 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEAN: Event Adaptive Network for Enhanced Action Recognition
Paper and Code
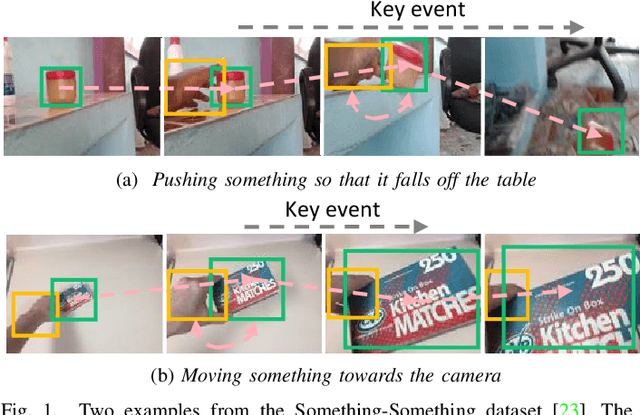
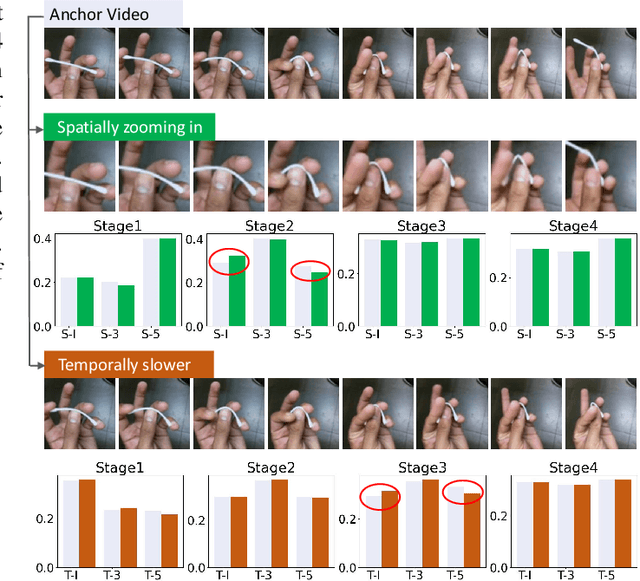
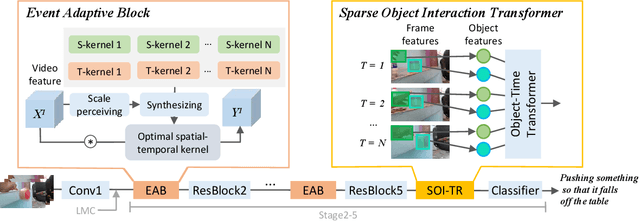
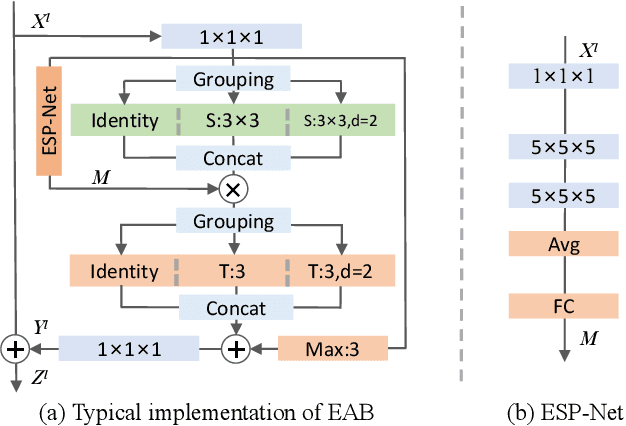
Efficiently modeling spatial-temporal information in videos is crucial for action recognition. To achieve this goal, state-of-the-art methods typically employ the convolution operator and the dense interaction modules such as non-local blocks. However, these methods cannot accurately fit the diverse events in videos. On the one hand, the adopted convolutions are with fixed scales, thus struggling with events of various scales. On the other hand, the dense interaction modeling paradigm only achieves sub-optimal performance as action-irrelevant parts bring additional noises for the final prediction. In this paper, we propose a unified action recognition framework to investigate the dynamic nature of video content by introducing the following designs. First, when extracting local cues, we generate the spatial-temporal kernels of dynamic-scale to adaptively fit the diverse events. Second, to accurately aggregate these cues into a global video representation, we propose to mine the interactions only among a few selected foreground objects by a Transformer, which yields a sparse paradigm. We call the proposed framework as Event Adaptive Network (EAN) because both key designs are adaptive to the input video content. To exploit the short-term motions within local segments, we propose a novel and efficient Latent Motion Code (LMC) module, further improving the performance of the framework. Extensive experiments on several large-scale video datasets, e.g., Something-to-Something V1&V2, Kinetics, and Diving48, verify that our models achieve state-of-the-art or competitive performances at low FLOPs. Codes are available at: https://github.com/tianyuan168326/EAN-Pytorch.