 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHessian Averaging in Stochastic Newton Methods Achieves Superlinear Convergence
Paper and Code

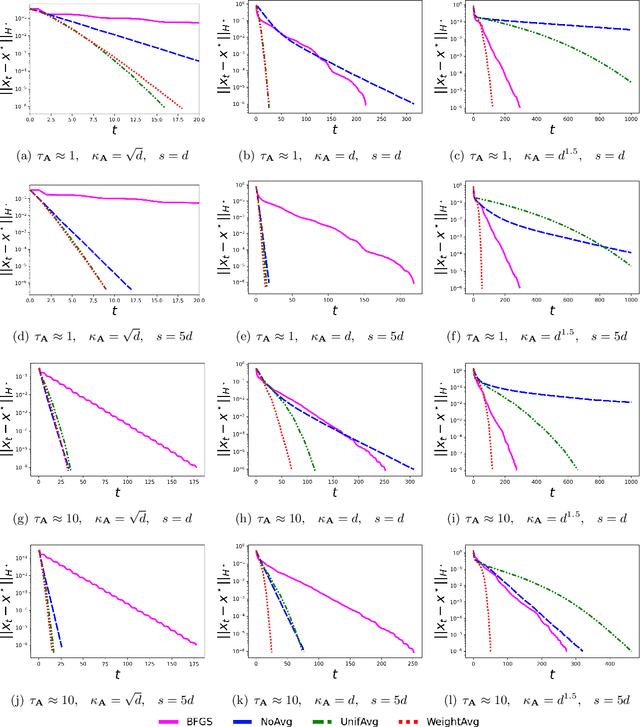
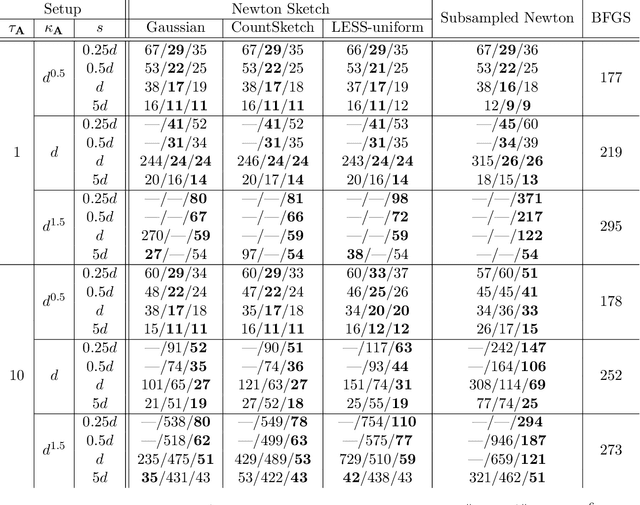

We consider minimizing a smooth and strongly convex objective function using a stochastic Newton method. At each iteration, the algorithm is given an oracle access to a stochastic estimate of the Hessian matrix. The oracle model includes popular algorithms such as the Subsampled Newton and Newton Sketch, which can efficiently construct stochastic Hessian estimates for many tasks. Despite using second-order information, these existing methods do not exhibit superlinear convergence, unless the stochastic noise is gradually reduced to zero during the iteration, which would lead to a computational blow-up in the per-iteration cost. We address this limitation with Hessian averaging: instead of using the most recent Hessian estimate, our algorithm maintains an average of all past estimates. This reduces the stochastic noise while avoiding the computational blow-up. We show that this scheme enjoys local $Q$-superlinear convergence with a non-asymptotic rate of $(\Upsilon\sqrt{\log (t)/t}\,)^{t}$, where $\Upsilon$ is proportional to the level of stochastic noise in the Hessian oracle. A potential drawback of this (uniform averaging) approach is that the averaged estimates contain Hessian information from the global phase of the iteration, i.e., before the iterates converge to a local neighborhood. This leads to a distortion that may substantially delay the superlinear convergence until long after the local neighborhood is reached. To address this drawback, we study a number of weighted averaging schemes that assign larger weights to recent Hessians, so that the superlinear convergence arises sooner, albeit with a slightly slower rate. Remarkably, we show that there exists a universal weighted averaging scheme that transitions to local convergence at an optimal stage, and still enjoys a superlinear convergence~rate nearly (up to a logarithmic factor) matching that of uniform Hessian averaging.