 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCP-Atlas: A Large-Scale Benchmark for Tool-Use Competency with Real MCP Servers
Jan 31, 2026The Model Context Protocol (MCP) is rapidly becoming the standard interface for Large Language Models (LLMs) to discover and invoke external tools. However, existing evaluations often fail to capture the complexity of real-world scenarios, relying on restricted toolsets, simplistic workflows, or subjective LLM-as-a-judge metrics. We introduce MCP-Atlas, a large-scale benchmark for evaluating tool-use competency, comprising 36 real MCP servers and 220 tools. It includes 1,000 tasks designed to assess tool-use competency in realistic, multi-step workflows. Tasks use natural language prompts that avoid naming specific tools or servers, requiring agents to identify and orchestrate 3-6 tool calls across multiple servers. We score tasks using a claims-based rubric that awards partial credit based on the factual claims satisfied in the model's final answer, complemented by internal diagnostics on tool discovery, parameterization, syntax, error recovery, and efficiency. Evaluation results on frontier models reveal that top models achieve pass rates exceeding 50%, with primary failures arising from inadequate tool usage and task understanding. We release the task schema, containerized harness, and a 500-task public subset of the benchmark dataset to facilitate reproducible comparisons and advance the development of robust, tool-augmented agents.
ResearchRubrics: A Benchmark of Prompts and Rubrics For Evaluating Deep Research Agents
Nov 10, 2025Deep Research (DR) is an emerging agent application that leverages large language models (LLMs) to address open-ended queries. It requires the integration of several capabilities, including multi-step reasoning, cross-document synthesis, and the generation of evidence-backed, long-form answers. Evaluating DR remains challenging because responses are lengthy and diverse, admit many valid solutions, and often depend on dynamic information sources. We introduce ResearchRubrics, a standardized benchmark for DR built with over 2,800+ hours of human labor that pairs realistic, domain-diverse prompts with 2,500+ expert-written, fine-grained rubrics to assess factual grounding, reasoning soundness, and clarity. We also propose a new complexity framework for categorizing DR tasks along three axes: conceptual breadth, logical nesting, and exploration. In addition, we develop human and model-based evaluation protocols that measure rubric adherence for DR agents. We evaluate several state-of-the-art DR systems and find that even leading agents like Gemini's DR and OpenAI's DR achieve under 68% average compliance with our rubrics, primarily due to missed implicit context and inadequate reasoning about retrieved information. Our results highlight the need for robust, scalable assessment of deep research capabilities, to which end we release ResearchRubrics(including all prompts, rubrics, and evaluation code) to facilitate progress toward well-justified research assistants.
Remote Labor Index: Measuring AI Automation of Remote Work
Oct 30, 2025AIs have made rapid progress on research-oriented benchmarks of knowledge and reasoning, but it remains unclear how these gains translate into economic value and automation. To measure this, we introduce the Remote Labor Index (RLI), a broadly multi-sector benchmark comprising real-world, economically valuable projects designed to evaluate end-to-end agent performance in practical settings. AI agents perform near the floor on RLI, with the highest-performing agent achieving an automation rate of 2.5%. These results help ground discussions of AI automation in empirical evidence, setting a common basis for tracking AI impacts and enabling stakeholders to proactively navigate AI-driven labor automation.
Why Would You Suggest That? Human Trust in Language Model Responses
Jun 04, 2024
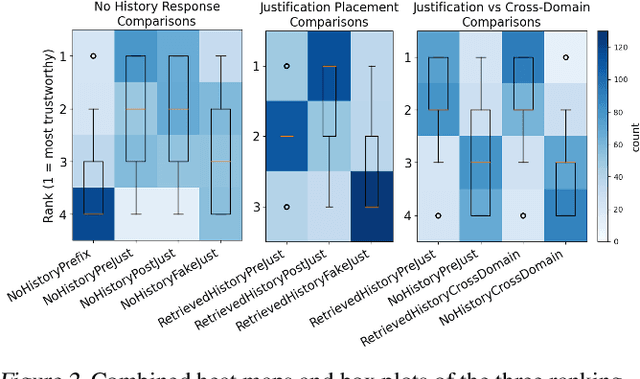

