 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIP: Token Importance in On-Policy Distillation
Apr 15, 2026On-policy knowledge distillation (OPD) trains a student on its own rollouts under token-level supervision from a teacher. Not all token positions matter equally, but existing views of token importance are incomplete. We ask a direct question: which tokens carry the most useful learning signal in OPD? Our answer is that informative tokens come from two regions: positions with high student entropy, and positions with low student entropy plus high teacher--student divergence, where the student is overconfident and wrong. Empirically, student entropy is a strong first-order proxy: retaining $50\%$ of tokens with entropy-based sampling matches or exceeds all-token training while reducing peak memory by up to $47\%$. But entropy alone misses a second important region. When we isolate low-entropy, high-divergence tokens, training on fewer than $10\%$ of all tokens nearly matches full-token baselines, showing that overconfident tokens carry dense corrective signal despite being nearly invisible to entropy-only rules. We organize these findings with TIP (Token Importance in on-Policy distillation), a two-axis taxonomy over student entropy and teacher--student divergence, and give a theoretical explanation for why entropy is useful yet structurally incomplete. This view motivates type-aware token selection rules that combine uncertainty and disagreement. We validate this picture across three teacher--student pairs spanning Qwen3, Llama, and Qwen2.5 on MATH-500 and AIME 2024/2025, and on the DeepPlanning benchmark for long-horizon agentic planning, where Q3-only training on $<$$20\%$ of tokens surpasses full-token OPD. Our experiments are implemented by extending the OPD repository https://github.com/HJSang/OPSD_OnPolicyDistillation, which supports memory-efficient distillation of larger models under limited GPU budgets.
Robust Batch-Level Query Routing for Large Language Models under Cost and Capacity Constraints
Mar 25, 2026We study the problem of routing queries to large language models (LLMs) under cost, GPU resources, and concurrency constraints. Prior per-query routing methods often fail to control batch-level cost, especially under non-uniform or adversarial batching. To address this, we propose a batch-level, resource-aware routing framework that jointly optimizes model assignment for each batch while respecting cost and model capacity limits. We further introduce a robust variant that accounts for uncertainty in predicted LLM performance, along with an offline instance allocation procedure that balances quality and throughput across multiple models. Experiments on two multi-task LLM benchmarks show that robustness improves accuracy by 1-14% over non-robust counterparts (depending on the performance estimator), batch-level routing outperforms per-query methods by up to 24% under adversarial batching, and optimized instance allocation yields additional gains of up to 3% compared to a non-optimized allocation, all while strictly controlling cost and GPU resource constraints.
PACED: Distillation and Self-Distillation at the Frontier of Student Competence
Mar 16, 2026Standard LLM distillation wastes compute on two fronts: problems the student has already mastered (near-zero gradients) and problems far beyond its reach (incoherent gradients that erode existing capabilities). We show that this waste is not merely intuitive but structurally inevitable: the gradient signal-to-noise ratio in distillation provably vanishes at both pass-rate extremes. This theoretical observation leads to Paced, a framework that concentrates distillation on the zone of proximal development -- the frontier of a student model's competence -- via a principled pass-rate weight $w(p) = p^α(1 - p)^β$ derived from the boundary-vanishing structure of distillation gradients. Key results: (1) Theory: We prove that the Beta kernel $w(p) = p^α(1-p)^β$ is a leading-order weight family arising from the SNR structure of distillation, and that it is minimax-robust -- under bounded multiplicative misspecification, worst-case efficiency loss is only $O(δ^2)$. (2)Distillation: On distillation from a larger teacher to a smaller student model with forward KL, Paced achieves significant gain over the base model, while keeping benchmark forgetting at a low level. (3)Self-distillation: On instruction-tuned models with reverse KL, gains are exceeding baselines as well. (4)Two-stage synergy: A forward-KL-then-reverse-KL schedule yields the strongest results in our setting, reaching substantial improvements on standard reasoning benchmarks -- supporting a mode-coverage-then-consolidation interpretation of the distillation process. All configurations require only student rollouts to estimate pass rates, need no architectural changes, and are compatible with any KL direction.
