 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 Image Shadow Removal Challenge Report
Jun 18, 2025



This work examines the findings of the NTIRE 2025 Shadow Removal Challenge. A total of 306 participants have registered, with 17 teams successfully submitting their solutions during the final evaluation phase. Following the last two editions, this challenge had two evaluation tracks: one focusing on reconstruction fidelity and the other on visual perception through a user study. Both tracks were evaluated with images from the WSRD+ dataset, simulating interactions between self- and cast-shadows with a large number of diverse objects, textures, and materials.
GAS: Generative Activation-Aided Asynchronous Split Federated Learning
Sep 02, 2024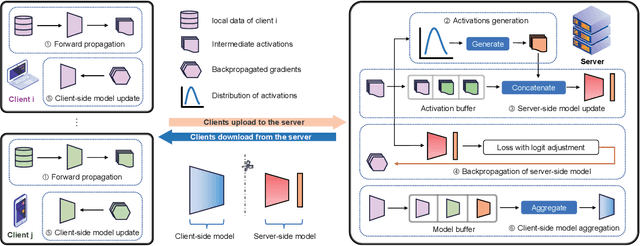

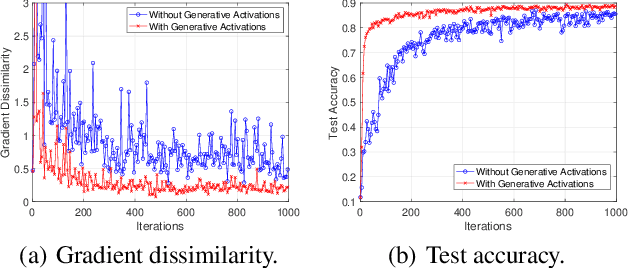

Split Federated Learning (SFL) splits and collaboratively trains a shared model between clients and server, where clients transmit activations and client-side models to server for updates. Recent SFL studies assume synchronous transmission of activations and client-side models from clients to server. However, due to significant variations in computational and communication capabilities among clients, activations and client-side models arrive at server asynchronously. The delay caused by asynchrony significantly degrades the performance of SFL. To address this issue, we consider an asynchronous SFL framework, where an activation buffer and a model buffer are embedded on the server to manage the asynchronously transmitted activations and client-side models, respectively. Furthermore, as asynchronous activation transmissions cause the buffer to frequently receive activations from resource-rich clients, leading to biased updates of the server-side model, we propose Generative activations-aided Asynchronous SFL (GAS). In GAS, the server maintains an activation distribution for each label based on received activations and generates activations from these distributions according to the degree of bias. These generative activations are then used to assist in updating the server-side model, ensuring more accurate updates. We derive a tighter convergence bound, and our experiments demonstrate the effectiveness of the proposed method.
SCALA: Split Federated Learning with Concatenated Activations and Logit Adjustments
May 08, 2024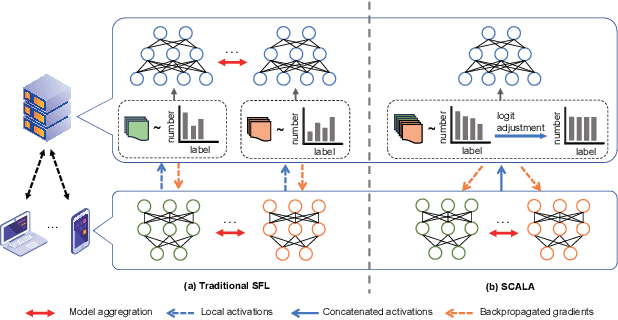
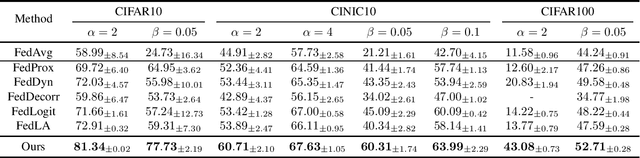
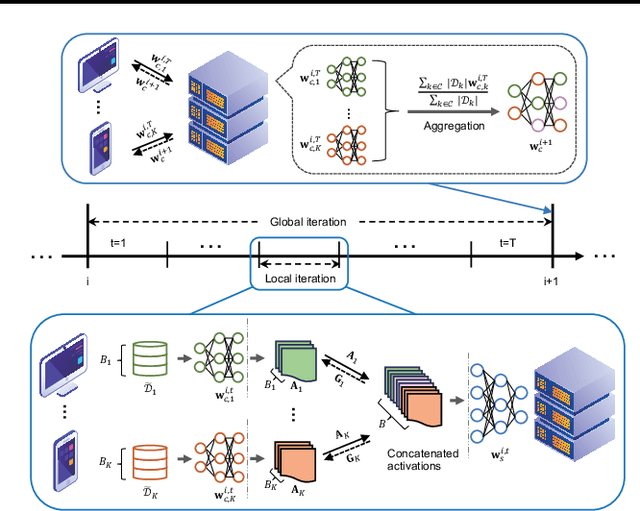
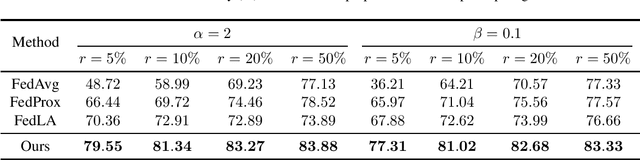
Split Federated Learning (SFL) is a distributed machine learning framework which strategically divides the learning process between a server and clients and collaboratively trains a shared model by aggregating local models updated based on data from distributed clients. However, data heterogeneity and partial client participation result in label distribution skew, which severely degrades the learning performance. To address this issue, we propose SFL with Concatenated Activations and Logit Adjustments (SCALA). Specifically, the activations from the client-side models are concatenated as the input of the server-side model so as to centrally adjust label distribution across different clients, and logit adjustments of loss functions on both server-side and client-side models are performed to deal with the label distribution variation across different subsets of participating clients. Theoretical analysis and experimental results verify the superiority of the proposed SCALA on public datasets.
Asynchronous Wireless Federated Learning with Probabilistic Client Selection
Nov 28, 2023



