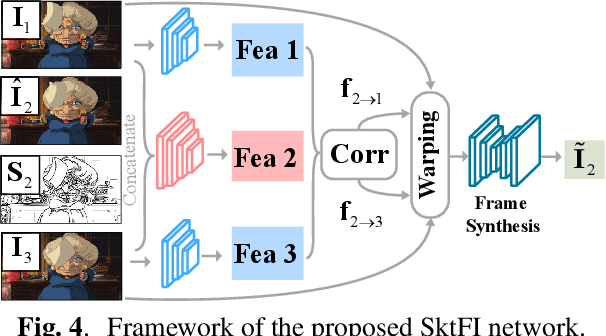
Existing learning-based frame interpolation algorithms extract consecutive frames from high-speed natural videos to train the model. Compared to natural videos, cartoon videos are usually in a low frame rate. Besides, the motion between consecutive cartoon frames is typically nonlinear, which breaks the linear motion assumption of interpolation algorithms. Thus, it is unsuitable for generating a training set directly from cartoon videos. For better adapting frame interpolation algorithms from nature video to animation video, we present AutoFI, a simple and effective method to automatically render training data for deep animation video interpolation. AutoFI takes a layered architecture to render synthetic data, which ensures the assumption of linear motion. Experimental results show that AutoFI performs favorably in training both DAIN and ANIN. However, most frame interpolation algorithms will still fail in error-prone areas, such as fast motion or large occlusion. Besides AutoFI, we also propose a plug-and-play sketch-based post-processing module, named SktFI, to refine the final results using user-provided sketches manually. With AutoFI and SktFI, the interpolated animation frames show high perceptual quality.
Prediction-assistant Frame Super-Resolution for Video Streaming
Mar 17, 2021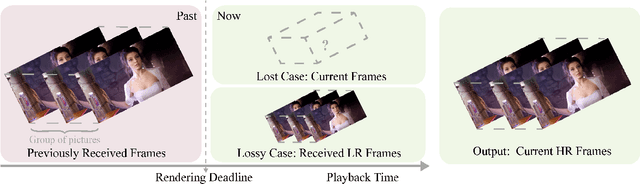
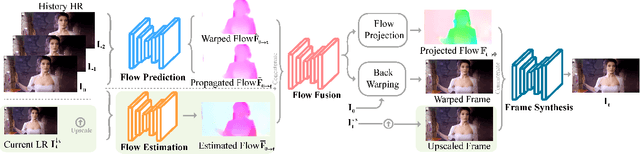
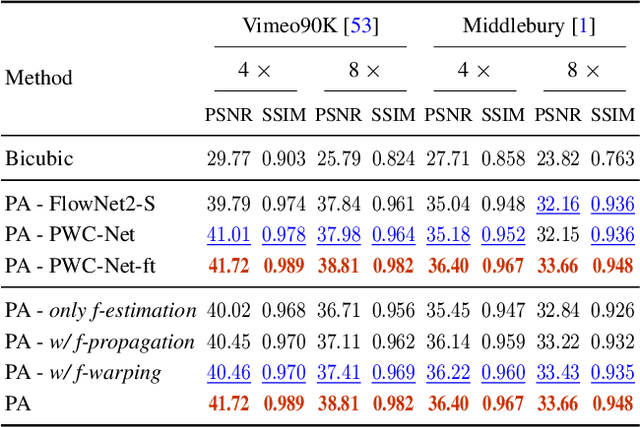

Video frame transmission delay is critical in real-time applications such as online video gaming, live show, etc. The receiving deadline of a new frame must catch up with the frame rendering time. Otherwise, the system will buffer a while, and the user will encounter a frozen screen, resulting in unsatisfactory user experiences. An effective approach is to transmit frames in lower-quality under poor bandwidth conditions, such as using scalable video coding. In this paper, we propose to enhance video quality using lossy frames in two situations. First, when current frames are too late to receive before rendering deadline (i.e., lost), we propose to use previously received high-resolution images to predict the future frames. Second, when the quality of the currently received frames is low~(i.e., lossy), we propose to use previously received high-resolution frames to enhance the low-quality current ones. For the first case, we propose a small yet effective video frame prediction network. For the second case, we improve the video prediction network to a video enhancement network to associate current frames as well as previous frames to restore high-quality images. Extensive experimental results demonstrate that our method performs favorably against state-of-the-art algorithms in the lossy video streaming environment.
