 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClient Selection for Federated Bayesian Learning
Dec 11, 2022



Distributed Stein Variational Gradient Descent (DSVGD) is a non-parametric distributed learning framework for federated Bayesian learning, where multiple clients jointly train a machine learning model by communicating a number of non-random and interacting particles with the server. Since communication resources are limited, selecting the clients with most informative local learning updates can improve the model convergence and communication efficiency. In this paper, we propose two selection schemes for DSVGD based on Kernelized Stein Discrepancy (KSD) and Hilbert Inner Product (HIP). We derive the upper bound on the decrease of the global free energy per iteration for both schemes, which is then minimized to speed up the model convergence. We evaluate and compare our schemes with conventional schemes in terms of model accuracy, convergence speed, and stability using various learning tasks and datasets.
Forget-SVGD: Particle-Based Bayesian Federated Unlearning
Nov 23, 2021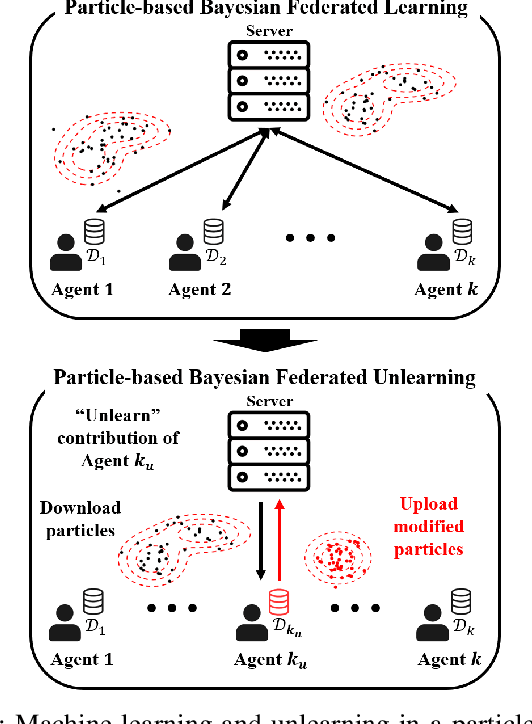
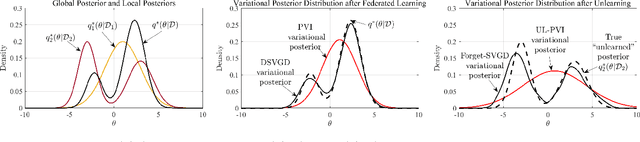
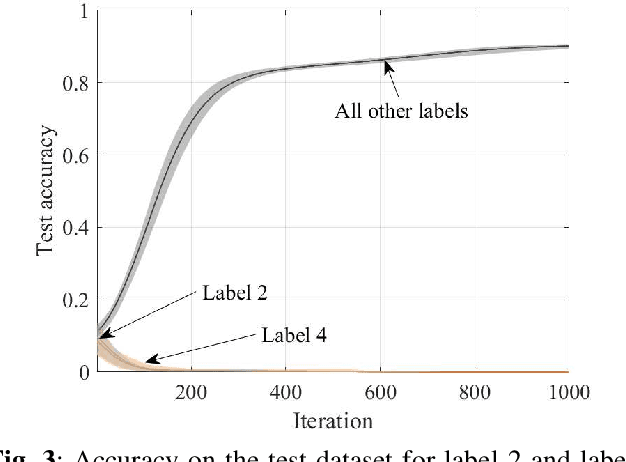
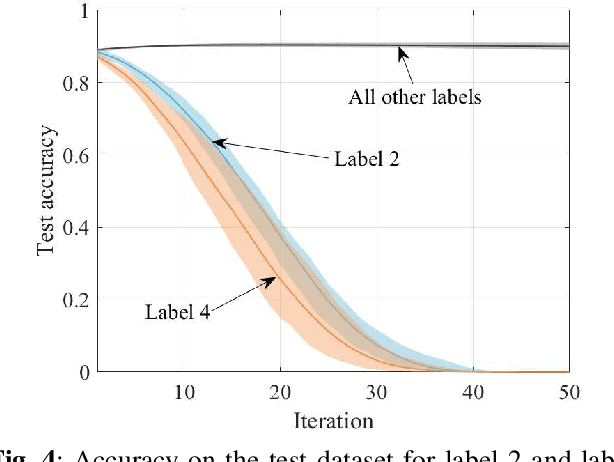
Variational particle-based Bayesian learning methods have the advantage of not being limited by the bias affecting more conventional parametric techniques. This paper proposes to leverage the flexibility of non-parametric Bayesian approximate inference to develop a novel Bayesian federated unlearning method, referred to as Forget-Stein Variational Gradient Descent (Forget-SVGD). Forget-SVGD builds on SVGD - a particle-based approximate Bayesian inference scheme using gradient-based deterministic updates - and on its distributed (federated) extension known as Distributed SVGD (DSVGD). Upon the completion of federated learning, as one or more participating agents request for their data to be "forgotten", Forget-SVGD carries out local SVGD updates at the agents whose data need to be "unlearned", which are interleaved with communication rounds with a parameter server. The proposed method is validated via performance comparisons with non-parametric schemes that train from scratch by excluding data to be forgotten, as well as with existing parametric Bayesian unlearning methods.
Federated Generalized Bayesian Learning via Distributed Stein Variational Gradient Descent
Oct 04, 2020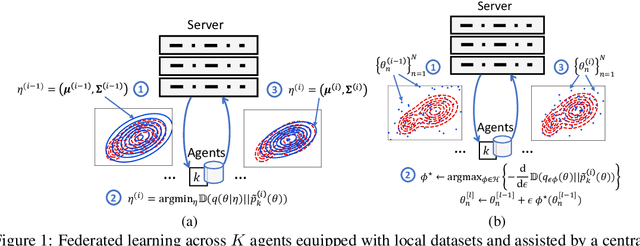
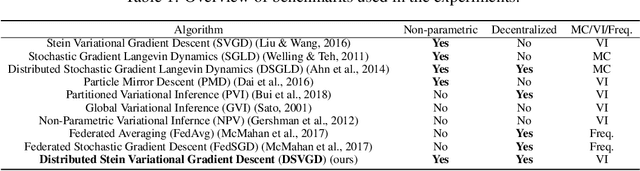

This paper introduces Distributed Stein Variational Gradient Descent (DSVGD), a non-parametric generalized Bayesian inference framework for federated learning. DSVGD maintains a number of non-random and interacting particles at a central server to represent the current iterate of the model global posterior. The particles are iteratively downloaded and updated by one of the agents with the end goal of minimizing the global free energy. By varying the number of particles, DSVGD enables a flexible trade-off between per-iteration communication load and number of communication rounds. DSVGD is shown to compare favorably to benchmark frequentist and Bayesian federated learning strategies, also scheduling a single device per iteration, in terms of accuracy and scalability with respect to the number of agents, while also providing well-calibrated, and hence trustworthy, predictions.