PACED: Distillation at the Frontier of Student Competence
Mar 11, 2026Standard LLM distillation wastes compute on two fronts: problems the student has already mastered (near-zero gradients) and problems far beyond its reach (incoherent gradients that erode existing capabilities). We show that this waste is not merely intuitive but structurally inevitable: the gradient signal-to-noise ratio in distillation provably vanishes at both pass-rate extremes. This theoretical observation leads to Paced, a framework that concentrates distillation on the zone of proximal development -- the frontier of a student model's competence -- via a principled pass-rate weight $w(p) = p^α(1 - p)^β$ derived from the boundary-vanishing structure of distillation gradients. Key results: (1) Theory: We prove that the Beta kernel $w(p) = p^α(1-p)^β$ is a leading-order weight family arising from the SNR structure of distillation, and that it is minimax-robust -- under bounded multiplicative misspecification, worst-case efficiency loss is only $O(δ^2)$. (2)Distillation: On distillation from a larger teacher to a smaller student model with forward KL, Paced achieves significant gain over the base model, while keeping benchmark forgetting at a low level. (3)Self-distillation: On instruction-tuned models with reverse KL, gains are exceeding baselines as well. (4)Two-stage synergy: A forward-KL-then-reverse-KL schedule yields the strongest results in our setting, reaching substantial improvements on standard reasoning benchmarks -- supporting a mode-coverage-then-consolidation interpretation of the distillation process. All configurations require only student rollouts to estimate pass rates, need no architectural changes, and are compatible with any KL direction.
On-Policy Self-Distillation for Reasoning Compression
Mar 05, 2026Reasoning models think out loud, but much of what they say is noise. We introduce OPSDC (On-Policy Self-Distillation for Reasoning Compression), a method that teaches models to reason more concisely by distilling their own concise behavior back into themselves. The entire approach reduces to one idea: condition the same model on a "be concise" instruction to obtain teacher logits, and minimize per-token reverse KL on the student's own rollouts. No ground-truth answers, no token budgets, no difficulty estimators. Just self-distillation. Yet this simplicity belies surprising sophistication: OPSDC automatically compresses easy problems aggressively while preserving the deliberation needed for hard ones. On Qwen3-8B and Qwen3-14B, we achieve 57-59% token reduction on MATH-500 while improving accuracy by 9-16 points absolute. On AIME 2024, the 14B model gains 10 points with 41% compression. The secret? Much of what reasoning models produce is not just redundant-it is actively harmful, compounding errors with every unnecessary token.
Overconfident Errors Need Stronger Correction: Asymmetric Confidence Penalties for Reinforcement Learning
Feb 24, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has become the leading paradigm for enhancing reasoning in Large Language Models (LLMs). However, standard RLVR algorithms suffer from a well-documented pathology: while they improve Pass@1 accuracy through sharpened sampling, they simultaneously narrow the model's reasoning boundary and reduce generation diversity. We identify a root cause that existing methods overlook: the uniform penalization of errors. Current approaches -- whether data-filtering methods that select prompts by difficulty, or advantage normalization schemes -- treat all incorrect rollouts within a group identically. We show that this uniformity allows overconfident errors (incorrect reasoning paths that the RL process has spuriously reinforced) to persist and monopolize probability mass, ultimately suppressing valid exploratory trajectories. To address this, we propose the Asymmetric Confidence-aware Error Penalty (ACE). ACE introduces a per-rollout confidence shift metric, c_i = log(pi_theta(y_i|x) / pi_ref(y_i|x)), to dynamically modulate negative advantages. Theoretically, we demonstrate that ACE's gradient can be decomposed into the gradient of a selective regularizer restricted to overconfident errors, plus a well-characterized residual that partially moderates the regularizer's strength. We conduct extensive experiments fine-tuning Qwen2.5-Math-7B, Qwen3-8B-Base, and Llama-3.1-8B-Instruct on the DAPO-Math-17K dataset using GRPO and DAPO within the VERL framework. Evaluated on MATH-500 and AIME 2025, ACE composes seamlessly with existing methods and consistently improves the full Pass@k spectrum across all three model families and benchmarks.
Semantic Search At LinkedIn
Feb 07, 2026Semantic search with large language models (LLMs) enables retrieval by meaning rather than keyword overlap, but scaling it requires major inference efficiency advances. We present LinkedIn's LLM-based semantic search framework for AI Job Search and AI People Search, combining an LLM relevance judge, embedding-based retrieval, and a compact Small Language Model trained via multi-teacher distillation to jointly optimize relevance and engagement. A prefill-oriented inference architecture co-designed with model pruning, context compression, and text-embedding hybrid interactions boosts ranking throughput by over 75x under a fixed latency constraint while preserving near-teacher-level NDCG, enabling one of the first production LLM-based ranking systems with efficiency comparable to traditional approaches and delivering significant gains in quality and user engagement.
