 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmplification Effects in Test-Time Reinforcement Learning: Safety and Reasoning Vulnerabilities
Mar 16, 2026Test-time training (TTT) has recently emerged as a promising method to improve the reasoning abilities of large language models (LLMs), in which the model directly learns from test data without access to labels. However, this reliance on test data also makes TTT methods vulnerable to harmful prompt injections. In this paper, we investigate safety vulnerabilities of TTT methods, where we study a representative self-consistency-based test-time learning method: test-time reinforcement learning (TTRL), a recent TTT method that improves LLM reasoning by rewarding self-consistency using majority vote as a reward signal. We show that harmful prompt injection during TTRL amplifies the model's existing behaviors, i.e., safety amplification when the base model is relatively safe, and harmfulness amplification when it is vulnerable to the injected data. In both cases, there is a decline in reasoning ability, which we refer to as the reasoning tax. We also show that TTT methods such as TTRL can be exploited adversarially using specially designed "HarmInject" prompts to force the model to answer jailbreak and reasoning queries together, resulting in stronger harmfulness amplification. Overall, our results highlight that TTT methods that enhance LLM reasoning by promoting self-consistency can lead to amplification behaviors and reasoning degradation, highlighting the need for safer TTT methods.
Detecting Zero-Day Attacks in Digital Substations via In-Context Learning
Jan 27, 2025



The occurrences of cyber attacks on the power grids have been increasing every year, with novel attack techniques emerging every year. In this paper, we address the critical challenge of detecting novel/zero-day attacks in digital substations that employ the IEC-61850 communication protocol. While many heuristic and machine learning (ML)-based methods have been proposed for attack detection in IEC-61850 digital substations, generalization to novel or zero-day attacks remains challenging. We propose an approach that leverages the in-context learning (ICL) capability of the transformer architecture, the fundamental building block of large language models. The ICL approach enables the model to detect zero-day attacks and learn from a few examples of that attack without explicit retraining. Our experiments on the IEC-61850 dataset demonstrate that the proposed method achieves more than $85\%$ detection accuracy on zero-day attacks while the existing state-of-the-art baselines fail. This work paves the way for building more secure and resilient digital substations of the future.
Optimization Solution Functions as Deterministic Policies for Offline Reinforcement Learning
Aug 27, 2024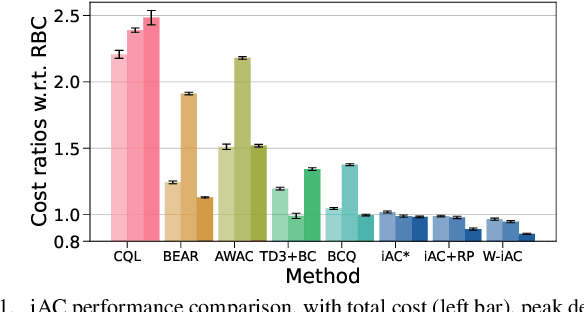
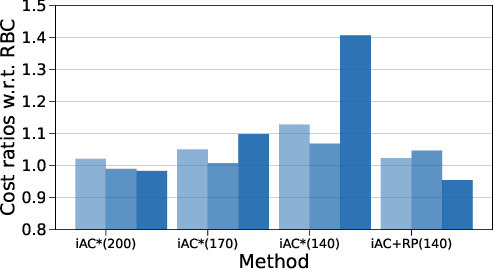
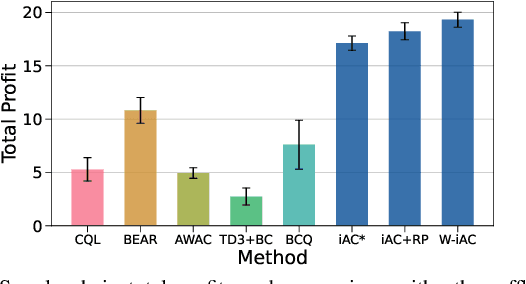
Offline reinforcement learning (RL) is a promising approach for many control applications but faces challenges such as limited data coverage and value function overestimation. In this paper, we propose an implicit actor-critic (iAC) framework that employs optimization solution functions as a deterministic policy (actor) and a monotone function over the optimal value of optimization as a critic. By encoding optimality in the actor policy, we show that the learned policies are robust to the suboptimality of the learned actor parameters via the exponentially decaying sensitivity (EDS) property. We obtain performance guarantees for the proposed iAC framework and show its benefits over general function approximation schemes. Finally, we validate the proposed framework on two real-world applications and show a significant improvement over state-of-the-art (SOTA) offline RL methods.
* American Control Conference 2024
A CMDP-within-online framework for Meta-Safe Reinforcement Learning
May 26, 2024