Uniform Interpolation Constrained Geodesic Learning on Data Manifold
Feb 28, 2020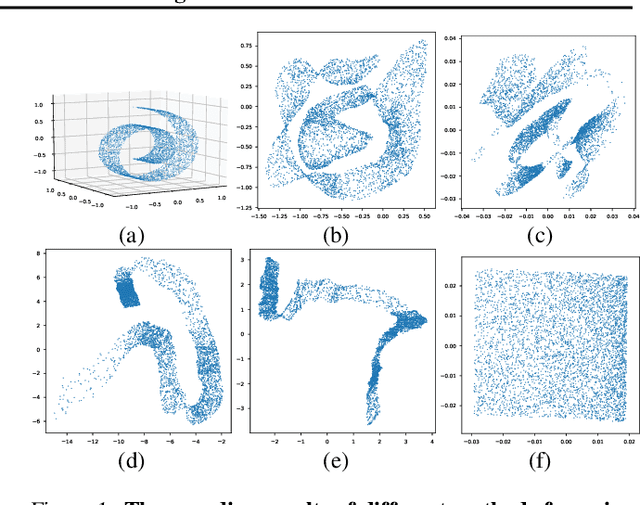
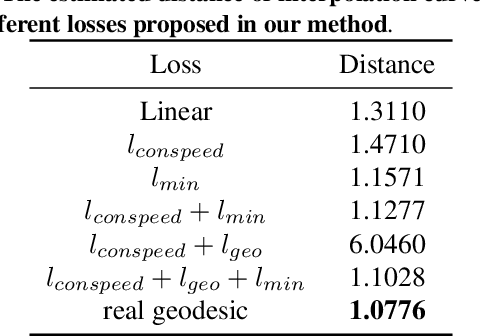
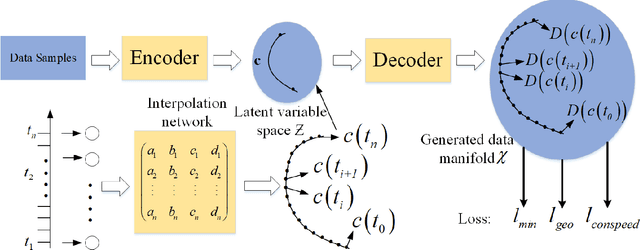
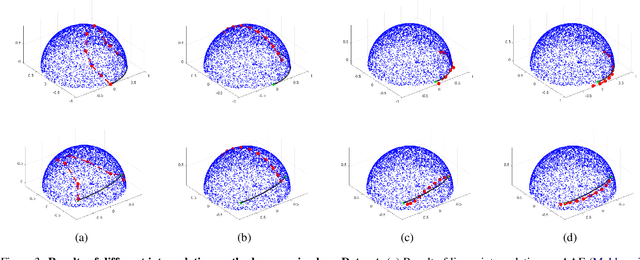
In this paper, we propose a method to learn a minimizing geodesic within a data manifold. Along the learned geodesic, our method can generate high-quality interpolations between two given data samples. Specifically, we use an autoencoder network to map data samples into latent space and perform interpolation via an interpolation network. We add prior geometric information to regularize our autoencoder for the convexity of representations so that for any given interpolation approach, the generated interpolations remain within the distribution of the data manifold. Before the learning of a geodesic, a proper Riemannianmetric should be defined. Therefore, we induce a Riemannian metric by the canonical metric in the Euclidean space which the data manifold is isometrically immersed in. Based on this defined Riemannian metric, we introduce a constant speed loss and a minimizing geodesic loss to regularize the interpolation network to generate uniform interpolation along the learned geodesic on the manifold. We provide a theoretical analysis of our model and use image translation as an example to demonstrate the effectiveness of our method.
