 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Image 3D Face Reconstruction under Perspective Projection
May 09, 2022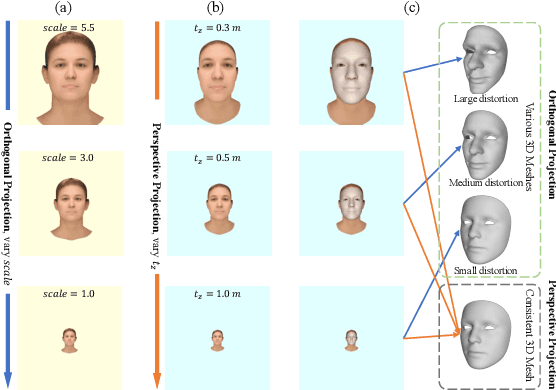
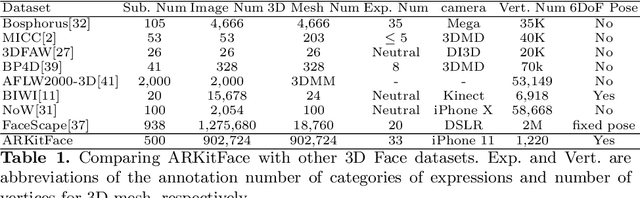
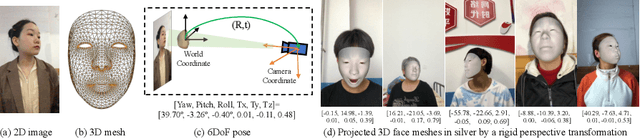

In 3D face reconstruction, orthogonal projection has been widely employed to substitute perspective projection to simplify the fitting process. This approximation performs well when the distance between camera and face is far enough. However, in some scenarios that the face is very close to camera or moving along the camera axis, the methods suffer from the inaccurate reconstruction and unstable temporal fitting due to the distortion under the perspective projection. In this paper, we aim to address the problem of single-image 3D face reconstruction under perspective projection. Specifically, a deep neural network, Perspective Network (PerspNet), is proposed to simultaneously reconstruct 3D face shape in canonical space and learn the correspondence between 2D pixels and 3D points, by which the 6DoF (6 Degrees of Freedom) face pose can be estimated to represent perspective projection. Besides, we contribute a large ARKitFace dataset to enable the training and evaluation of 3D face reconstruction solutions under the scenarios of perspective projection, which has 902,724 2D facial images with ground-truth 3D face mesh and annotated 6DoF pose parameters. Experimental results show that our approach outperforms current state-of-the-art methods by a significant margin.
Deep Aesthetic Quality Assessment with Semantic Information
Oct 21, 2016

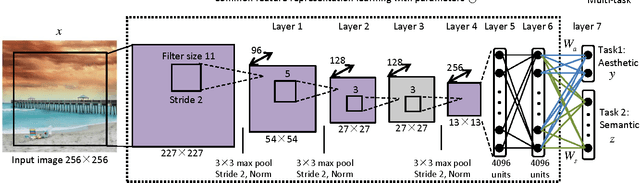
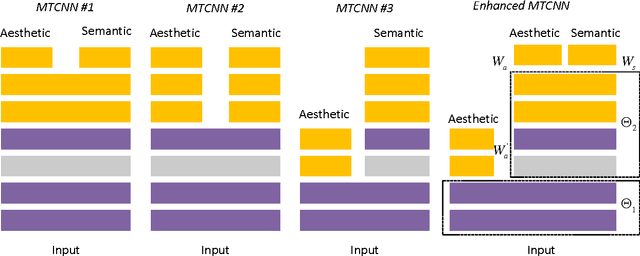
Human beings often assess the aesthetic quality of an image coupled with the identification of the image's semantic content. This paper addresses the correlation issue between automatic aesthetic quality assessment and semantic recognition. We cast the assessment problem as the main task among a multi-task deep model, and argue that semantic recognition task offers the key to address this problem. Based on convolutional neural networks, we employ a single and simple multi-task framework to efficiently utilize the supervision of aesthetic and semantic labels. A correlation item between these two tasks is further introduced to the framework by incorporating the inter-task relationship learning. This item not only provides some useful insight about the correlation but also improves assessment accuracy of the aesthetic task. Particularly, an effective strategy is developed to keep a balance between the two tasks, which facilitates to optimize the parameters of the framework. Extensive experiments on the challenging AVA dataset and Photo.net dataset validate the importance of semantic recognition in aesthetic quality assessment, and demonstrate that multi-task deep models can discover an effective aesthetic representation to achieve state-of-the-art results.