Examining spatial heterogeneity of ridesourcing demand determinants with explainable machine learning
Sep 16, 2022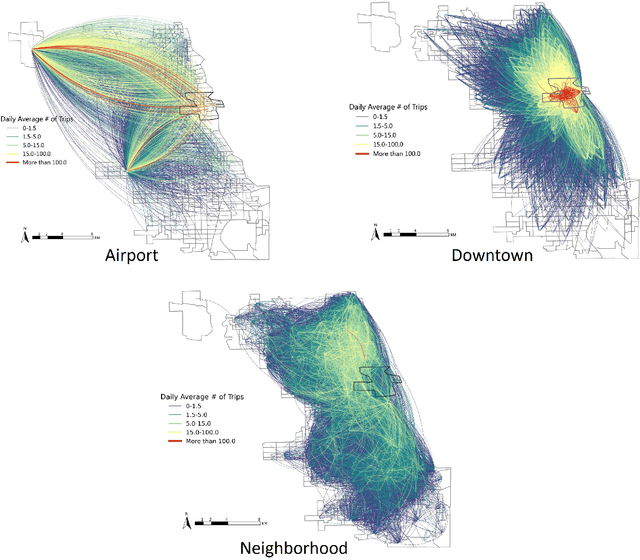

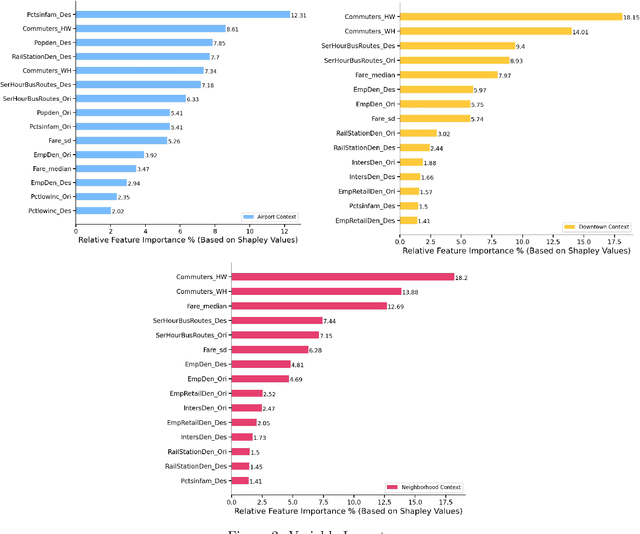

The growing significance of ridesourcing services in recent years suggests a need to examine the key determinants of ridesourcing demand. However, little is known regarding the nonlinear effects and spatial heterogeneity of ridesourcing demand determinants. This study applies an explainable-machine-learning-based analytical framework to identify the key factors that shape ridesourcing demand and to explore their nonlinear associations across various spatial contexts (airport, downtown, and neighborhood). We use the ridesourcing-trip data in Chicago for empirical analysis. The results reveal that the importance of built environment varies across spatial contexts, and it collectively contributes the largest importance in predicting ridesourcing demand for airport trips. Additionally, the nonlinear effects of built environment on ridesourcing demand show strong spatial variations. Ridesourcing demand is usually most responsive to the built environment changes for downtown trips, followed by neighborhood trips and airport trips. These findings offer transportation professionals nuanced insights for managing ridesourcing services.
