 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLength-Adaptive Interest Network for Balancing Long and Short Sequence Modeling in CTR Prediction
Jan 27, 2026User behavior sequences in modern recommendation systems exhibit significant length heterogeneity, ranging from sparse short-term interactions to rich long-term histories. While longer sequences provide more context, we observe that increasing the maximum input sequence length in existing CTR models paradoxically degrades performance for short-sequence users due to attention polarization and length imbalance in training data. To address this, we propose LAIN(Length-Adaptive Interest Network), a plug-and-play framework that explicitly incorporates sequence length as a conditioning signal to balance long- and short-sequence modeling. LAIN consists of three lightweight components: a Spectral Length Encoder that maps length into continuous representations, Length-Conditioned Prompting that injects global contextual cues into both long- and short-term behavior branches, and Length-Modulated Attention that adaptively adjusts attention sharpness based on sequence length. Extensive experiments on three real-world benchmarks across five strong CTR backbones show that LAIN consistently improves overall performance, achieving up to 1.15% AUC gain and 2.25% log loss reduction. Notably, our method significantly improves accuracy for short-sequence users without sacrificing longsequence effectiveness. Our work offers a general, efficient, and deployable solution to mitigate length-induced bias in sequential recommendation.
Towards Effective Ancient Chinese Translation: Dataset, Model, and Evaluation
Aug 01, 2023
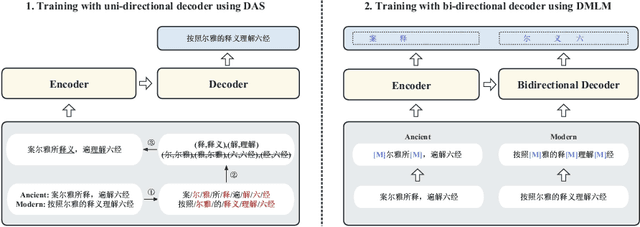


Interpreting ancient Chinese has been the key to comprehending vast Chinese literature, tradition, and civilization. In this paper, we propose Erya for ancient Chinese translation. From a dataset perspective, we collect, clean, and classify ancient Chinese materials from various sources, forming the most extensive ancient Chinese resource to date. From a model perspective, we devise Erya training method oriented towards ancient Chinese. We design two jointly-working tasks: disyllabic aligned substitution (DAS) and dual masked language model (DMLM). From an evaluation perspective, we build a benchmark to judge ancient Chinese translation quality in different scenarios and evaluate the ancient Chinese translation capacities of various existing models. Our model exhibits remarkable zero-shot performance across five domains, with over +12.0 BLEU against GPT-3.5 models and better human evaluation results than ERNIE Bot. Subsequent fine-tuning further shows the superior transfer capability of Erya model with +6.2 BLEU gain. We release all the above-mentioned resources at https://github.com/RUCAIBox/Erya.