 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Coarse-to-Fine Evaluation of Inference Efficiency for Large Language Models
Apr 17, 2024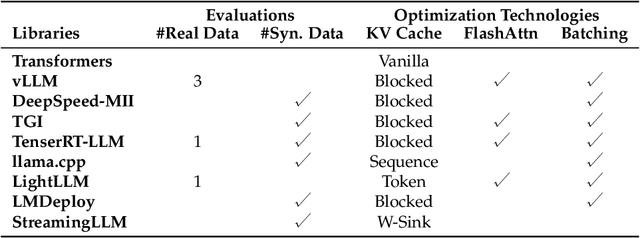
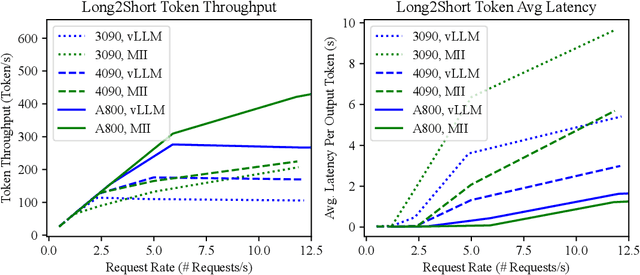
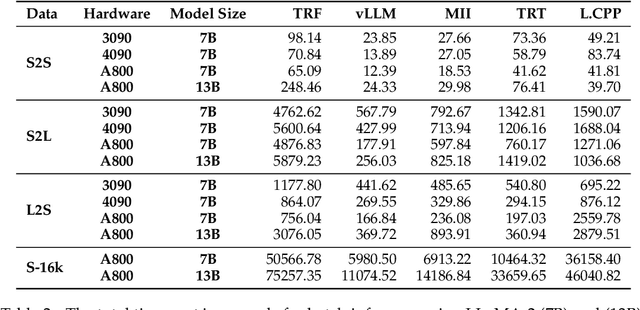
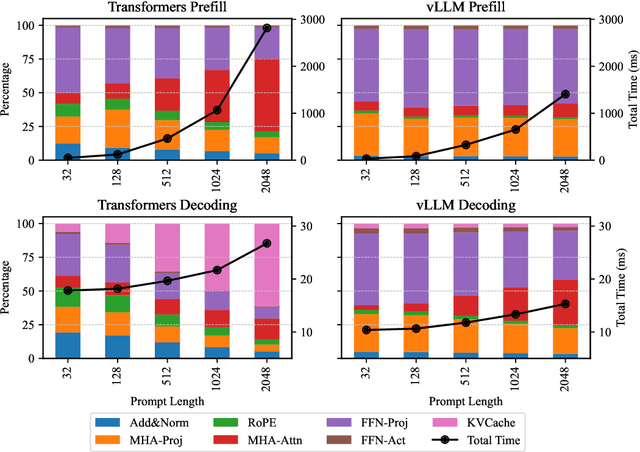
In real world, large language models (LLMs) can serve as the assistant to help users accomplish their jobs, and also support the development of advanced applications. For the wide application of LLMs, the inference efficiency is an essential concern, which has been widely studied in existing work, and numerous optimization algorithms and code libraries have been proposed to improve it. Nonetheless, users still find it challenging to compare the effectiveness of all the above methods and understand the underlying mechanisms. In this work, we perform a detailed coarse-to-fine analysis of the inference performance of various code libraries. To evaluate the overall effectiveness, we examine four usage scenarios within two practical applications. We further provide both theoretical and empirical fine-grained analyses of each module in the Transformer architecture. Our experiments yield comprehensive results that are invaluable for researchers to evaluate code libraries and improve inference strategies.