S-LIME: Stabilized-LIME for Model Explanation
Jun 15, 2021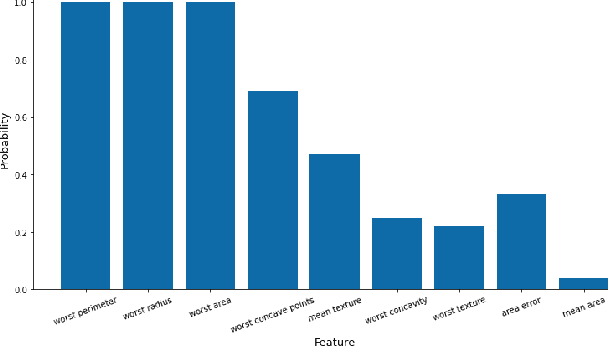
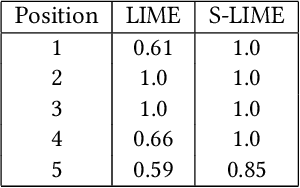
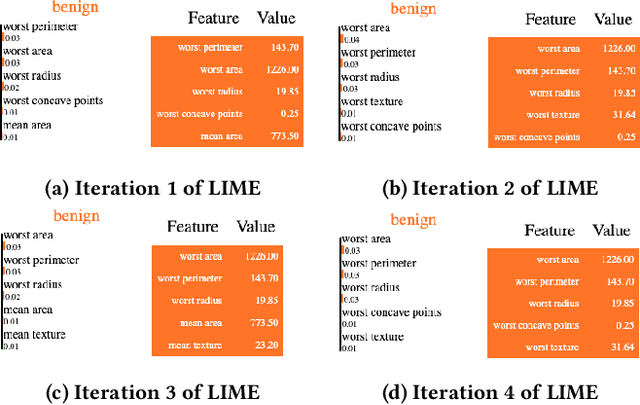
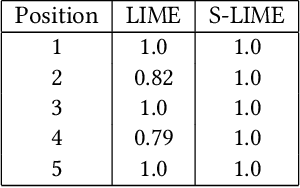
An increasing number of machine learning models have been deployed in domains with high stakes such as finance and healthcare. Despite their superior performances, many models are black boxes in nature which are hard to explain. There are growing efforts for researchers to develop methods to interpret these black-box models. Post hoc explanations based on perturbations, such as LIME, are widely used approaches to interpret a machine learning model after it has been built. This class of methods has been shown to exhibit large instability, posing serious challenges to the effectiveness of the method itself and harming user trust. In this paper, we propose S-LIME, which utilizes a hypothesis testing framework based on central limit theorem for determining the number of perturbation points needed to guarantee stability of the resulting explanation. Experiments on both simulated and real world data sets are provided to demonstrate the effectiveness of our method.
Asymptotic Normality and Variance Estimation For Supervised Ensembles
Dec 02, 2019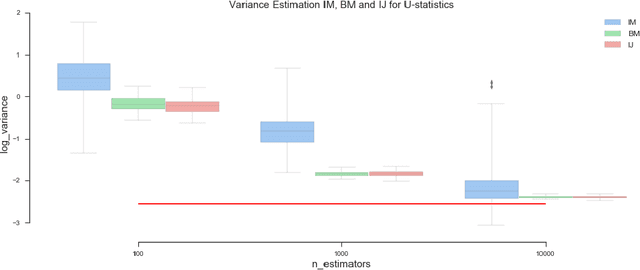
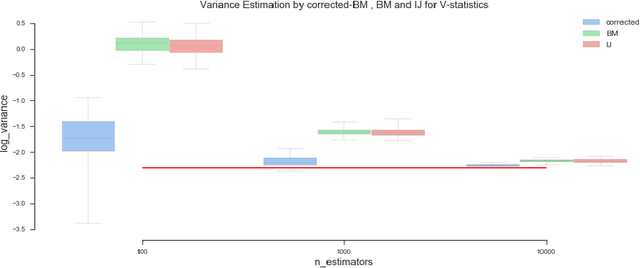
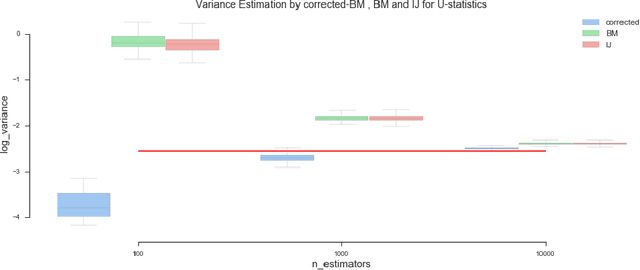
Ensemble methods based on bootstrapping have improved the predictive accuracy of base learners, but fail to provide a framework in which formal statistical inference can be conducted. Recent theoretical developments suggest taking subsamples without replacement and analyze the resulting estimator in the context of a U-statistic, thus demonstrating asymptotic normality properties. However, we observe that current methods for variance estimation exhibit severe bias when the number of base learners is not large enough, compromising the validity of the resulting confidence intervals or hypothesis tests. This paper shows that similar asymptotics can be achieved by means of V-statistics, corresponding to taking subsamples with replacement. Further, we develop a bias correction algorithm for estimating variance in the limiting distribution, which yields satisfactory results with moderate size of base learners.