Blurry Video Frame Interpolation
Feb 27, 2020
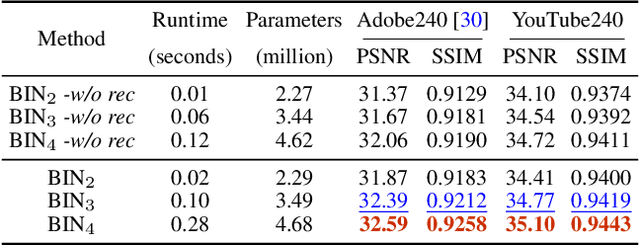
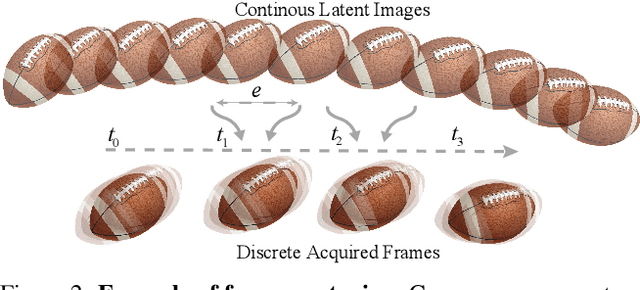
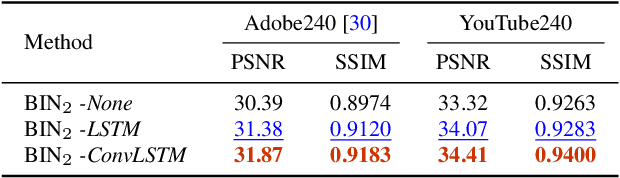
Existing works reduce motion blur and up-convert frame rate through two separate ways, including frame deblurring and frame interpolation. However, few studies have approached the joint video enhancement problem, namely synthesizing high-frame-rate clear results from low-frame-rate blurry inputs. In this paper, we propose a blurry video frame interpolation method to reduce motion blur and up-convert frame rate simultaneously. Specifically, we develop a pyramid module to cyclically synthesize clear intermediate frames. The pyramid module features adjustable spatial receptive field and temporal scope, thus contributing to controllable computational complexity and restoration ability. Besides, we propose an inter-pyramid recurrent module to connect sequential models to exploit the temporal relationship. The pyramid module integrates a recurrent module, thus can iteratively synthesize temporally smooth results without significantly increasing the model size. Extensive experimental results demonstrate that our method performs favorably against state-of-the-art methods.
A Dual Camera System for High Spatiotemporal Resolution Video Acquisition
Sep 28, 2019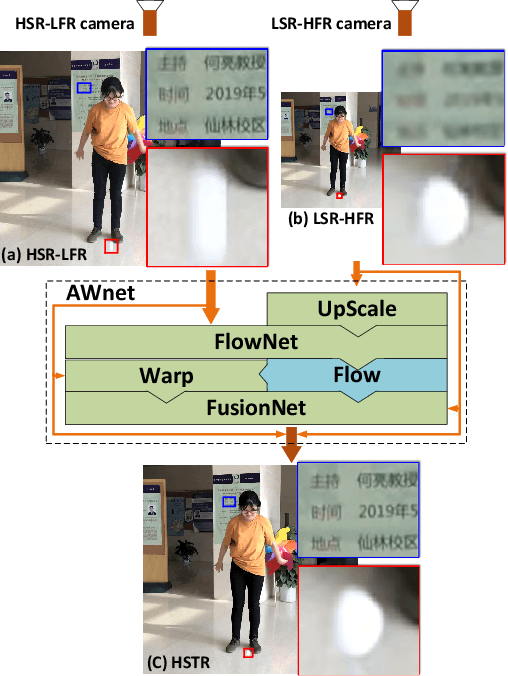

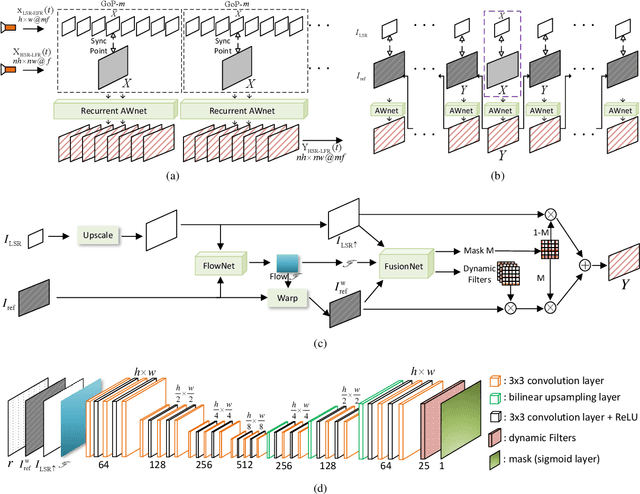
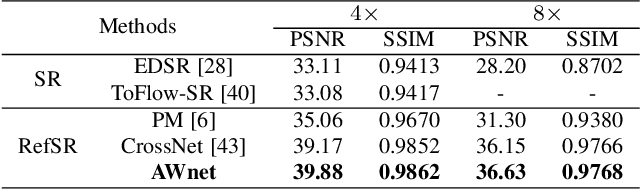
This paper presents a dual camera system for high spatiotemporal resolution (HSTR) video acquisition, where one camera shoots a video with high spatial resolution and low frame rate (HSR-LFR) and another one captures a low spatial resolution and high frame rate (LSR-HFR) video. Our main goal is to combine videos from LSR-HFR and HSR-LFR cameras to create an HSTR video. We propose an end-to-end learning framework, AWnet, mainly consisting of a FlowNet and a FusionNet that learn an adaptive weighting function