 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Learning Based Adaptive Cooperative Perception in Nonstationary Vehicular Networks
Oct 01, 2024
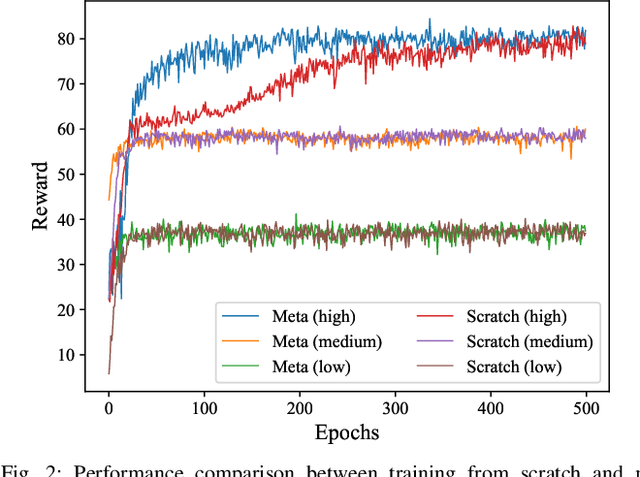
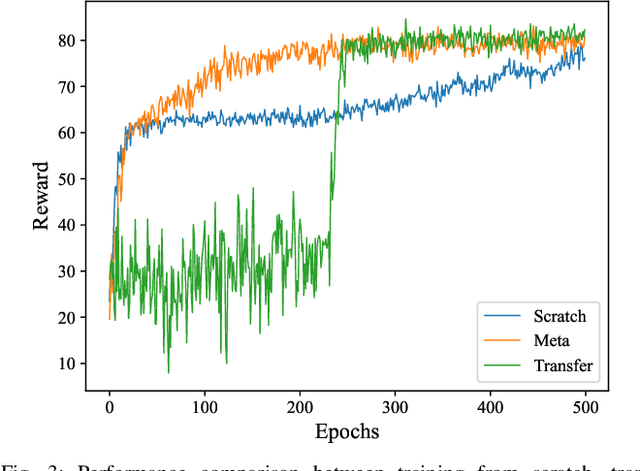
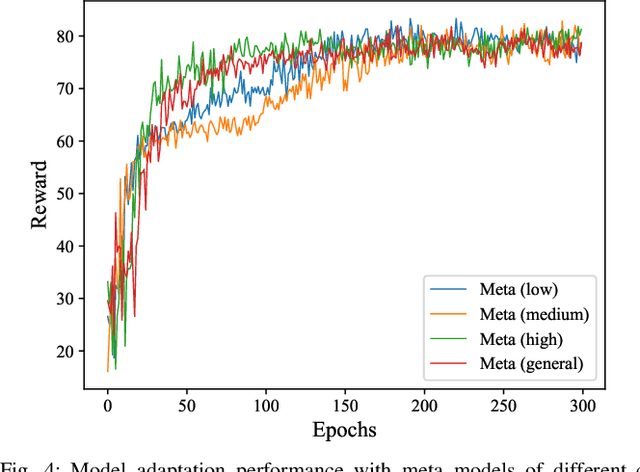
To accommodate high network dynamics in real-time cooperative perception (CP), reinforcement learning (RL) based adaptive CP schemes have been proposed, to allow adaptive switchings between CP and stand-alone perception modes among connected and autonomous vehicles. The traditional offline-training online-execution RL framework suffers from performance degradation under nonstationary network conditions. To achieve fast and efficient model adaptation, we formulate a set of Markov decision processes for adaptive CP decisions in each stationary local vehicular network (LVN). A meta RL solution is proposed, which trains a meta RL model that captures the general features among LVNs, thus facilitating fast model adaptation for each LVN with the meta RL model as an initial point. Simulation results show the superiority of meta RL in terms of the convergence speed without reward degradation. The impact of the customization level of meta models on the model adaptation performance has also been evaluated.
Single-Image 3D Face Reconstruction under Perspective Projection
May 09, 2022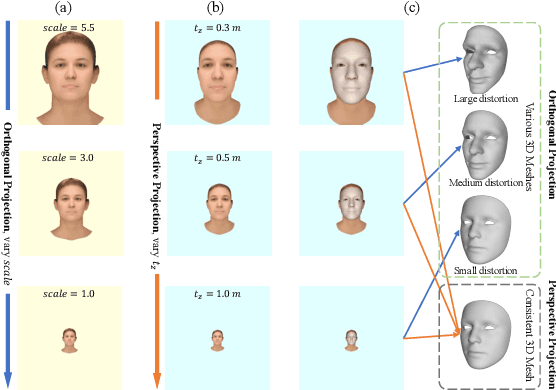
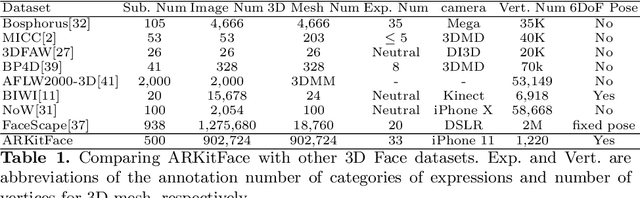
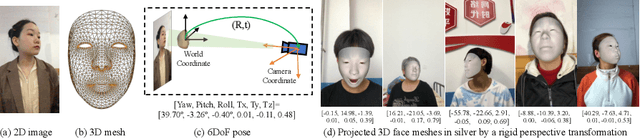

In 3D face reconstruction, orthogonal projection has been widely employed to substitute perspective projection to simplify the fitting process. This approximation performs well when the distance between camera and face is far enough. However, in some scenarios that the face is very close to camera or moving along the camera axis, the methods suffer from the inaccurate reconstruction and unstable temporal fitting due to the distortion under the perspective projection. In this paper, we aim to address the problem of single-image 3D face reconstruction under perspective projection. Specifically, a deep neural network, Perspective Network (PerspNet), is proposed to simultaneously reconstruct 3D face shape in canonical space and learn the correspondence between 2D pixels and 3D points, by which the 6DoF (6 Degrees of Freedom) face pose can be estimated to represent perspective projection. Besides, we contribute a large ARKitFace dataset to enable the training and evaluation of 3D face reconstruction solutions under the scenarios of perspective projection, which has 902,724 2D facial images with ground-truth 3D face mesh and annotated 6DoF pose parameters. Experimental results show that our approach outperforms current state-of-the-art methods by a significant margin.