 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHY-Motion 1.0: Scaling Flow Matching Models for Text-To-Motion Generation
Dec 29, 2025We present HY-Motion 1.0, a series of state-of-the-art, large-scale, motion generation models capable of generating 3D human motions from textual descriptions. HY-Motion 1.0 represents the first successful attempt to scale up Diffusion Transformer (DiT)-based flow matching models to the billion-parameter scale within the motion generation domain, delivering instruction-following capabilities that significantly outperform current open-source benchmarks. Uniquely, we introduce a comprehensive, full-stage training paradigm -- including large-scale pretraining on over 3,000 hours of motion data, high-quality fine-tuning on 400 hours of curated data, and reinforcement learning from both human feedback and reward models -- to ensure precise alignment with the text instruction and high motion quality. This framework is supported by our meticulous data processing pipeline, which performs rigorous motion cleaning and captioning. Consequently, our model achieves the most extensive coverage, spanning over 200 motion categories across 6 major classes. We release HY-Motion 1.0 to the open-source community to foster future research and accelerate the transition of 3D human motion generation models towards commercial maturity.
ST-ReP: Learning Predictive Representations Efficiently for Spatial-Temporal Forecasting
Dec 19, 2024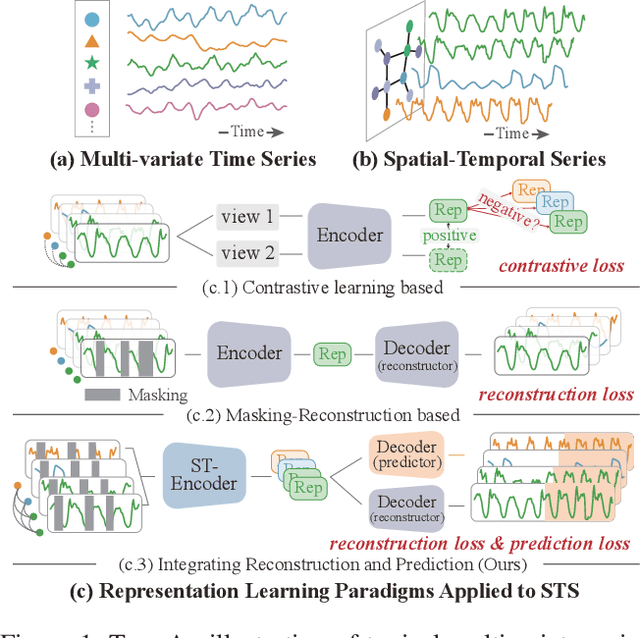
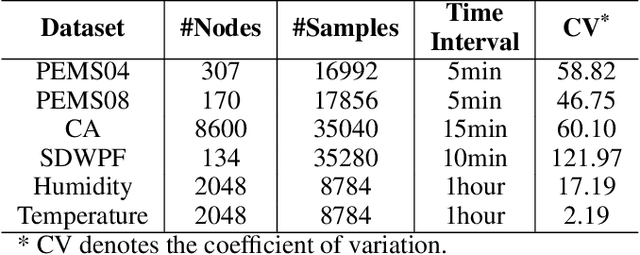
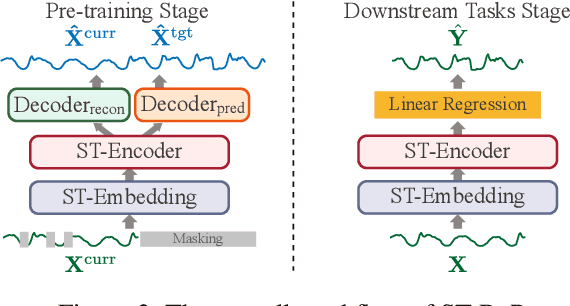
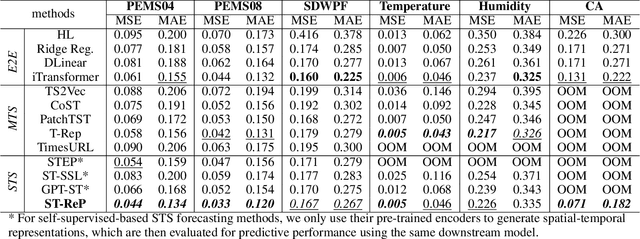
Spatial-temporal forecasting is crucial and widely applicable in various domains such as traffic, energy, and climate. Benefiting from the abundance of unlabeled spatial-temporal data, self-supervised methods are increasingly adapted to learn spatial-temporal representations. However, it encounters three key challenges: 1) the difficulty in selecting reliable negative pairs due to the homogeneity of variables, hindering contrastive learning methods; 2) overlooking spatial correlations across variables over time; 3) limitations of efficiency and scalability in existing self-supervised learning methods. To tackle these, we propose a lightweight representation-learning model ST-ReP, integrating current value reconstruction and future value prediction into the pre-training framework for spatial-temporal forecasting. And we design a new spatial-temporal encoder to model fine-grained relationships. Moreover, multi-time scale analysis is incorporated into the self-supervised loss to enhance predictive capability. Experimental results across diverse domains demonstrate that the proposed model surpasses pre-training-based baselines, showcasing its ability to learn compact and semantically enriched representations while exhibiting superior scalability.