in pixel domain to combine inputs in a frame recurrent fashion. To improve the reconstruction quality for cameras used in reality, we also introduce noise regularization under the same framework. Our method has demonstrated noticeable performance gains in terms of both objective PSNR measurement in simulation with different publicly available video and light-field datasets and subjective evaluation with real data captured by dual iPhone 7 and Grasshopper3 cameras. Ablation studies are further conducted to investigate and explore various aspects (such as noise regularization, camera parallax, exposure time, multiscale synthesis, etc) of our system to fully understand its capability for potential applications.
Depth-Aware Video Frame Interpolation
Apr 01, 2019
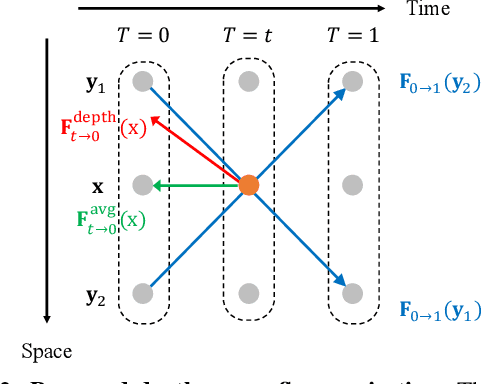
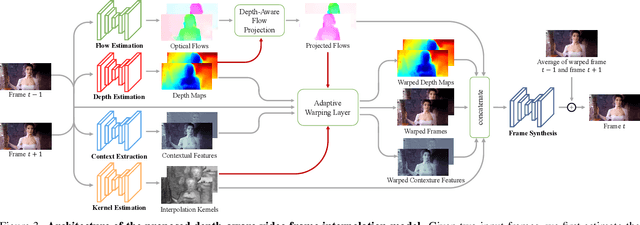
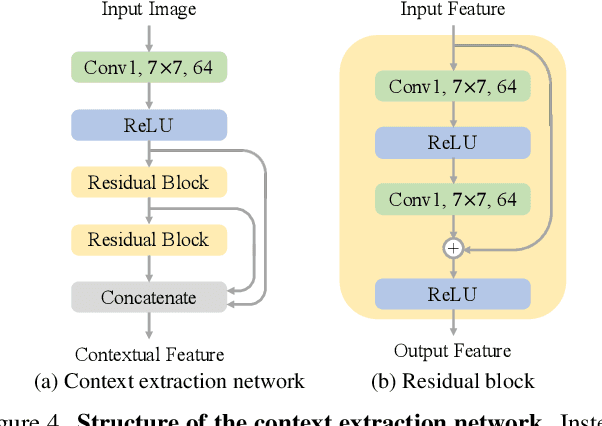
Video frame interpolation aims to synthesize nonexistent frames in-between the original frames. While significant advances have been made from the recent deep convolutional neural networks, the quality of interpolation is often reduced due to large object motion or occlusion. In this work, we propose a video frame interpolation method which explicitly detects the occlusion by exploring the depth information. Specifically, we develop a depth-aware flow projection layer to synthesize intermediate flows that preferably sample closer objects than farther ones. In addition, we learn hierarchical features to gather contextual information from neighboring pixels. The proposed model then warps the input frames, depth maps, and contextual features based on the optical flow and local interpolation kernels for synthesizing the output frame. Our model is compact, efficient, and fully differentiable. Quantitative and qualitative results demonstrate that the proposed model performs favorably against state-of-the-art frame interpolation methods on a wide variety of datasets.
