 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThousand-GPU Large-Scale Training and Optimization Recipe for AI-Native Cloud Embodied Intelligence Infrastructure
Mar 11, 2026Embodied intelligence is a key step towards Artificial General Intelligence (AGI), yet its development faces multiple challenges including data, frameworks, infrastructure, and evaluation systems. To address these issues, we have, for the first time in the industry, launched a cloud-based, thousand-GPU distributed training platform for embodied intelligence, built upon the widely adopted LeRobot framework, and have systematically overcome bottlenecks across the entire pipeline. At the data layer, we have restructured the data pipeline to optimize the flow of embodied training data. In terms of training, for the GR00T-N1.5 model, utilizing thousand-GPU clusters and data at the scale of hundreds of millions, the single-round training time has been reduced from 15 hours to just 22 minutes, achieving a 40-fold speedup. At the model layer, by combining variable-length FlashAttention and Data Packing, we have moved from sample redundancy to sequence integration, resulting in a 188% speed increase; π-0.5 attention optimization has accelerated training by 165%; and FP8 quantization has delivered a 140% speedup. On the infrastructure side, relying on high-performance storage, a 3.2T RDMA network, and a Ray-driven elastic AI data lake, we have achieved deep synergy among data, storage, communication, and computation. We have also built an end-to-end evaluation system, creating a closed loop from training to simulation to assessment. This framework has already been fully validated on thousand-GPU clusters, laying a crucial technical foundation for the development and application of next-generation autonomous intelligent robots, and is expected to accelerate the arrival of the era of human-machine integration.
RL-VLA$^3$: Reinforcement Learning VLA Accelerating via Full Asynchronism
Feb 05, 2026In recent years, Vision-Language-Action (VLA) models have emerged as a crucial pathway towards general embodied intelligence, yet their training efficiency has become a key bottleneck. Although existing reinforcement learning (RL)-based training frameworks like RLinf can enhance model generalization, they still rely on synchronous execution, leading to severe resource underutilization and throughput limitations during environment interaction, policy generation (rollout), and model update phases (actor). To overcome this challenge, this paper, for the first time, proposes and implements a fully-asynchronous policy training framework encompassing the entire pipeline from environment interaction, rollout generation, to actor policy updates. Systematically drawing inspiration from asynchronous optimization ideas in large model RL, our framework designs a multi-level decoupled architecture. This includes asynchronous parallelization of environment interaction and trajectory collection, streaming execution for policy generation, and decoupled scheduling for training updates. We validated the effectiveness of our method across diverse VLA models and environments. On the LIBERO benchmark, the framework achieves throughput improvements of up to 59.25\% compared to existing synchronous strategies. When deeply optimizing separation strategies, throughput can be increased by as much as 126.67\%. We verified the effectiveness of each asynchronous component via ablation studies. Scaling law validation across 8 to 256 GPUs demonstrates our method's excellent scalability under most conditions.
Large-Scale Contextual Market Equilibrium Computation through Deep Learning
Jun 11, 2024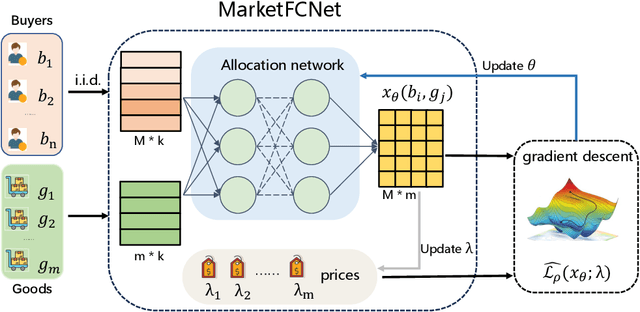
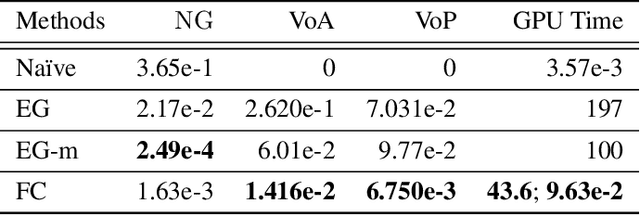
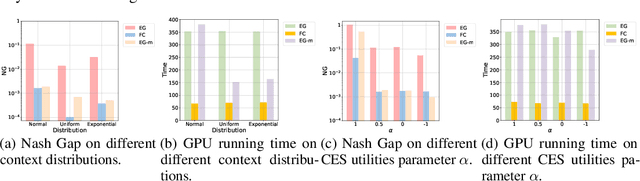
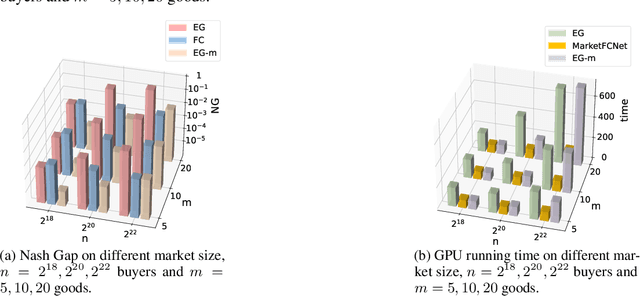
Market equilibrium is one of the most fundamental solution concepts in economics and social optimization analysis. Existing works on market equilibrium computation primarily focus on settings with a relatively small number of buyers. Motivated by this, our paper investigates the computation of market equilibrium in scenarios with a large-scale buyer population, where buyers and goods are represented by their contexts. Building on this realistic and generalized contextual market model, we introduce MarketFCNet, a deep learning-based method for approximating market equilibrium. We start by parameterizing the allocation of each good to each buyer using a neural network, which depends solely on the context of the buyer and the good. Next, we propose an efficient method to estimate the loss function of the training algorithm unbiasedly, enabling us to optimize the network parameters through gradient descent. To evaluate the approximated solution, we introduce a metric called Nash Gap, which quantifies the deviation of the given allocation and price pair from the market equilibrium. Experimental results indicate that MarketFCNet delivers competitive performance and significantly lower running times compared to existing methods as the market scale expands, demonstrating the potential of deep learning-based methods to accelerate the approximation of large-scale contextual market equilibrium.
Are Equivariant Equilibrium Approximators Beneficial?
Jan 27, 2023Recently, remarkable progress has been made by approximating Nash equilibrium (NE), correlated equilibrium (CE), and coarse correlated equilibrium (CCE) through function approximation that trains a neural network to predict equilibria from game representations. Furthermore, equivariant architectures are widely adopted in designing such equilibrium approximators in normal-form games. In this paper, we theoretically characterize benefits and limitations of equivariant equilibrium approximators. For the benefits, we show that they enjoy better generalizability than general ones and can achieve better approximations when the payoff distribution is permutation-invariant. For the limitations, we discuss their drawbacks in terms of equilibrium selection and social welfare. Together, our results help to understand the role of equivariance in equilibrium approximators.