DTBS: Dual-Teacher Bi-directional Self-training for Domain Adaptation in Nighttime Semantic Segmentation
Jan 02, 2024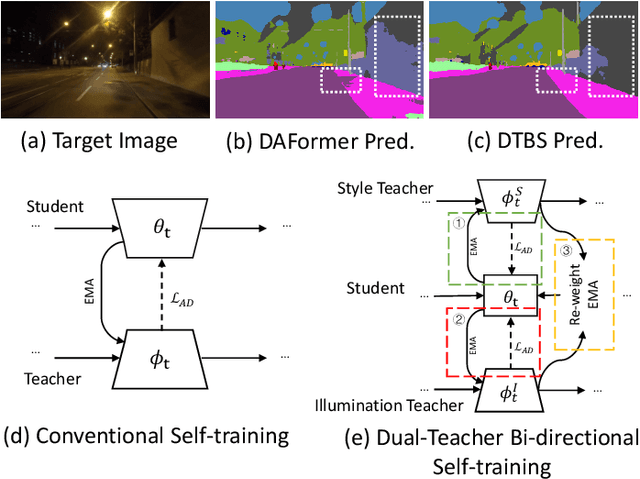
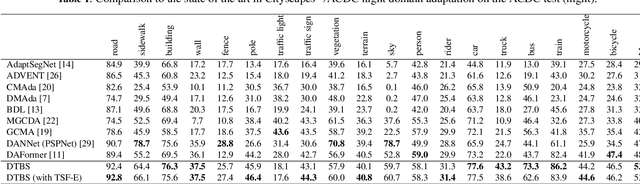
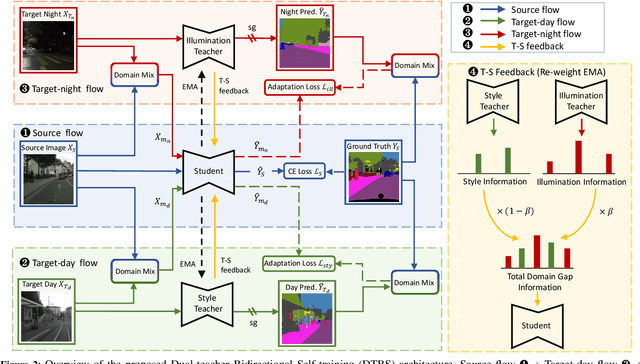
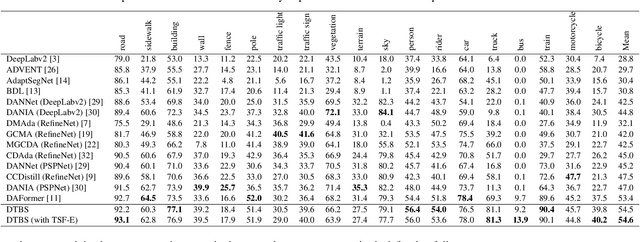
Due to the poor illumination and the difficulty in annotating, nighttime conditions pose a significant challenge for autonomous vehicle perception systems. Unsupervised domain adaptation (UDA) has been widely applied to semantic segmentation on such images to adapt models from normal conditions to target nighttime-condition domains. Self-training (ST) is a paradigm in UDA, where a momentum teacher is utilized for pseudo-label prediction, but a confirmation bias issue exists. Because the one-directional knowledge transfer from a single teacher is insufficient to adapt to a large domain shift. To mitigate this issue, we propose to alleviate domain gap by incrementally considering style influence and illumination change. Therefore, we introduce a one-stage Dual-Teacher Bi-directional Self-training (DTBS) framework for smooth knowledge transfer and feedback. Based on two teacher models, we present a novel pipeline to respectively decouple style and illumination shift. In addition, we propose a new Re-weight exponential moving average (EMA) to merge the knowledge of style and illumination factors, and provide feedback to the student model. In this way, our method can be embedded in other UDA methods to enhance their performance. For example, the Cityscapes to ACDC night task yielded 53.8 mIoU (\%), which corresponds to an improvement of +5\% over the previous state-of-the-art. The code is available at \url{https://github.com/hf618/DTBS}.