 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximation Trees: Statistical Stability in Model Distillation
Paper and Code
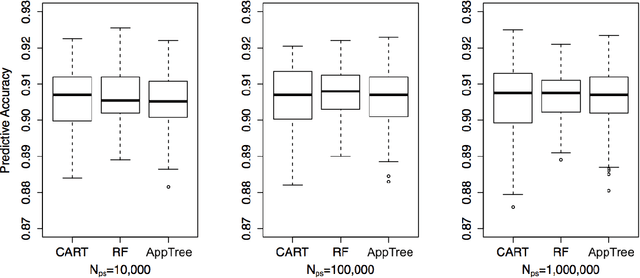
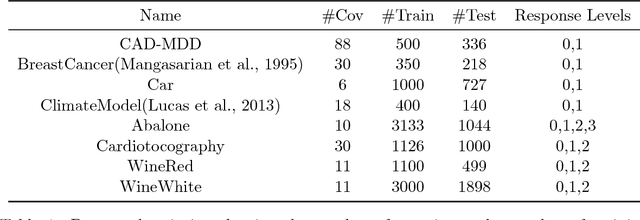
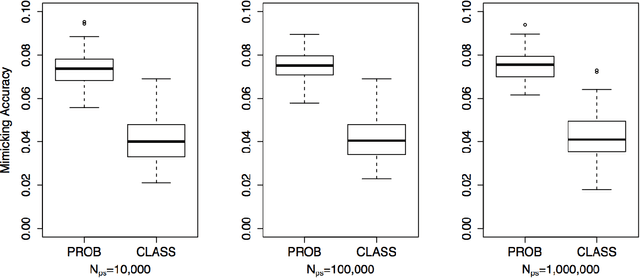
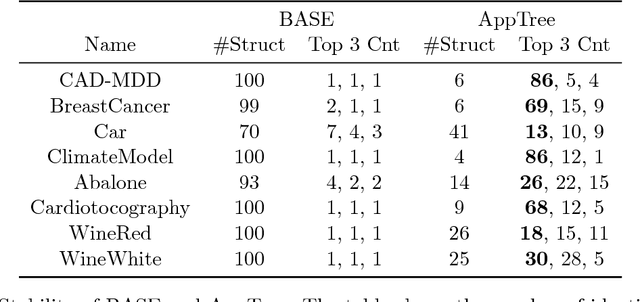
This paper examines the stability of learned explanations for black-box predictions via model distillation with decision trees. One approach to intelligibility in machine learning is to use an understandable `student' model to mimic the output of an accurate `teacher'. Here, we consider the use of regression trees as a student model, in which nodes of the tree can be used as `explanations' for particular predictions, and the whole structure of the tree can be used as a global representation of the resulting function. However, individual trees are sensitive to the particular data sets used to train them, and an interpretation of a student model may be suspect if small changes in the training data have a large effect on it. In this context, access to outcomes from a teacher helps to stabilize the greedy splitting strategy by generating a much larger corpus of training examples than was originally available. We develop tests to ensure that enough examples are generated at each split so that the same splitting rule would be chosen with high probability were the tree to be re trained. Further, we develop a stopping rule to indicate how deep the tree should be built based on recent results on the variability of Random Forests when these are used as the teacher. We provide concrete examples of these procedures on the CAD-MDD and COMPAS data sets.