MEMC-Net: Motion Estimation and Motion Compensation Driven Neural Network for Video Interpolation and Enhancement
Oct 20, 2018
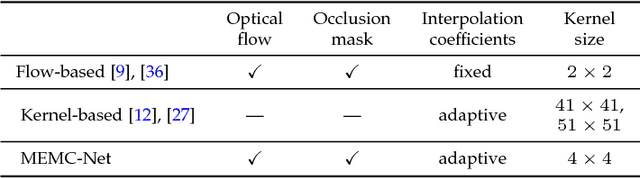
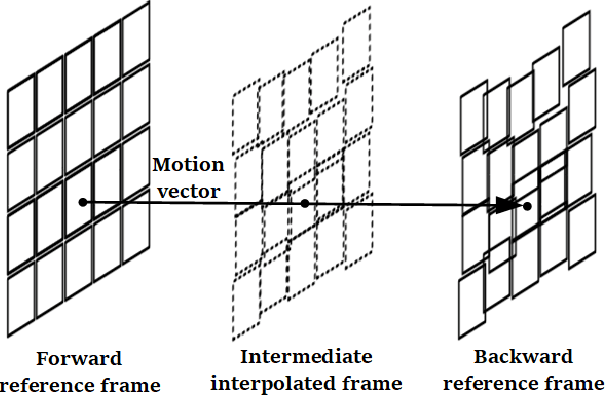
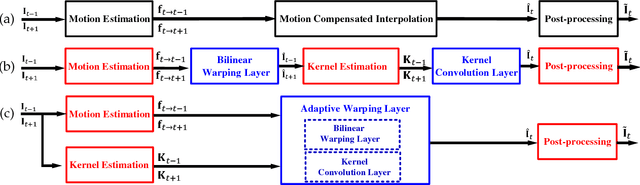
Motion estimation (ME) and motion compensation (MC) have been widely used for classical video frame interpolation systems over the past decades. Recently, a number of data-driven frame interpolation methods based on convolutional neural networks have been proposed. However, existing learning based methods typically estimate either flow or compensation kernels, thereby limiting performance on both computational efficiency and interpolation accuracy. In this work, we propose a motion estimation and compensation driven neural network for video frame interpolation. A novel adaptive warping layer is developed to integrate both optical flow and interpolation kernels to synthesize target frame pixels. This layer is fully differentiable such that both the flow and kernel estimation networks can be optimized jointly. The proposed model benefits from the advantages of motion estimation and compensation methods without using hand-crafted features. Compared to existing methods, our approach is computationally efficient and able to generate more visually appealing results. Furthermore, the proposed MEMC-Net can be seamlessly adapted to several video enhancement tasks, e.g., super-resolution, denoising, and deblocking. Extensive quantitative and qualitative evaluations demonstrate that the proposed method performs favorably against the state-of-the-art video frame interpolation and enhancement algorithms on a wide range of datasets.