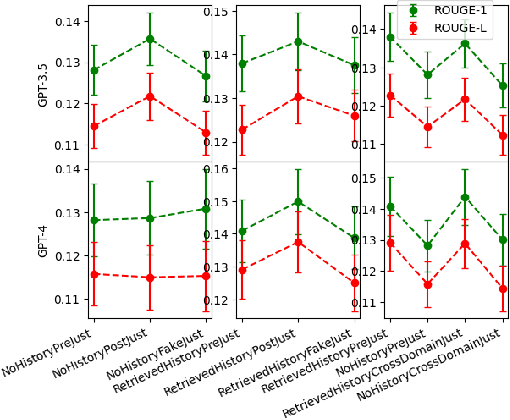
The emergence of Large Language Models (LLMs) has revealed a growing need for human-AI collaboration, especially in creative decision-making scenarios where trust and reliance are paramount. Through human studies and model evaluations on the open-ended News Headline Generation task from the LaMP benchmark, we analyze how the framing and presence of explanations affect user trust and model performance. Overall, we provide evidence that adding an explanation in the model response to justify its reasoning significantly increases self-reported user trust in the model when the user has the opportunity to compare various responses. Position and faithfulness of these explanations are also important factors. However, these gains disappear when users are shown responses independently, suggesting that humans trust all model responses, including deceptive ones, equitably when they are shown in isolation. Our findings urge future research to delve deeper into the nuanced evaluation of trust in human-machine teaming systems.
BEHAVIOR-1K: A Human-Centered, Embodied AI Benchmark with 1,000 Everyday Activities and Realistic Simulation
Mar 14, 2024



We present BEHAVIOR-1K, a comprehensive simulation benchmark for human-centered robotics. BEHAVIOR-1K includes two components, guided and motivated by the results of an extensive survey on "what do you want robots to do for you?". The first is the definition of 1,000 everyday activities, grounded in 50 scenes (houses, gardens, restaurants, offices, etc.) with more than 9,000 objects annotated with rich physical and semantic properties. The second is OMNIGIBSON, a novel simulation environment that supports these activities via realistic physics simulation and rendering of rigid bodies, deformable bodies, and liquids. Our experiments indicate that the activities in BEHAVIOR-1K are long-horizon and dependent on complex manipulation skills, both of which remain a challenge for even state-of-the-art robot learning solutions. To calibrate the simulation-to-reality gap of BEHAVIOR-1K, we provide an initial study on transferring solutions learned with a mobile manipulator in a simulated apartment to its real-world counterpart. We hope that BEHAVIOR-1K's human-grounded nature, diversity, and realism make it valuable for embodied AI and robot learning research. Project website: https://behavior.stanford.edu.
Exploring and Improving the Spatial Reasoning Abilities of Large Language Models
Dec 02, 2023



Large Language Models (LLMs) represent formidable tools for sequence modeling, boasting an innate capacity for general pattern recognition. Nevertheless, their broader spatial reasoning capabilities, especially applied to numerical trajectory data, remain insufficiently explored. In this paper, we investigate the out-of-the-box performance of ChatGPT-3.5, ChatGPT-4 and Llama 2 7B models when confronted with 3D robotic trajectory data from the CALVIN baseline and associated tasks, including 2D directional and shape labeling. Additionally, we introduce a novel prefix-based prompting mechanism, which yields a 33% improvement on the 3D trajectory data and an increase of up to 10% on SpartQA tasks over zero-shot prompting (with gains for other prompting types as well). The experimentation with 3D trajectory data offers an intriguing glimpse into the manner in which LLMs engage with numerical and spatial information, thus laying a solid foundation for the identification of target areas for future enhancements.