 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPR: Towards a Generative Pre-trained One-Model Paradigm for Large-Scale Advertising Recommendation
Nov 13, 2025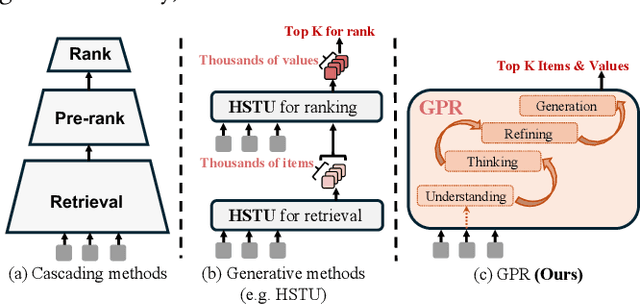
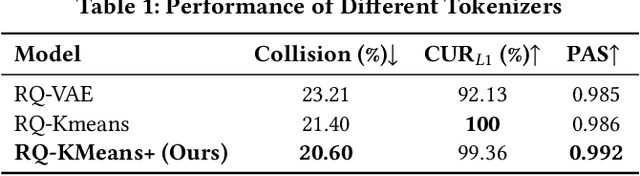
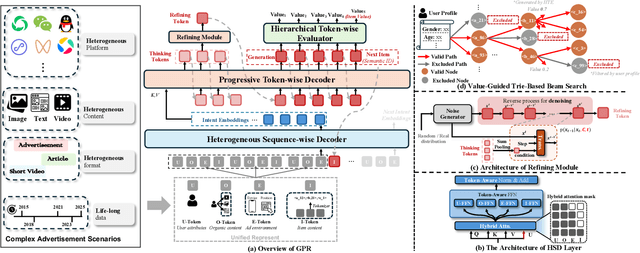
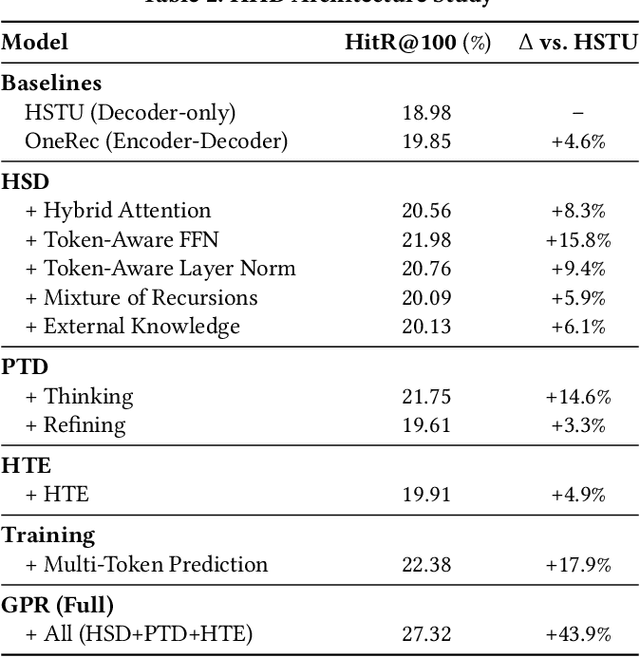
As an intelligent infrastructure connecting users with commercial content, advertising recommendation systems play a central role in information flow and value creation within the digital economy. However, existing multi-stage advertising recommendation systems suffer from objective misalignment and error propagation, making it difficult to achieve global optimality, while unified generative recommendation models still struggle to meet the demands of practical industrial applications. To address these issues, we propose GPR (Generative Pre-trained Recommender), the first one-model framework that redefines advertising recommendation as an end-to-end generative task, replacing the traditional cascading paradigm with a unified generative approach. To realize GPR, we introduce three key innovations spanning unified representation, network architecture, and training strategy. First, we design a unified input schema and tokenization method tailored to advertising scenarios, mapping both ads and organic content into a shared multi-level semantic ID space, thereby enhancing semantic alignment and modeling consistency across heterogeneous data. Second, we develop the Heterogeneous Hierarchical Decoder (HHD), a dual-decoder architecture that decouples user intent modeling from ad generation, achieving a balance between training efficiency and inference flexibility while maintaining strong modeling capacity. Finally, we propose a multi-stage joint training strategy that integrates Multi-Token Prediction (MTP), Value-Aware Fine-Tuning and the Hierarchy Enhanced Policy Optimization (HEPO) algorithm, forming a complete generative recommendation pipeline that unifies interest modeling, value alignment, and policy optimization. GPR has been fully deployed in the Tencent Weixin Channels advertising system, delivering significant improvements in key business metrics including GMV and CTCVR.
MG-HGNN: A Heterogeneous GNN Framework for Indoor Wi-Fi Fingerprint-Based Localization
Nov 10, 2025Received signal strength indicator (RSSI) is the primary representation of Wi-Fi fingerprints and serves as a crucial tool for indoor localization. However, existing RSSI-based positioning methods often suffer from reduced accuracy due to environmental complexity and challenges in processing multi-source information. To address these issues, we propose a novel multi-graph heterogeneous GNN framework (MG-HGNN) to enhance spatial awareness and improve positioning performance. In this framework, two graph construction branches perform node and edge embedding, respectively, to generate informative graphs. Subsequently, a heterogeneous graph neural network is employed for graph representation learning, enabling accurate positioning. The MG-HGNN framework introduces the following key innovations: 1) multi-type task-directed graph construction that combines label estimation and feature encoding for richer graph information; 2) a heterogeneous GNN structure that enhances the performance of conventional GNN models. Evaluations on the UJIIndoorLoc and UTSIndoorLoc public datasets demonstrate that MG-HGNN not only achieves superior performance compared to several state-of-the-art methods, but also provides a novel perspective for enhancing GNN-based localization methods. Ablation studies further confirm the rationality and effectiveness of the proposed framework.
A QoE-Aware Split Inference Accelerating Algorithm for NOMA-based Edge Intelligence
Sep 25, 2024
Even the AI has been widely used and significantly changed our life, deploying the large AI models on resource limited edge devices directly is not appropriate. Thus, the model split inference is proposed to improve the performance of edge intelligence, in which the AI model is divided into different sub models and the resource-intensive sub model is offloaded to edge server wirelessly for reducing resource requirements and inference latency. However, the previous works mainly concentrate on improving and optimizing the system QoS, ignore the effect of QoE which is another critical item for the users except for QoS. Even the QoE has been widely learned in EC, considering the differences between task offloading in EC and split inference in EI, and the specific issues in QoE which are still not addressed in EC and EI, these algorithms cannot work effectively in edge split inference scenarios. Thus, an effective resource allocation algorithm is proposed in this paper, for accelerating split inference in EI and achieving the tradeoff between inference delay, QoE, and resource consumption, abbreviated as ERA. Specifically, the ERA takes the resource consumption, QoE, and inference latency into account to find the optimal model split strategy and resource allocation strategy. Since the minimum inference delay and resource consumption, and maximum QoE cannot be satisfied simultaneously, the gradient descent based algorithm is adopted to find the optimal tradeoff between them. Moreover, the loop iteration GD approach is developed to reduce the complexity of the GD algorithm caused by parameter discretization. Additionally, the properties of the proposed algorithms are investigated, including convergence, complexity, and approximation error. The experimental results demonstrate that the performance of ERA is much better than that of the previous studies.