Federated learning (FL) is a promising distributed learning framework where distributed clients collaboratively train a machine learning model coordinated by a server. To tackle the stragglers issue in asynchronous FL, we consider that each client keeps local updates and probabilistically transmits the local model to the server at arbitrary times. We first derive the (approximate) expression for the convergence rate based on the probabilistic client selection. Then, an optimization problem is formulated to trade off the convergence rate of asynchronous FL and mobile energy consumption by joint probabilistic client selection and bandwidth allocation. We develop an iterative algorithm to solve the non-convex problem globally optimally. Experiments demonstrate the superiority of the proposed approach compared with the traditional schemes.
Towards Effective Ancient Chinese Translation: Dataset, Model, and Evaluation
Aug 01, 2023
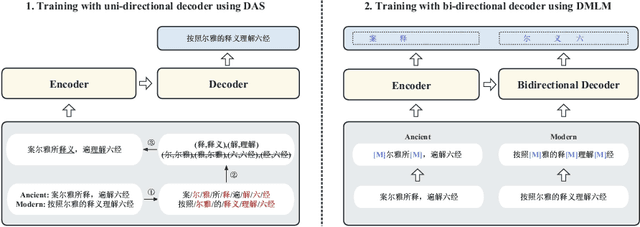


Interpreting ancient Chinese has been the key to comprehending vast Chinese literature, tradition, and civilization. In this paper, we propose Erya for ancient Chinese translation. From a dataset perspective, we collect, clean, and classify ancient Chinese materials from various sources, forming the most extensive ancient Chinese resource to date. From a model perspective, we devise Erya training method oriented towards ancient Chinese. We design two jointly-working tasks: disyllabic aligned substitution (DAS) and dual masked language model (DMLM). From an evaluation perspective, we build a benchmark to judge ancient Chinese translation quality in different scenarios and evaluate the ancient Chinese translation capacities of various existing models. Our model exhibits remarkable zero-shot performance across five domains, with over +12.0 BLEU against GPT-3.5 models and better human evaluation results than ERNIE Bot. Subsequent fine-tuning further shows the superior transfer capability of Erya model with +6.2 BLEU gain. We release all the above-mentioned resources at https://github.com/RUCAIBox/Erya.
Client Selection for Federated Bayesian Learning
Dec 11, 2022



Distributed Stein Variational Gradient Descent (DSVGD) is a non-parametric distributed learning framework for federated Bayesian learning, where multiple clients jointly train a machine learning model by communicating a number of non-random and interacting particles with the server. Since communication resources are limited, selecting the clients with most informative local learning updates can improve the model convergence and communication efficiency. In this paper, we propose two selection schemes for DSVGD based on Kernelized Stein Discrepancy (KSD) and Hilbert Inner Product (HIP). We derive the upper bound on the decrease of the global free energy per iteration for both schemes, which is then minimized to speed up the model convergence. We evaluate and compare our schemes with conventional schemes in terms of model accuracy, convergence speed, and stability using various learning tasks and datasets.