 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIaM: Self-Improving Code-Assisted Mathematical Reasoning of Large Language Models
Paper and Code
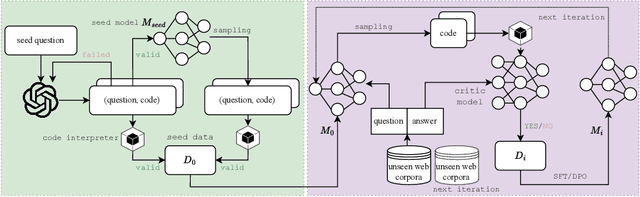

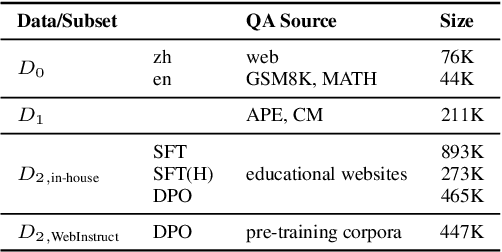
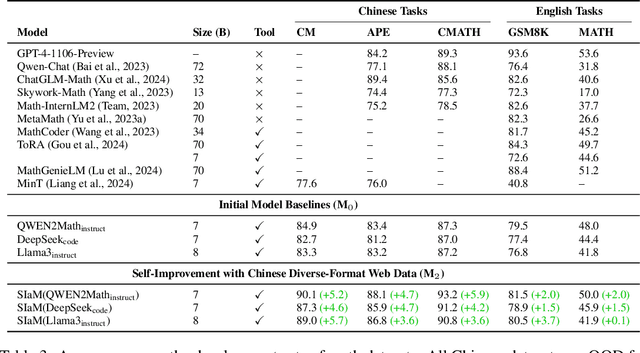
There is a growing trend of teaching large language models (LLMs) to solve mathematical problems through coding. Existing studies primarily focus on prompting powerful, closed-source models to generate seed training data followed by in-domain data augmentation, equipping LLMs with considerable capabilities for code-aided mathematical reasoning. However, continually training these models on augmented data derived from a few datasets such as GSM8K may impair their generalization abilities and restrict their effectiveness to a narrow range of question types. Conversely, the potential of improving such LLMs by leveraging large-scale, expert-written, diverse math question-answer pairs remains unexplored. To utilize these resources and tackle unique challenges such as code response assessment, we propose a novel paradigm that uses a code-based critic model to guide steps including question-code data construction, quality control, and complementary evaluation. We also explore different alignment algorithms with self-generated instruction/preference data to foster continuous improvement. Experiments across both in-domain (up to +5.7%) and out-of-domain (+4.4%) benchmarks in English and Chinese demonstrate the effectiveness of the proposed paradigm.