Meta-reinforcement learning has widely been used as a learning-to-learn framework to solve unseen tasks with limited experience. However, the aspect of constraint violations has not been adequately addressed in the existing works, making their application restricted in real-world settings. In this paper, we study the problem of meta-safe reinforcement learning (Meta-SRL) through the CMDP-within-online framework to establish the first provable guarantees in this important setting. We obtain task-averaged regret bounds for the reward maximization (optimality gap) and constraint violations using gradient-based meta-learning and show that the task-averaged optimality gap and constraint satisfaction improve with task-similarity in a static environment or task-relatedness in a dynamic environment. Several technical challenges arise when making this framework practical. To this end, we propose a meta-algorithm that performs inexact online learning on the upper bounds of within-task optimality gap and constraint violations estimated by off-policy stationary distribution corrections. Furthermore, we enable the learning rates to be adapted for every task and extend our approach to settings with a competing dynamically changing oracle. Finally, experiments are conducted to demonstrate the effectiveness of our approach.
Algorithm of Thoughts: Enhancing Exploration of Ideas in Large Language Models
Aug 20, 2023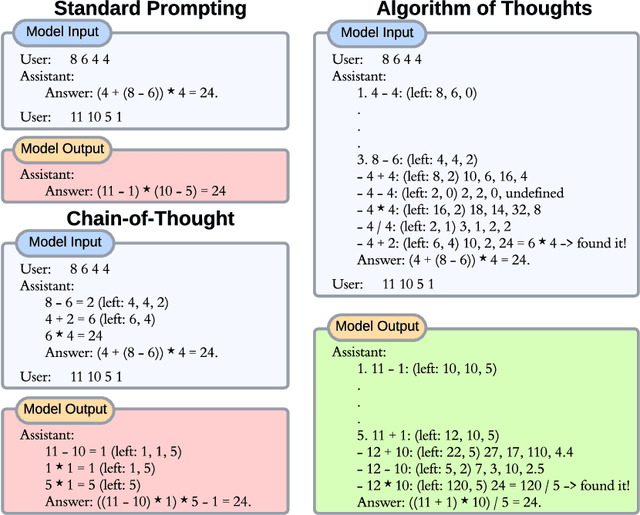
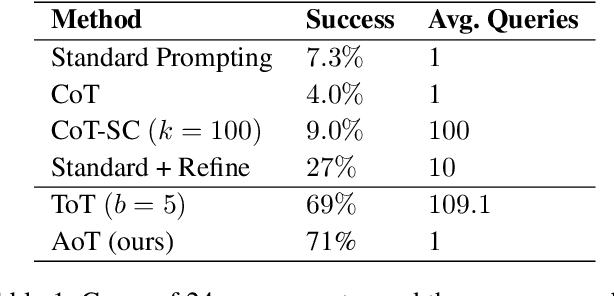
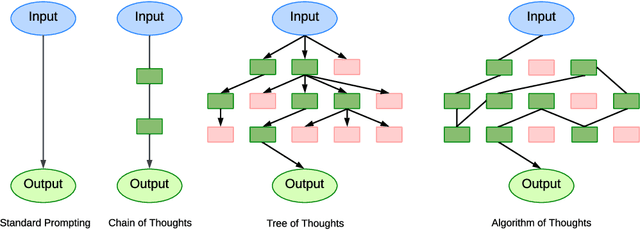

Current literature, aiming to surpass the "Chain-of-Thought" approach, often resorts to an external modus operandi involving halting, modifying, and then resuming the generation process to boost Large Language Models' (LLMs) reasoning capacities. This mode escalates the number of query requests, leading to increased costs, memory, and computational overheads. Addressing this, we propose the Algorithm of Thoughts -- a novel strategy that propels LLMs through algorithmic reasoning pathways, pioneering a new mode of in-context learning. By employing algorithmic examples, we exploit the innate recurrence dynamics of LLMs, expanding their idea exploration with merely one or a few queries. Our technique outperforms earlier single-query methods and stands on par with a recent multi-query strategy that employs an extensive tree search algorithm. Intriguingly, our results suggest that instructing an LLM using an algorithm can lead to performance surpassing that of the algorithm itself, hinting at LLM's inherent ability to weave its intuition into optimized searches. We probe into the underpinnings of our method's efficacy and its nuances in application.
Winning the CityLearn Challenge: Adaptive Optimization with Evolutionary Search under Trajectory-based Guidance
Dec 04, 2022Modern power systems will have to face difficult challenges in the years to come: frequent blackouts in urban areas caused by high power demand peaks, grid instability exacerbated by intermittent renewable generation, and global climate change amplified by rising carbon emissions. While current practices are growingly inadequate, the path to widespread adoption of artificial intelligence (AI) methods is hindered by missing aspects of trustworthiness. The CityLearn Challenge is an exemplary opportunity for researchers from multiple disciplines to investigate the potential of AI to tackle these pressing issues in the energy domain, collectively modeled as a reinforcement learning (RL) task. Multiple real-world challenges faced by contemporary RL techniques are embodied in the problem formulation. In this paper, we present a novel method using the solution function of optimization as policies to compute actions for sequential decision-making, while notably adapting the parameters of the optimization model from online observations. Algorithmically, this is achieved by an evolutionary algorithm under a novel trajectory-based guidance scheme. Formally, the global convergence property is established. Our agent ranked first in the latest 2021 CityLearn Challenge, being able to achieve superior performance in almost all metrics while maintaining some key aspects of interpretability.
On Solution Functions of Optimization: Universal Approximation and Covering Number Bounds
Dec 02, 2022



We study the expressibility and learnability of convex optimization solution functions and their multi-layer architectural extension. The main results are: \emph{(1)} the class of solution functions of linear programming (LP) and quadratic programming (QP) is a universal approximant for the $C^k$ smooth model class or some restricted Sobolev space, and we characterize the rate-distortion, \emph{(2)} the approximation power is investigated through a viewpoint of regression error, where information about the target function is provided in terms of data observations, \emph{(3)} compositionality in the form of a deep architecture with optimization as a layer is shown to reconstruct some basic functions used in numerical analysis without error, which implies that \emph{(4)} a substantial reduction in rate-distortion can be achieved with a universal network architecture, and \emph{(5)} we discuss the statistical bounds of empirical covering numbers for LP/QP, as well as a generic optimization problem (possibly nonconvex) by exploiting tame geometry. Our results provide the \emph{first rigorous analysis of the approximation and learning-theoretic properties of solution functions} with implications for algorithmic design and performance guarantees.